Anime Illust Diffusion XL - v0.61
Powiązane słowa kluczowe i tagi
Wyróżnione obrazy


Zalecane podpowiedzi
Trigger word (by xxx),a girl named frieren from sousou no frieren series,best quality,beautiful color,detailed,aesthetic,impasto style,cowboy shot,fantasy theme,gradient background,sitting on ground,expressionless,white hair,twintails,green eyes,parted lip,white dress,frills,a cat,grass,sunshine
best quality, 1girl, solo, looking at viewer, bangs
Zalecane negatywne podpowiedzi
(worst quality:1.3),low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxlv05_neg
Zalecane parametry
samplers
steps
cfg
resolution
vae
Zalecane parametry wysokiej rozdzielczości
denoising strength
Wskazówki
Zmniejsz wagę dla słów wywoławczych stylu artysty, np. (by xxx:0.6).
Sortowanie tagów prompt pomaga modelowi lepiej zrozumieć znaczenie; zalecana kolejność tagów jest podana.
Używaj 'doprecyzowania' (image2image lub inpainting), jeśli rezultaty text2image są rozmyte.
Do łączenia stylów kontroluj wagę i kolejność stylów oraz dołączaj słowa stylu zamiast poprzedzać.
Słowa wywoławcze postaci zwykle nie zawierają ubioru; dodaj tagi ubioru osobno.
Dla wersji 0.61 i wcześniejszych używaj modelowych negatywnych embeddings tekstowych dla najlepszych rezultatów.
Zapewnij by całkowita liczba pikseli była bliska 1024x1024, a wymiary były podzielne przez 32, dla optymalnej generacji.
Najważniejsze informacje o wersji
Silniejsza stylizacja.
Dodatkowo dodałem dodatkowy szum podczas treningu. Niektóre sampelery nie osiągają zera przy ostatnim kroku, co może powodować szum na wygenerowanym obrazie. Dlatego Euler A lub sampler Euler mogą być bardziej odpowiednie do użycia.
风格化更明显。
另外,我在训练中使用了附加噪声。部分采样器的最终时间步不会归零,因此可能导致生成的图像带有噪声。因此,Euler A 或 Euler 采样器可能更适合您使用。
Sponsorzy twórcy
Jeśli podobają Ci się nasze prace, wesprzyj nas przez Ko-fi: https://ko-fi.com/eugeai
Dzięki dla społeczności @NieTa (nieta.art) za wsparcie mocy obliczeniowej oraz dla @KirinTea_Aki (profil Civitai) i @Chenkin (profil Civitai) za wsparcie danych.
Wprowadzenie do Modelu (część angielska)
I Spis treści
W tym wprowadzeniu dowiesz się o:
Informacjach o modelu (patrz Sekcja II);
Instrukcjach użytkowania (patrz Sekcja III);
Parametrach treningu (patrz Sekcja IV);
Liście słów wywoławczych (patrz Aneks Część A)
II AIDXL
Anime Illustration Diffusion XL, lub AIDXL, to model dedykowany do generowania stylizowanych ilustracji anime. Posiada ponad 800 (z coraz większą liczbą przy aktualizacjach) wbudowanych stylów ilustracji, które aktywowane są przez określone słowa wywoławcze (patrz Aneks A).
Zalety:
Elastyczna kompozycja, w przeciwieństwie do tradycyjnych poz AI.
Precyzyjne detale, zamiast chaotycznego bałaganu.
Lepsze poznanie postaci anime.
III Przewodnik użytkownika
1 Podstawowe użycie
1.1 Prompt
Słowa wywoławcze: Dodaj słowa wywoławcze podane w Aneksie A w celu stylizacji obrazu. Odpowiednie słowa znacznie poprawią jakość;
Zalecane jest zmniejszenie wagi słów wywoławczych dotyczących stylu artysty, np. (by xxx:0.6).
Sortowanie semantyczne: Sortowanie tagów lub zdań w prompt pomoże modelowi lepiej zrozumieć znaczenie.
