Animagine XL 4.0 - v4 Opt
Powiązane słowa kluczowe i tagi
Wyróżnione obrazy





Zalecane podpowiedzi
1girl, firefly (honkai: star rail), honkai (series), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
masterpiece, high score, great score, absurdres
1girl, sensitive, looking at viewer, solo, masterpiece, high score, great score, absurdres
Zalecane negatywne podpowiedzi
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
Zalecane parametry
samplers
steps
cfg
resolution
Wskazówki
Stosuj opisy oparte na tagach z metodą porządkowania tagów dla lepszych efektów: 1girl/1boy/1other, nazwa postaci, seria, rating, inne tagi, następnie poprawa jakości.
Dodaj tagi poprawiające jakość na końcu promptu: masterpiece, high score, great score, absurdres.
Używaj zalecanych negatywnych promptów, aby uniknąć niechcianych artefaktów i błędów.
Optymalna skala CFG to 4-7, zalecana wartość to 5.
Optymalna liczba kroków próbkowania to 25-28, zalecane 28.
Preferowany sampler to Euler Ancestral (Euler a).
Zwróć uwagę na ograniczenia modelu, takie jak trudności z kompleksową anatomią i renderowaniem tekstu.
Najnowsze postacie mogą mieć niższą dokładność z powodu ograniczonych danych treningowych.
Najważniejsze informacje o wersji
Wraz z wydaniem Animagine XL 4.0 Opt (zoptymalizowanej wersji) model został jeszcze bardziej dopracowany z dodatkowym zbiorem danych, co poprawia jego wydajność do ogólnego użytku. Ta aktualizacja przynosi kilka usprawnień:
Lepsza stabilność dla bardziej spójnych wyników
Udoskonalona anatomia z dokładniejszymi proporcjami
Zmniejszenie szumów i artefaktów w generacjach
Naprawiono problemy z niskim nasyceniem, skutkując bogatszymi kolorami
Poprawiona dokładność kolorów dla bardziej atrakcyjnych wizualnie rezultatów
Sponsorzy twórcy
Wspieraj rozwój Animagine XL
- Przekaż darowiznę ETH/USDT na
0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C - GitHub Sponsors: https://github.com/sponsors/cagliostrolab/
- Dołącz do społeczności Discord: https://discord.gg/cqh9tZgbGc
Prosimy o przeczytanie naszego szczegółowego przewodnika dotyczącego promptów na Blogu Cagliostrolab
Przegląd
Animagine XL 4.0, stylizowany także jako Anim4gine, to najwyższej klasy tematyczny model SDXL wyszkolony na anime, najnowsza odsłona serii Animagine XL. Pomimo kontynuacji, model został przeszkolony od podstaw na Stable Diffusion XL 1.0 na ogromnym zbiorze 8,4 mln zróżnicowanych obrazów w stylu anime z różnych źródeł z datą ograniczenia wiedzy do 7 stycznia 2025 oraz dopracowywany przez około 2650 godzin GPU. Podobnie jak poprzednia wersja, model był trenowany z użyciem metody uporządkowania tagów dla tożsamości i stylu.
Wraz z wydaniem Animagine XL 4.0 Opt (Zoptymalizowany), model został dodatkowo ulepszony z dodatkowym zbiorem danych, poprawiając stabilność, dokładność anatomii, redukcję szumów, nasycenie kolorów oraz ogólną dokładność kolorów. Te usprawnienia czynią Animagine XL 4.0 Opt bardziej spójnym i wizualnie atrakcyjnym, jednocześnie zachowując charakterystyczną jakość serii.
Zmiany
- 2025-02-13 – Dodano Animagine XL 4.0 Opt oraz Animagine XL 4.0 Zero
Lepsza stabilność dla bardziej spójnych wyników
Udoskonalona anatomia z dokładniejszymi proporcjami
Zmniejszenie szumów i artefaktów w generacjach
Naprawiono problemy z niskim nasyceniem, co skutkuje bogatszymi kolorami
Poprawiona dokładność kolorów dla bardziej atrakcyjnych wizualnie rezultatów
- 2025-01-24 – Początkowe wydanie
Szczegóły modelu
Opracowany przez: Cagliostro Research Lab
Typ modelu: model generatywny tekst na obraz bazujący na dyfuzji
Licencja: CreativeML Open RAIL++-M
Opis modelu: Model służy do generowania i modyfikowania obrazów o tematyce anime na podstawie promptów tekstowych
Fine-tuning na bazie: Stable Diffusion XL 1.0
Wytyczne użytkowania
Podsumowanie można zobaczyć na obrazku dotyczącym wytycznych dla promptów.

