SD XL - v1.0
관련 키워드 및 태그
하이라이트된 이미지












추천 매개변수
resolution
팁
이 모델은 예술 작품 생성, 교육 도구, 안전 배포 등 연구 목적을 위해 제작되었습니다.
사람이나 사건의 사실적 또는 진실한 묘사를 생성하는 데에는 적합하지 않습니다.
완벽한 포토리얼리즘 미달, 읽을 수 있는 텍스트 불가, 구성적 프롬프트 처리 어려움, 얼굴 생성 문제 등의 한계가 있습니다.
두 개의 사전 학습된 텍스트 인코더인 OpenCLIP-ViT/G와 CLIP-ViT/L을 사용합니다.
2단계 파이프라인은 베이스 잠재 생성과 SDEdit(img2img)를 이용한 고해상도 정제로 구성됩니다.
크리에이터 스폰서
원본은 Hugging Face에 게시되었으며 Stability AI의 허가를 받아 여기서 공유됩니다.
원본은 Hugging Face에 게시되었으며 Stability AI의 허가를 받아 여기서 공유됩니다.
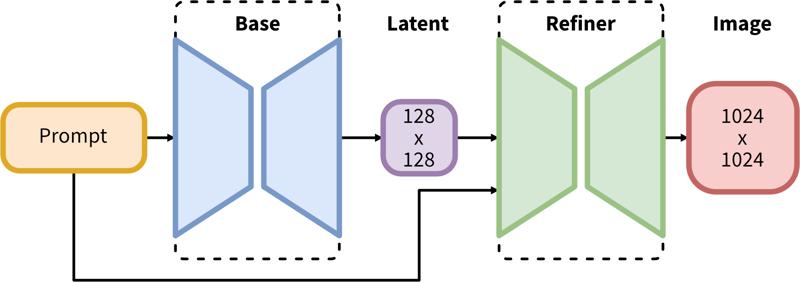
SDXL은 잠재 확산을 위한 2단계 파이프라인으로 구성됩니다: 첫 번째 단계에서는 원하는 출력 크기의 잠재 변수를 생성하는 베이스 모델을 사용합니다. 두 번째 단계에서는 특수 고해상도 모델을 사용하고 SDEdit(https://arxiv.org/abs/2108.01073, "img2img"라고도 불림) 기법을 첫 단계에서 생성된 잠재 변수에 동일한 프롬프트로 적용합니다.
모델 설명
개발: Stability AI
모델 유형: 확산 기반 텍스트-이미지 생성 모델
모델 설명: 텍스트 프롬프트를 기반으로 이미지를 생성 및 수정하는 데 사용되는 모델입니다. 두 개의 고정된 사전 학습된 텍스트 인코더(OpenCLIP-ViT/G 및 CLIP-ViT/L)를 사용하는 Latent Diffusion Model입니다.
추가 정보 자료: GitHub 저장소.
모델 소스
데모 [선택 사항]: https://clipdrop.co/stable-diffusion
용도
직접 사용
이 모델은 연구 목적만을 위해 만들어졌습니다. 가능한 연구 분야 및 작업에는 다음이 포함됩니다:
예술 작품 생성 및 디자인 등 예술적 과정에의 활용.
교육용 또는 창작 도구에서의 응용.
생성 모델에 대한 연구.
유해한 콘텐츠 생성을 방지하는 안전한 모델 배포.
생성 모델의 한계 및 편향 분석 및 이해.
제외되는 사용은 아래에 설명되어 있습니다.
범위 외 사용
이 모델은 사람이나 사건에 대한 사실적 또는 진실한 표현을 생성하도록 훈련되지 않았으므로, 해당 내용을 생성하는 것은 모델의 능력 범위를 벗어납니다.
한계 및 편향
한계
모델은 완벽한 포토리얼리즘을 달성하지 못합니다.
모델은 읽을 수 있는 텍스트를 렌더링할 수 없습니다.
“파란 구 위에 빨간 큐브”와 같은 구성 관련 복잡한 작업에 어려움을 겪습니다.
얼굴 및 사람은 일반적으로 제대로 생성되지 않을 수 있습니다.
모델의 자동 인코딩 부분은 손실이 발생합니다.
편향
이미지 생성 모델의 능력은 인상적이지만, 사회적 편향을 강화하거나 심화할 수도 있습니다.
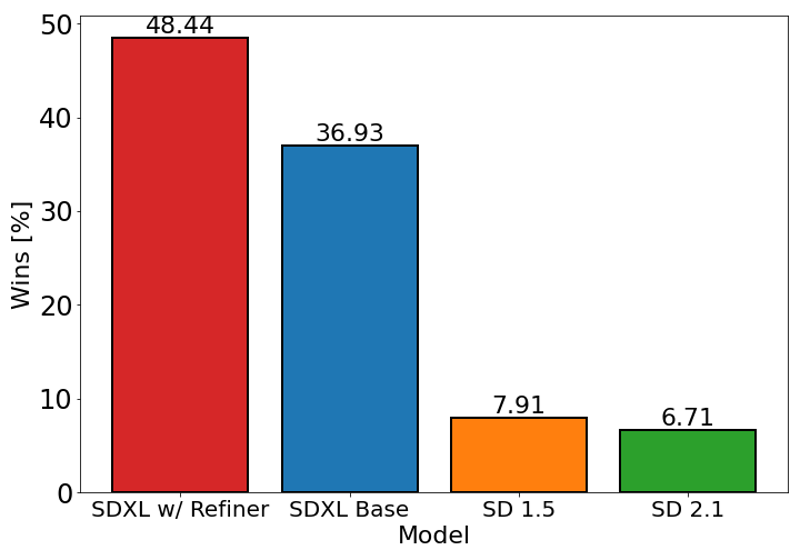
위 차트는 Stable Diffusion 1.5 및 2.1 대비 SDXL(정제 포함 및 비포함)에 대한 사용자 선호도를 평가합니다. SDXL 베이스 모델은 이전 버전에 비해 현저히 우수하며, 정제 모듈과 결합된 모델이 전체적으로 최고의 성능을 달성합니다.

모델 컬렉션 - SD XL


SD XL - v1.0 제작 이미지
기본 모델 이미지

공식 이미지

sdxl 이미지



stability ai 이미지