Zalecana kolejność tagów: Słowo wywoławcze (by xxx) -> postać (dziewczyna imieniem frieren z serii sousou no frieren) -> rasa (elf) -> kompozycja (cowboy shot) -> styl (impasto ) -> temat (fantasy) -> główne otoczenie (w lesie, w dzień) -> tło (gradient) -> akcja (siedząca na ziemi) -> wyraz twarzy (bezwzględny wyraz) -> główne cechy (białe włosy) -> cechy ciała (kucyki, zielone oczy, rozchylone usta) -> ubranie (biała sukienka) -> dodatki do ubioru (falbanki) -> inne przedmioty (kot) -> drugorzędne otoczenie (trawa, słońce) -> estetyka (piękne kolory, detale, estetyczne) -> jakość ((najlepsza jakość:1.3))
Negatywne prompt: (najgorsza jakość:1.3), niska jakość, niskores, nieporządek, abstrakcja, brzydki, zniekształcony, zła anatomia, szkic, zdeformowane ręce, złączone palce, podpis, tekst, wielokrotne widoki
1.2 Parametry generacji
Rozdzielczość: Zapewnij, że całkowita liczba pikseli (=szerokość * wysokość) wynosi około 1024*1024, a szerokość i wysokość są podzielne przez 32, wtedy AIDXL osiąga najlepszy rezultat. Na przykład 832x1216 (2:3), 1216x832 (3:2) oraz 1024x1024 (1:1) itd.
Sampler i kroki: Użyj sampler'a "Euler Ancester", zwanego Euler A w webui. Ustaw około ~28 kroków przy 7 do 9 CFG Scale.
'Doprecyzowanie': Obrazy generowane metodą text2image czasem są rozmyte, wtedy należy je 'doprecyzować' używając image2image lub inpainting itd.
Do prostego powiększenia możesz odwołać się do: Upscale to huge sizes and add detail with SD Upscale, it's easy! : r/StableDiffusion (reddit.com)
Inne komponenty: Nie ma potrzeby używania żadnego modelu refiner. Używaj VAE modelu lub
sdxl-vae.
P: Jak odtworzyć okładkę modelu? Dlaczego nie mogę odtworzyć tego samego obrazu co na okładce przy tych samych parametrach generacji?
O: Ponieważ parametry generacji pokazywane na okładce NIE SĄ parametrami text2image, lecz parametrami image2image (do powiększenia). Bazowy obraz jest generowany głównie przez sampler Euler Ancester, a nie DPM.
2 Specjalne użycie
2.1 Uogólnione style
Od wersji 0.7 AIDXL podsumowuje kilka podobnych stylów i wprowadza uogólnione słowa wywoławcze stylu. Te słowa wywoławcze reprezentują typowe kategorie stylów animacji. Zauważ, że uogólnione słowa wywoławcze niekoniecznie odpowiadają znaczeniu artystycznemu oryginalnego słowa, ale są specjalnie przedefiniowanymi słowami wywoławczymi.
2.2 Postacie
Od wersji 0.7 AIDXL wzmocnił trening postaci. Efekt niektórych słów wywoławczych postaci już może osiągnąć efekt Lora i dobrze rozdziela koncept postaci od jej ubioru.
Sposób wywoływania postaci to: {character} \({copyright}\). Na przykład, aby wywołać bohaterkę Lucy z animacji "Cyberpunk: Edgerunners", użyj lucy \(cyberpunk\); aby wywołać postać Gan Yu z gry "Genshin Impact", użyj ganyu \(genshin impact\). Tu "lucy" i "ganyu" to imiona postaci, "\(cyberpunk\)" i "\(genshin impact\)" to źródła postaci, a nawiasy są poprzedzone ukośnikami "\" by zapobiec interpretacji jako ważonych tagów. Dla niektórych postaci część dotycząca praw autorskich nie jest konieczna.
Od wersji v0.8 jest łatwiejsza metoda wywoływania: a {girl/boy} named {character} from {copyright} series.