1. Struktura promptu
Model był trenowany z napisami opartymi na tagach oraz metodą ich porządkowania. Używaj tej ustrukturyzowanej formuły:
1girl/1boy/1other, nazwa postaci, z jakiej serii, rating, wszystko inne w dowolnej kolejności i kończąc tagami ulepszającymi jakość
2. Tagi ulepszające jakość
Dodaj te tagi na końcu promptu:
masterpiece, high score, great score, absurdres
3. Zalecany negatywny prompt
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. Optymalne ustawienia
Skala CFG: 4-7 (zalecane 5)
Liczba kroków próbkowania: 25-28 (zalecane 28)
Preferowany sampler: Euler Ancestral (Euler a)
5. Zalecane rozdzielczości
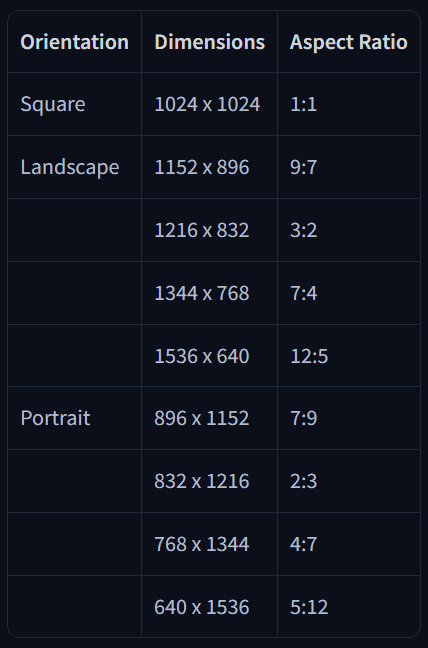
6. Przykład końcowej struktury promptu
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
Tagi specjalne
Model obsługuje różne specjalne tagi, które można wykorzystać do kontrolowania różnych aspektów procesu generacji obrazów. Tagi te są starannie wyważone i przetestowane, aby zapewnić spójne wyniki przy różnych promptach.
Tagi jakości
Tagi jakości to podstawowe kontrolki, które bezpośrednio wpływają na ogólną jakość i poziom szczegółowości obrazu. Dostępne tagi jakości:
masterpiecebest qualitylow qualityworst quality
Tagi wyników
Tagi wyników zapewniają bardziej wyrafinowaną kontrolę nad jakością obrazu niż podstawowe tagi jakości. Mają silniejszy wpływ na sterowanie jakością wyjściową w tym modelu. Dostępne tagi wyników:
high scoregreat scoregood scoreaverage scorebad scorelow score
Tagi czasowe
Tagi czasowe pozwalają wpływać na styl artystyczny bazujący na konkretnych okresach czasowych lub latach. Może to być przydatne przy generowaniu obrazów ze specyficznymi cechami artystycznymi danej ery. Obsługiwane lata:
year 2005year {n}year 2025
Tagi oceny
Tagi oceny pomagają kontrolować poziom bezpieczeństwa treści generowanych obrazów. Tagi te powinny być używane odpowiedzialnie i zgodnie z obowiązującymi przepisami oraz politykami platformy. Obsługiwane ratingi:
safesensitivensfwexplicit
Informacje o treningu
Model został wytrenowany przy użyciu najnowocześniejszego sprzętu i zoptymalizowanych hiperparametrów, aby zapewnić najwyższą jakość wyników. Poniżej przedstawiono szczegółowe specyfikacje techniczne i parametry użyte podczas treningu:

