SD XL - v1.0
ハイライトされた画像












推奨パラメータ
resolution
ヒント
このモデルは研究目的(アートワーク生成、教育ツール、セーフティ運用を含む)での使用を意図しています。
人物や出来事の事実的または真実の描写を生成する目的ではありません。
制限としては、完璧なフォトリアリズムを達成していないこと、読みやすいテキストの描画不可、構成的プロンプトの課題、顔の不適切な生成の可能性があります。
モデルは2つの事前学習済みテキストエンコーダー、OpenCLIP-ViT/GとCLIP-ViT/Lを使用しています。
2段階のパイプラインは、ベース潜在生成とSDEdit(img2img)を用いた高解像度補正で構成されています。
クリエイタースポンサー
元々はHugging Faceに投稿され、Stability AIの許可を得てここに共有されています。
元々はHugging Faceに投稿され、Stability AIの許可を得てここに共有されています。
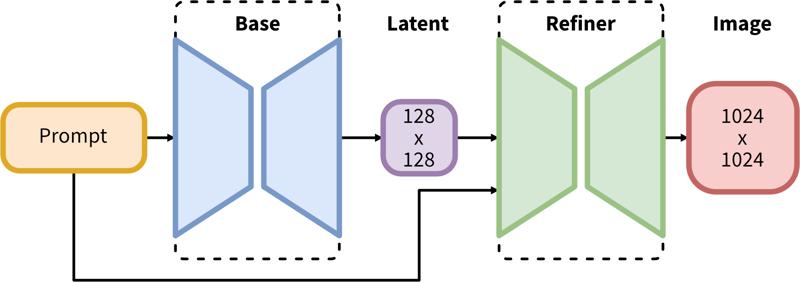
SDXLは潜在拡散のための2段階のパイプラインで構成されています。最初に、ベースモデルを使用して望ましい出力サイズの潜在空間を生成します。第二段階では、高解像度専用モデルを用い、同じプロンプトを使って最初の段階で生成された潜在空間に対しSDEdit(別名「img2img」)(https://arxiv.org/abs/2108.01073)という手法を適用します。
モデルの説明
開発者: Stability AI
モデルタイプ: 拡散ベースのテキストから画像生成モデル
モデル説明: テキストプロンプトに基づいて画像を生成および修正できるモデルです。これは潜在拡散モデルであり、2つの固定済みの事前学習テキストエンコーダー(OpenCLIP-ViT/GおよびCLIP-ViT/L)を使用しています。
詳細情報のリソース: GitHubリポジトリ。
モデルソース
用途
直接利用
このモデルは研究目的向けです。可能な研究分野やタスクには以下が含まれます。
アートワークの生成およびデザインやその他の芸術的プロセスでの利用。
教育ツールやクリエイティブツールでの応用。
生成モデルの研究。
有害コンテンツを生成する可能性のあるモデルの安全な運用。
生成モデルの制限やバイアスの調査および理解。
除外される使用例については以下に記述します。
範囲外の使用
このモデルは人や出来事の事実的・真実な表現を目的に訓練されていないため、そのようなコンテンツ生成には適していません。
制限事項とバイアス
制限事項
完璧なフォトリアリズムは達成していません。
読みやすいテキストの描画はできません。
「青い球の上に赤い立方体」といった構成的な描写には課題があります。
顔や人の生成が正確でない場合があります。
モデルの自己符号化部分は情報損失があります。
バイアス
画像生成モデルの能力は優れていますが、社会的バイアスを強化・悪化させる可能性があります。
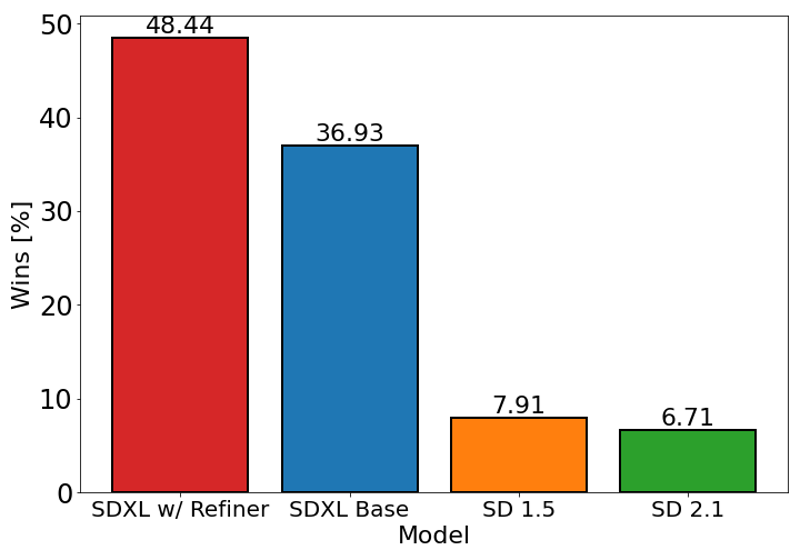
上のチャートはSDXL(補正あり・なし)に対するユーザーの好みをStable Diffusion 1.5および2.1と比較したものです。SDXLのベースモデルは前のバリアントよりも大幅に良好な結果を示し、補正モジュールと組み合わせたモデルが全体的に最高の性能を達成しています。

モデルコレクション - SD XL

「SD XL - v1.0」による画像
基本モデル画像

sdxl画像



stability ai画像