Lista słów wywoławczych postaci dostępna pod adresem: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). Ponadto mogą zawierać inne, nie wymienione w tym dokumencie słowa wywoławcze.
Niektóre postacie wymagają dodatkowego kroku wywołania. Jeśli pojedyncze słowo wywoławcze nie odtwarza postaci kompletne, należy dodać do promptu główne cechy postaci.
AIDXL obsługuje ubieranie postaci. Słowa wywoławcze postaci zazwyczaj nie zawierają koncepcji ubioru danej postaci. Aby dodać ubranie, trzeba dodać tagi ubioru w prompt. Na przykład srebrna wieczorowa suknia, głęboki dekolt to strój postaci St. Louis (Luxurious Wheels) z gry Azur Lane. Podobnie można dodać dowolne tagi ubrania dowolnej postaci.
2.3 Tagi jakości
Tagi jakości i estetyki są oficjalnie wytrenowane. Dodanie ich w promptach wpływa na jakość wygenerowanego obrazu.
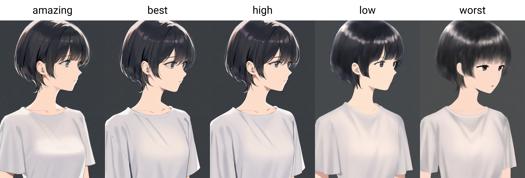
Od wersji 0.7 AIDXL oficjalnie wprowadza tagi jakości. Jakości są podzielone na sześć poziomów, od najlepszej do najgorszej: amazing quality, best quality, high quality, normal quality, low quality i worst quality.
Zaleca się dodanie dodatkowej wagi do tagów jakości, np. (amazing quality:1.5).
2.4 Tagi estetyczne
Od wersji 0.7 wprowadzono tagi estetyczne opisujące szczególne cechy estetyczne obrazów.
2.5 Łączenie stylów
Można łączyć style w styl własny. „Łączenie” oznacza używanie wielu słów wywoławczych stylu jednocześnie. Na przykład chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Kilka wskazówek:
Kontroluj wagę i kolejność stylów aby dostosować styl.
Dołączaj a nie poprzedzaj prompt słowa stylu.
IV Strategia treningu i parametry
AIDXLv0.1
Używając SDXL1.0 jako modelu bazowego, około 22 tysiące oznaczonych obrazów jest trenowanych przez około 100 epok na schedulerze kosinusowym z learning rate 5e-6 i liczbą cykli = 1 aby uzyskać model A. Następnie przy learning rate 2e-7 i tych samych pozostałych parametrach uzyskano model B. Model AIDXLv0.1 uzyskano łącząc modele A i B.
AIDXLv0.51
Strategia treningu
Wznowienie treningu od AIDXLv0.5, z trzema etapami treningu wykonywanymi kolejno:
Trening długich opisów: użycie całego zbioru danych, niektóre obrazy opisane ręcznie. Trening U-Net i enkodera tekstu jednocześnie z optymalizatorem AdamW8bit, wysokie lr (~1.5e-6) z kosinusowym schedulerem. Zatrzymanie treningu gdy lr spadnie poniżej progu (~5e-7).
Trening krótkich opisów: ponowne uruchomienie treningu z wyniku kroku 1. z tymi samymi parametrami ale krótszymi opisami.
Krok dopracowania: przygotowanie podzbioru ze zbioru z kroku 1. zawierającego obrazy wysokiej jakości wyselekcjonowane manualnie. Trening z wyniku kroku 2. z niskim lr (~7.5e-7), kosinusowym schedulerem z 5-10 restartami. Trening aż do dobrej estetyki.
Stałe parametry treningu
Brak dodatkowego szumu jak offset szumu.
Minimalne gamma snr = 5: przyspieszenie treningu.
Pełna precyzja bf16.
Optymalizator AdamW8bit: równowaga wydajności i efektywności.
