SD XL - v1.0 VAE修正
ハイライトされた画像












推奨ネガティブプロンプト
(deformed iris, deformed pupils), text, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, (extra fingers), (mutated hands), poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, (fused fingers), (too many fingers), long neck, camera
推奨パラメータ
samplers
steps
cfg
resolution
ヒント
このモデルは、アートワーク生成、教育ツール、安全な展開を含む研究目的で設計されています。
人物や事象の事実的または真実の描写を生成する目的ではありません。
制限には、不完全なフォトリアリズム、読みやすいテキストを生成できないこと、構成的なプロンプトに対する困難、顔の不適切な生成の可能性が含まれます。
モデルは2つの事前学習済みテキストエンコーダー:OpenCLIP-ViT/GとCLIP-ViT/Lを使用しています。
二段階のパイプラインは、まずベースの潜在変数生成を行い、その後SDEdit(img2img)を用いた高解像度リファインメントを行います。
クリエイタースポンサー
元々はHugging Faceに掲載され、Stability AIの許可を得てここに共有されています。
元々はHugging Faceに掲載され、Stability AIの許可を得てここに共有されています。
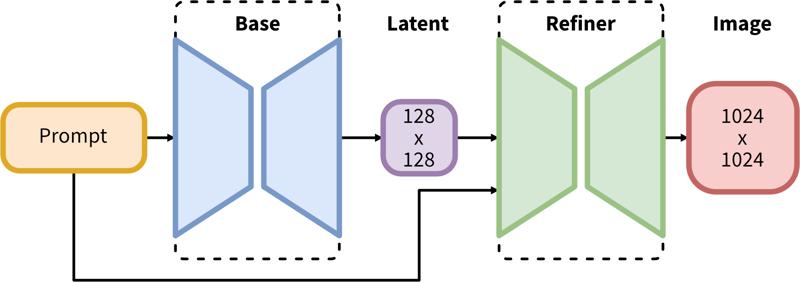
SDXLは潜在拡散の二段階パイプラインで構成されています。まずベースモデルを使用して目的の出力サイズの潜在変数を生成します。次に、専門的な高解像度モデルを使い、同じプロンプトを用いてSDEdit(https://arxiv.org/abs/2108.01073、別名「img2img」)と呼ばれる技術を潜在変数に適用します。
モデルの説明
開発元:Stability AI
モデルタイプ:拡散ベースのテキストから画像生成モデル
モデル説明:これはテキストプロンプトに基づいて画像を生成・変更できるモデルです。二つの固定済みの事前学習テキストエンコーダー(OpenCLIP-ViT/GとCLIP-ViT/L)を使用するLatent Diffusion Modelです。
詳細情報のリソース: GitHubリポジトリ。
モデルソース
デモ【オプション】: https://clipdrop.co/stable-diffusion
利用用途
直接利用
このモデルは研究目的のみに意図されています。可能な研究分野およびタスクには以下が含まれます。
アート作品の生成およびデザインやその他の芸術的プロセスにおける利用。
教育または創造的ツールでの応用。
生成モデルに関する研究。
有害なコンテンツを生成する可能性のあるモデルの安全な展開。
生成モデルの限界やバイアスの調査と理解。
除外される利用は以下に記述しています。
スコープ外の利用
このモデルは人や事象の正確な事実的表現を生成するようには訓練されていません。そのため、そのような内容の生成はこのモデルの範囲外です。
制限とバイアス
制限
モデルは完璧なフォトリアリズムを達成しません。
モデルは判読可能なテキストを生成できません。
「青い球の上に赤い立方体」のような構成的な要求を伴うより難しいタスクでは苦戦します。
顔や人間の生成は必ずしも正確ではない場合があります。
モデルのオートエンコーディング部分はロスが発生します。
バイアス
画像生成モデルの能力は印象的ですが、社会的バイアスを強化または悪化させる可能性もあります。
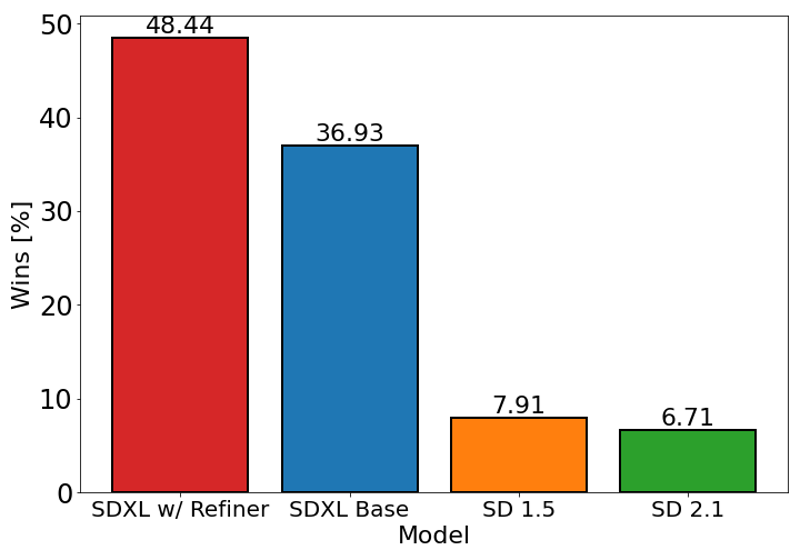
上記のグラフは、Stable Diffusion 1.5および2.1に対するSDXL(リファインメントあり・なし両方)のユーザープリファレンスを評価しています。SDXLベースモデルは過去のバリアントよりも大幅に優れており、リファインメントモジュールと組み合わせたモデルが最高のパフォーマンスを達成しています。











