Stable Cascade - ベース
ハイライトされた画像


推奨パラメータ
steps
resolution
ヒント
Stage Cの36億パラメータ版を使用すると、主なファインチューニングが行われているため最良の結果が得られます。
Stage Bでは15億パラメータ版を使用すると、小さく細かいディテールの再現に優れています。
潜在空間が小さいため効率的なトレーニングと推論に適しており、ファインチューニング、LoRA、ControlNet、IP-Adapter、LCMなどの拡張をサポートします。
本モデルは研究目的のみに使用し、事実的表現の生成やStability AIの許容使用ポリシーに違反する用途には使用しないでください。
顔や人物は正しく生成されない場合があり、モデルの自己符号化は損失を伴います。
クリエイタースポンサー
デモ:
- multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
- ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
デモ:
multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Stable Cascade
このモデルはWürstchenアーキテクチャを基に構築されており、Stable Diffusionのような他のモデルとの主な違いははるかに小さい潜在空間で動作することです。
なぜこれが重要なのか?潜在空間が小さいほど、推論が速くなり、トレーニングコストが安くなります。
潜在空間はどれほど小さいのか?Stable Diffusionは圧縮率が8で、1024x1024の画像を128x128にエンコードします。Stable Cascadeは圧縮率42を実現し、1024x1024の画像を24x24に圧縮しつつ鮮明な復元が可能です。テキスト条件付きモデルはこの高度に圧縮された潜在空間でトレーニングされます。以前のこのアーキテクチャバージョンはStable Diffusion 1.5に比べコストを16分の1に削減しました。 <br> <br>
したがって、このモデルは効率性が重要な用途に適しています。さらに、ファインチューニング、LoRA、ControlNet、IP-Adapter、LCMなどの既知の拡張もこの方法で利用可能です。
モデル詳細
モデル説明
Stable Cascadeはテキストプロンプトに基づき画像を生成する拡散モデルです。
開発: Stability AI
資金提供: Stability AI
モデルタイプ: テキストから画像生成の生成モデル
モデルソース
研究目的には弊社のStableCascade Githubリポジトリ(https://github.com/Stability-AI/StableCascade)をお勧めします。
モデル概要
Stable Cascadeは3つのモデル、Stage A、Stage B、Stage Cで構成され、カスケード方式で画像を生成するため、この名前が付けられています。
Stage AとBは画像圧縮に用いられ、Stable DiffusionのVAEに相当する役割を果たします。
この構成により、より高い圧縮率が可能です。Stable Diffusionが空間圧縮率8で1024 x 1024を128 x 128へエンコードするのに対し、Stable Cascadeは圧縮率42で1024 x 1024を24 x 24にエンコードし、正確なデコードが可能です。