Zbiór danych
Rozdzielczość: 1024x1024 ( = wysokość razy szerokość) z modyfikowaną oficjalną strategią bucketing SDXL.
Opisywanie: opisane przez model WD14-Swinv2 z progiem 0.35.
Przycinanie zbliżeń: przycinanie obrazów na zbliżenia, bardzo przydatne przy dużych lub rzadkich obrazach.
Słowa wywoławcze: zachowaj pierwszy tag obrazów jako słowa wywoławcze.
AIDXLv0.6
Strategia treningu
Wznowienie treningu od AIDXLv0.52 z adaptacyjną strategią powtarzania - dla każdego opisanego obrazu w zbiorze zwiększ liczbę powtórzeń w treningu zależnie od poniższych reguł:
Reguła 1: Im wyższa jakość obrazu, tym więcej powtórzeń;
Reguła 2: Jeśli obraz należy do klasy stylu:
Jeśli klasa jest nie dopasowana lub niedouszowana, ręcznie zwiększ liczbę powtórzeń w klasie lub automatycznie zwiększ do presetowanej wartości ok. 100.
Jeśli klasa jest już dopasowana lub nadouszana, zmniejsz ręcznie powtórzenia do 1 i odrzuć je jeśli jakość jest niska.
Reguła 3: Limit powtórzeń nie może przekroczyć określonego progu, około 10.
Strategia ma następujące zalety:
Chroni oryginalne informacje modelu przed nowym treningiem - podobnie jak w regularizowanym obrazie;
Umożliwia lepszą kontrolę nad wpływem danych treningowych;
Wyrównuje trening między klasami, motywując niedopasowane i unikając nadmiaru dopasowania tych już dopasowanych;
Znacząco oszczędza zasoby obliczeniowe i ułatwia dodawanie nowych stylów do modelu.
Stałe parametry treningu
Takie same jak w AIDXLv0.51.
Zbiór danych
Zbiór danych AIDXLv0.6 opiera się na AIDXLv0.51, z dodatkowymi optymalizacjami:
Sortowanie semantyczne opisów: Sortuj tagi opisów wg znaczenia, np. "gun, 1boy, holding, short hair" -> "1boy, short hair, holding, gun".
Usuwanie duplikatów tagów: Usuń duplikaty, zachowując ten z największą informacją. Duplikaty to tagi o podobnym znaczeniu jak "long hair" i "very long hair".
Dodatkowe tagi: Ręcznie dodawaj dodatkowe tagi do wszystkich obrazów, np. "high quality", "impasto" itd. Można to szybko zrobić narzędziami.
V Specjalne podziękowania
Sponsoring mocy obliczeniowej: Podziękowania dla społeczności @NieTa (捏Ta (nieta.art)) za wsparcie mocy obliczeniowej;
Wsparcie danych: Podziękowania dla @KirinTea_Aki (Profil twórcy KirinTea_Aki | Civitai) oraz @Chenkin (Profil twórcy Chenkin | Civitai) za duże wsparcie danych;
Nie byłoby wersji 0.7 bez nich.
VI AIDXL vs AID
2023/08/08. AIDXL trenowano na tym samym zbiorze co AIDv2.10, ale przewyższa AIDv2.10. AIDXL jest mądrzejszy i potrafi wiele rzeczy, których modele na bazie SD1.5 nie potrafią. Dobrze rozróżnia pojęcia, uczy się szczegółów obrazu, radzi sobie z kompozycjami trudnymi lub wręcz niemożliwymi dla SD1.5 i AID. Ogólnie, ma ogromny potencjał. Będę go nadal aktualizować.
VII Sponsoring
Jeśli podoba Ci się nasza praca, możesz nas wesprzeć przez Ko-fi(https://ko-fi.com/eugeai), aby pomóc w badaniach i rozwoju. Dziękujemy za wsparcie~
Wprowadzenie do modelu (część chińska)
I Spis treści
W tym wprowadzeniu dowiesz się o:
Wprowadzeniu do modelu (patrz część II);
Przewodniku użytkownika (patrz część III);
Parametrach treningu (patrz część IV);
Liście słów wywoławczych (patrz Aneks A).