Podziękowania
Ten długoterminowy projekt nie byłby możliwy bez przełomowej pracy, innowacyjnych wkładów i kompleksowej dokumentacji ze strony Stability AI, Novel AI oraz Waifu Diffusion Team. Szczególnie dziękujemy za grant kickstarterowy od Main, który pozwolił nam pójść dalej niż wersja V2. W tej odsłonie chcielibyśmy wyrazić szczere podziękowania wszystkim członkom społeczności za ich nieustające wsparcie, w szczególności:
Moescape AI: Nasz nieoceniony partner we współpracy przy dystrybucji i testach modelu
Lesser Rabbit: Za zapewnienie niezbędnych grantów komputerowych i badawczych
Kohya SS: Za opracowanie kompleksowego frameworku treningowego open source
discus0434: Za stworzenie wiodącego w branży open source Aesthetic Predictor 2.5
Wczesni testerzy: Za ich poświęcenie w dostarczaniu krytycznych opinii i dokładnej kontroli jakości
Współtwórcy
Serdecznie dziękujemy naszym zaangażowanym członkom zespołu, którzy znacząco przyczynili się do projektu, w tym między innymi:
Model
Gradio
Relacje, finanse i zapewnienie jakości
Dane
Zbiórki Ponownie Otwarte!
Z radością przedstawiamy nowe metody zbiórek poprzez GitHub Sponsors, aby wspierać trening, badania i rozwój modeli. Twoje wsparcie pomaga nam przesuwać granice możliwości AI.
Możesz nam pomóc poprzez:
Darowizny: Wpłaty ETH lub USDT na poniższy adres.
Udostępnianie: Rozpowszechniaj informacje o naszych modelach i dziel się swoimi dziełami!
Opinia: Daj znać, jak możemy się poprawić.
Adres darowizn:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
GitHub Sponsor: https://github.com/sponsors/cagliostrolab/
Dlaczego korzystamy z kryptowalut?:
Kiedy początkowo otwieraliśmy zbiórki przez Ko-fi i korzystaliśmy z PayPal jako metody wypłat, nasze konto PayPal zostało oznaczone i ostatecznie zablokowane, mimo naszych starań wyjaśnienia celu projektu. Niestety zmusiło nas to do zwrotu wszystkich darowizn i pozbawiło wiarygodnej metody otrzymywania wsparcia. Aby uniknąć takich problemów i zapewnić transparentność, teraz korzystamy z kryptowalut jako formy zbiórek.
Chcesz przekazać darowiznę w walucie niekrypto?
Chociaż mieliśmy złe doświadczenia z PayPal i chciałbyś nas wspierać, ale nie chcesz używać kryptowalut, skontaktuj się z nami przez serwer Discord, aby ustalić alternatywne metody darowizn.
Dołącz do naszego serwera Discord
Zapraszamy na nasz serwer discord: https://discord.gg/cqh9tZgbGc
Ograniczenia
Format promptu: Ograniczony do promptów opartych na tagach; naturalna mowa może być nieskuteczna
Anatomia: Może mieć problemy ze skomplikowanymi detalami anatomicznymi, zwłaszcza pozami rąk i liczeniem palców
Generacja tekstu: Renderowanie tekstu na obrazach obecnie nie jest wspierane i niezalecane
Nowe postacie: Nowi bohaterowie mogą mieć niższą dokładność ze względu na ograniczone dane szkoleniowe
Wielu bohaterów: Sceny z wieloma postaciami mogą wymagać szczegółowego przygotowania promptów
Rozdzielczość: Wyższe rozdzielczości (np. 1536x1536) mogą mieć pogorszoną jakość, ponieważ trening odbywał się na oryginalnej rozdzielczości SDXL
Spójność stylu: Może wymagać konkretnych tagów stylu, ponieważ trening był bardziej skupiony na zachowaniu tożsamości niż spójności stylu
Licencja
Model korzysta z oryginalnej CreativeML Open RAIL++-M License od Stability AI bez żadnych modyfikacji czy dodatkowych ograniczeń. Warunki licencji pozostają dokładnie takie same jak w oryginalnej licencji SDXL, która obejmuje:
✅ Zezwolenia: użycie komercyjne, modyfikacje, dystrybucja, użytek prywatny
❌ Zakazy: działania nielegalne, generowanie szkodliwych treści, dyskryminacja, wykorzystywanie
⚠️ Wymagania: dołącz kopię licencji, podaj zmiany, zachowaj powiadomienia
📝 Gwarancja: dostarczone "TAK JAK JEST" bez gwarancji
Prosimy o zapoznanie się z oryginalną licencją SDXL dla pełnych i autorytatywnych warunków.

Szczegóły modelu
Dyskusja
Proszę się log in, aby dodać komentarz.
Kolekcja modeli - Animagine XL 4.0
Obrazy autorstwa Animagine XL 4.0 - v4 Opt
Obrazy z anime










Obrazy z model bazowy

Obrazy z sdxl