これによりトレーニングと推論コストが大幅に削減されます。Stage Cはテキストプロンプトに基づいて24 x 24の潜在表現を生成します。以下の画像はこれを視覚的に示しています。
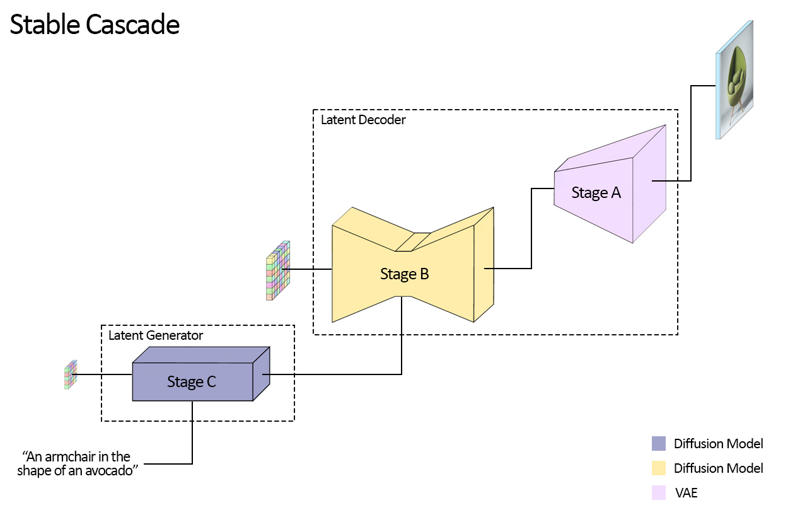
今回のリリースでは、Stage C用に2つ、Stage B用に2つ、Stage A用に1つのチェックポイントを提供します。Stage Cは10億パラメータ版と36億パラメータ版があり、ほとんどのファインチューニングが36億版で行われているため、そちらの使用を強く推奨します。Stage Bは7億と15億パラメータ版があり、どちらも良好な結果を出しますが、15億版は小さい細部の復元に優れています。したがって、それぞれより大きい方のバリアントを使うと最良の結果が得られます。Stage Aは2000万パラメータで小さいため固定されています。
評価
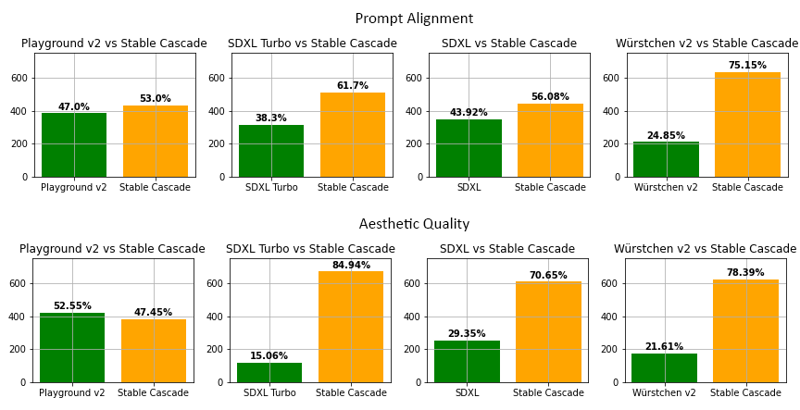
評価によれば、Stable Cascadeはほとんどの比較においてプロンプト適合度と美的品質の両方で最高のパフォーマンスを示します。上の画像は、人間評価による結果で、parti-prompts(リンク)と美的プロンプトの組み合わせで実施されました。具体的には、Stable Cascade(推論ステップ30)がPlayground v2(推論ステップ50)、SDXL(推論ステップ50)、SDXL Turbo(推論ステップ1)、Würstchen v2(推論ステップ30)と比較されました。
コード例
⚠️ 重要: 以下のコードを動作させるには、PRが作業中のこのブランチから diffusersをインストールする必要があります。
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Anthropomorphic cat dressed as a pilot"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
# Now decoder_output is a list with your PIL images使用例
直接使用
このモデルは今のところ研究目的向けです。可能な研究分野・課題には以下が含まれます。
生成モデルの研究。
有害コンテンツ生成の可能性があるモデルの安全な運用。
生成モデルの制限やバイアスの調査と理解。
アートワークの生成およびデザインやその他の芸術的プロセスへの応用。
教育的または創造的なツールでの応用。
除外される用途については下記を参照してください。
対象外の使用
本モデルは人や出来事の事実的または真実の表現を目的としてトレーニングされておらず、
そのようなコンテンツの生成に使用することはモデルの能力の範囲外です。
また、モデルはStability AIの許容使用ポリシーに違反する方法での使用は禁止されています。
制限とバイアス
制限事項
顔や人物は正しく生成されない場合があります。
モデルの自己符号化部分は損失を伴います。
推奨事項
本モデルは研究目的のみに使用してください。
モデルの始め方

モデル詳細
ディスカッション
コメントを残すには log in してください。
モデルコレクション - Stable Cascade
「Stable Cascade - ベース」による画像
アニメ画像










アート画像










基本モデル画像

ロゴ画像