II Wprowadzenie do modelu
Anime Illust Diffusion XL, zwany również AIDXL, to model dedykowany do generowania ilustracji 2D. Zawiera ponad 800 stylów ilustracji (z każdą aktualizacją coraz więcej), wyzwalanych przez określone słowa wywoławcze (patrz Aneks A).
Zalety: odważna kompozycja bez sztuczności, wyraźny główny obiekt, brak nadmiernych detali, rozpoznaje wiele postaci anime (wywołuje poprzez japońskie imiona postaci zapisane fonetycznie, np. "ayanami rei" dla "绫波丽", "kamado nezuko" dla "祢豆子").
III Przewodnik użytkownika (będzie aktualizowany)
1 Podstawowe użycie
1.1 Pisanie promptów
Używaj słów wywoławczych: Użyj słów podanych w Aneksie A do stylizacji obrazów. Odpowiednie słowa znacznie poprawiają jakość generacji;
Taguj prompt: Używaj tagów, aby opisać generowany obiekt;
Sortuj prompt: Sortowanie promptu pomaga modelowi lepiej zrozumieć znaczenie. Zalecana kolejność:
Słowo wywoławcze (by xxx)-> główny bohater (1girl) -> postać (frieren) -> rasa (elf) -> kompozycja (cowboy shot) -> styl (impasto) -> temat (fantasy) -> główne otoczenie (las, dzień) -> tło (gradient) -> akcja (siedząca) -> wyraz (bez wyrazu) -> główne cechy postaci (białe włosy) -> cechy ciała (kucyki, zielone oczy, rozchylone usta) -> ubranie (biała suknia) -> dodatki (falbanki) -> inne przedmioty (magiczna różdżka) -> drugorzędne otoczenie (trawa, słońce) -> estetyka (piękne kolory, detale, estetyka) -> jakość (najlepsza jakość)
Negatywne prompt: najgorsza jakość, niska jakość, niskores, bałagan, abstrakcja, brzydota, zdeformowany, zła anatomia, szkic, zdeformowane ręce, złączone palce, podpis, tekst, wiele widoków
1.2 Parametry generacji
Rozdzielczość: Zapewnij rozdzielczość około 1024x1024 i szerokość i wysokość podzielne przez 32, np. 832x1216 (3:2), 1216x832 (3:2) oraz 1024x1024 (1:1).
Clip Skip nie jest stosowany, czyli Clip Skip = 1.
Sampler i kroki: Używaj "euler_ancester" sampler'a, nazywanego Euler A w webui. Ustaw 28 kroków przy 7 CFG Scale.
Używaj tylko modelu bez Refiner'a.
Używaj modelowego vae lub sdxl-vae.
2 Specjalne użycie
2.1 Uogólnione style
W wersji 0.7 podsumowano wiele podobnych stylów i wprowadzono uogólnione słowa wywoławcze stylu, reprezentujące popularne kategorie ilustracji anime.
Zwróć uwagę, że uogólnione słowa wywoławcze niekoniecznie odpowiadają swojemu dosłownemu znaczeniu, ale są specjalnie przedefiniowane.
2.2 Postacie
W wersji 0.7 wzmocniono trening postaci. Niektóre słowa wywoławcze osiągają efekt podobny do Lora i dobrze oddzielają postać od ubioru.
Wywołanie postaci: nazwa postaci \(dzieło\). Na przykład "lucy \(cyberpunk\)" dla bohaterki z animacji "Cyberpunk: Edgerunners", "ganyu \(genshin impact\)" dla postaci z gry "Genshin Impact". Nawiasy są poprzedzone ukośnikami, by nie były interpretowane jako tagi z wagą. Dla niektórych postaci źródło nie jest obowiązkowe.
Słowa wywoławcze postaci można znaleźć w selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co).
Jeśli jedna nazwa postaci nie wystarcza do pełnego oddania, dodaj w prompt główne cechy postaci.
AIDXL obsługuje ubieranie postaci; słowa wywoławcze postaci zwykle nie zawierają cech ubioru. Aby dodać ubranie, należy do promptu dołączyć tagi ubrania. Na przykład "silver evening gown, plunging neckline" odpowiada strojowi postaci St. Louis (Luxurious Wheels) z gry Azur Lane. Możesz też dodać tagi ubioru innych postaci do poszczególnych postaci.
2.3 Tagi jakości
Od wersji 0.7 tagi jakości i estetyki są oficjalnie wytrenowane i wpływają na jakość wygenerowanych obrazów.
Tagi jakości dzielą się na sześć poziomów, od najlepszej do najgorszej: amazing quality, best quality, high quality, normal quality, low quality i worst quality.
2.4 Tagi estetyczne
Od wersji 0.7 wprowadzono tagi opisujące estetyczne właściwości obrazów.
2.5 Łączenie stylów
Możesz łączyć style w własny styl. „Łączenie” oznacza jednoczesne użycie wielu słów wywoławczych. Na przykład: chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Wskazówki:
Kontroluj wagę i kolejność stylów dla efektu końcowego.
Doklejaj zamiast poprzedzać słowa stylu w prompt.
3 Uwagi
Używaj VAE, embeddings tekstowych i modeli Lora obsługiwanych przez SDXL. Uwaga: sd-vae-ft-mse-original nie jest VAE odpowiednim dla SDXL; EasyNegative, badhandv4 i inne negatywne embeddings też nie są zgodne z SDXL;
Dla wersji 0.61 i wcześniejszych, podczas generacji silnie zaleca się użycie dedykowanych negatywnych embeddings modelu (do pobrania w sekcji Suggested Resources), gdyż mają bardzo pozytywny wpływ na model;
Nowe słowa wywoławcze w każdej wersji mogą mieć słabszy lub niestabilny efekt w danym wydaniu.
IV Parametry treningu
Na modelu bazowym SDXL1.0 użyto około 20 tys. własnoręcznie oznaczonych obrazów, trenowanych około 100 epok z lr 5e-6 i schedulerem kosinusowym z 1 cyklem, uzyskując model A. Następnie trenowano model B z lr 2e-7, pozostałe parametry takie same. Po połączeniu A i B uzyskano model AIDXLv0.1.
Inne parametry treningu znajdziesz w wersji angielskiej.
V Specjalne podziękowania
Sponsoring mocy obliczeniowej: dzięki społeczności @NieTa (捏Ta (nieta.art)) za wsparcie;
Wsparcie danych: dzięki @秋麒麟热茶 (Profil twórcy KirinTea_Aki | Civitai) i @风吟 (Profil twórcy Chenkin | Civitai) za duże wsparcie danych;
Bez nich nie byłoby wersji 0.7.
VI Dziennik zmian
2023/08/08: AIDXL trenowano na tym samym zestawie jak AIDv2.10, ale przewyższa AIDv2.10. AIDXL jest bardziej inteligentny i potrafi wiele rzeczy niedostępnych dla modeli bazujących na SD1.5. Rozróżnia koncepcje, uczy się detali obrazów i radzi sobie z trudnymi kompozycjami, które są wyzwaniem dla SD1.5 i AID, niemal doskonałe w stylu, którego starsze wersje AID nie mogły osiągnąć. Ogólnie ma wyższy potencjał niż SD1.5, a ja będę kontynuował jego rozwój.
2024/01/27: Wersja 0.7 zawiera wiele nowości, a rozmiar bazy danych jest ponad dwukrotnie większy niż w poprzedniej wersji.
Aby uzyskać satysfakcjonujące oznaczenia, testowałem wiele nowych algorytmów przetwarzania tagów, m.in. sortowanie tagów, losowanie warstwowe, oddzielenie cech postaci itd. Projekt: Eugeoter/sd-dataset-manager (github.com);
Dla lepszej kontroli treningu stworzyłem specjalne skrypty treningowe oparte na Kohya-ss;
Aby kontrolować proces łączenia modeli z różnych generacji, opracowałem heurystyczne algorytmy łączenia; aby osiągnąć odpowiednią stylizację, zrezygnowałem z łączenia enkoderów tekstu i warstw wyjściowych UNET, co poprawiałoby stabilność i estetykę, ale osłabiało styl;
Aby oczyszczać dane, wytrenowałem modele do wykrywania znaków wodnych, klasyfikacji obrazów i oceny estetyki.
VII Wesprzyj nas
Jeśli podoba Ci się nasza praca, możesz nas poprzeć przez Ko-fi (https://ko-fi.com/eugeai), aby wspomóc badania i rozwój. Dziękujemy za wsparcie!
Aneks / Załącznik
A. Lista specjalnych słów wywoławczych / 特殊触发词列表
Słowa wywoławcze stylu artystycznego: Kliknij tutaj
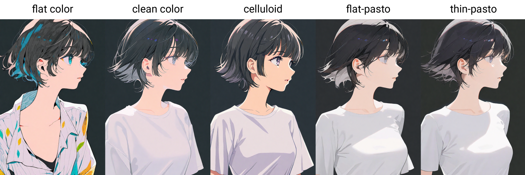
Słowa wywoławcze stylu malarskiego: flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: Płaski kolor, użycie linii do opisania światła i cienia
平涂:kolory płaskie, użycie linii i plam do opisania światła i cienia
clean color: Styl pomiędzy flat color i flat-pasto. Proste i schludne kolorowanie.
Kolor czysty: styl pomiędzy flat color i flat-pasto; prosty i uporządkowany kolor.
celluloid: Kolorowanie w stylu anime
Kolorowanie celuloidowe: kolorowanie anime
flat-pasto: Prawie płaski kolor, użycie gradientu do opisu światła i cienia
flat-pasto: prawie płaski kolor, użycie gradientu do opisu światła i cienia
thin-pasto: Cienki kontur, użycie gradientu i grubości farby do opisu światła, cienia i warstw
Cienki pasto: cienkie kontury, użycie gradientu i grubości farby do opisu światła, cienia i warstw
pseudo-impasto:Użycie gradientów i grubości farby do opisu światła, cienia i warstw
Pseudo-impasto / półgrube malowanie: użycie gradientów i grubości farby do opisu światła, cienia i warstw
impasto:Użycie grubości farby do opisu światła, cienia i gradacji
Impasto: użycie grubości farby do opisu światła, cienia i przejść tonalnych
realistic
Realistyczny
photorealistic:Przedefiniowany na styl bliższy rzeczywistości
Fotorealistyczny: przedefiniowany na styl bliższy rzeczywistości
cel shading: Styl 3D w anime
Cel shading: styl modelowania 3D w anime
3d

Słowa wywoławcze estetyki:
beautiful
Piękny
aesthetic: lekko abstrakcyjne odczucie artystyczne
Estetyczny: lekko abstrakcyjne odczucie artystyczne
detailed
Szczegółowy
beautiful color: subtelne użycie koloru
Piękne kolory: umiejętne użycie koloru
lowres
messy: chaotyczna kompozycja lub detale
Bałagan: chaotyczna kompozycja lub detale
Słowa wywoławcze jakości: amazing quality, best quality, high quality, low quality, worst quality




Szczegóły modelu
Typ modelu
Model bazowy
Wersja modelu
Hash modelu
Wytrenowane słowa
Twórca
Dyskusja
Proszę się log in, aby dodać komentarz.
Kolekcja modeli - Anime Illust Diffusion XL


Obrazy autorstwa Anime Illust Diffusion XL - v0.61
Obrazy z anime










Obrazy z model bazowy

Obrazy z płaski kolor










Obrazy z ilustracja








