Colossus Project Flux - V12 "Hephaistos" FP8_UNET
Powiązane słowa kluczowe i tagi
Wyróżnione obrazy





Zalecane negatywne podpowiedzi
blurry
Zalecane parametry
samplers
steps
cfg
resolution
vae
Wskazówki
Używaj około 20-30 kroków z CFG na poziomie 2.2 dla jakościowych rezultatów.
Preferowane samplery to Euler ze schedularem Simple; DPM++ 2M i Heun również działają dobrze.
Dodaj negatywny prompt 'blurry', aby zmniejszyć niepożądane artefakty.
Dla eksperymentalnego modelu v2.1 wyłącz Flux guidance scale i używaj zamiast tego CFG scale.
Wersja FP4 jest tylko dla kart Nvidia serii 50xx; wersja int4 działa na 40xx i starszych GPU.
Pobierz niezbędne pliki Clip_L, aby wersje tylko UNET działały poprawnie.
Eksperymentuj z różnymi samplerami i ustawieniami CFG w zalecanych zakresach, aby otrzymać zróżnicowane wyniki.
Najważniejsze informacje o wersji
WORKFLOW: https://civitai.com/articles/17163
Wersja FP8_unet V12: użyj tego clip_l do tego:
https://civitai.com/models/833086?modelVersionId=1985466
Użyj także t5xxl_fp8_e4m3fn z tym unetem.
Wersja V12 "Hephaistos"
Publikacja tego checkpointu sprawia mi równocześnie radość i smutek.. V12 będzie ostatnim checkpointem tej serii.. Głównym powodem są nadchodzące przepisy UE dotyczące AI... Kolejnym powodem jest licencja Flux .1 DEV. Dziękuję wszystkim za wsparcie!
Tak czy inaczej.. zakończę tę serię na wysokim poziomie...
V12 bazuje na V10B "BOB" ale zawiera w zasadzie najlepsze części tej serii zblokowane w jednym checkpointcie. (Był to rezultat nowej metody łączenia, która zajęła około 1:30h i zużyła całe moje 128GB RAM). Ulepszyłem także tekstury twarzy i skóry w porównaniu do V10. Oczy są znacznie bardziej realistyczne i "żywe" niż wcześniej.
Przetestuj sam i podziel się opinią na temat V12. "Dzięki" mojemu wolnemu łączu internetowemu, najpierw załaduję FP8_UNET. Potem wersję FP8 "all in one", a następnie FP16_unet i FP16_BEHEMOTH. Spróbuję też przekonwertować na int4 i fp4 (trzymaj za mnie kciuki).
Jak zawsze, daj znać, co myślisz o V12..
Sponsorzy twórcy
Jeśli podoba Ci się ten model, wesprzyj twórcę na Ko-fi.
Sprawdź poradniki instalacji i workflow dla łatwiejszej konfiguracji:
- https://civitai.com/articles/17313
- https://civitai.com/articles/17358
- https://civitai.com/articles/17163
- https://civitai.com/articles/15610
Dodatkowe workflow i obrazy showcase dostępne tutaj.
Głęboko pod górą żyje śpiący olbrzym, zdolny albo pomóc ludzkości, albo zniszczyć ją...
Powstaje Kolos...
Po mojej serii SDXL nadszedł czas na serię FLUX tego projektu... Tym razem trenowałem to od podstaw. Do treningu użyłem własnych obrazów. Stworzyłem je za pomocą mojego modelu schnell Flux DemonFlux/Colossus Project schnell + mojego SDXL Colossus Project 12 jako refinera.
Ten checkpoint SD Flux potrafi wygenerować niemal wszystko.. Colossus bardzo dobrze tworzy ekstremalnie realistyczne obrazy, anime i sztukę.
Jeśli Ci się podoba, chętnie przyjmę Twoją opinię. Jeśli chcesz mnie wesprzeć, możesz to zrobić tutaj. Wydałem sporo pieniędzy na zbudowanie komputera zdolnego do trenowania modeli Flux.. Trening i testy też zajmują dużo czasu i prądu..
https://ko-fi.com/afroman4peace
Wersja V12 "Hephaistos"
Publikacja tego checkpointu sprawia mi równocześnie radość i smutek.. V12 będzie ostatnim checkpointem tej serii.. Głównym powodem są nadchodzące przepisy UE dotyczące AI... Kolejnym powodem jest licencja Flux .1 DEV. Dziękuję wszystkim za wsparcie! Włożyłem dużo czasu w ten projekt w ciągu ostatniego roku. Teraz czas przejść do innego projektu.
Tak czy inaczej.. zakończę tę serię na wysokim poziomie...
V12 bazuje na V10B "BOB" ale zawiera w zasadzie najlepsze części tej serii zblokowane w jednym checkpointcie. (Był to rezultat nowej metody łączenia, która zajęła około 1:30h i zużyła całe moje 128GB RAM). Ulepszyłem także tekstury twarzy i skóry w porównaniu do V10. Oczy są znacznie bardziej realistyczne i "żywe" niż wcześniej.
Przetestuj sam i podziel się opinią na temat V12. "Dzięki" mojemu wolnemu łączu internetowemu, najpierw załaduję FP8_UNET. Potem wersję FP8 "all in one", a następnie FP16_unet i FP16_BEHEMOTH. Spróbuję też przekonwertować na int4 i fp4 (trzymaj za mnie kciuki).
Jak zawsze, daj znać, co myślisz o V12..
Wersja V12 "Behemoth" (AIO)
Ten "all in one" model jest najlepszy z mojej serii V12.. no i największy rozmiarem oczywiście :-)
Behemoth zawiera spersonalizowany T5xxl i Clip_l zintegrowany bezpośrednio w modelu. Jeśli wolisz jakość od ilości, to jest checkpoint dla Ciebie!
Wersja V12 FP4/int4
Dzięki Muyang Li z Nunchakutech, który dokonał kwantyzacji V12. https://huggingface.co/nunchaku-tech i ich niesamowitym nunchaku!
Ta wersja jest naprawdę oszałamiająca. Łączy jakość z szybkością jakiej wcześniej nie było.
UWAGA!
Są dwie wersje: FP4 i int4. FP4 jest tylko dla kart graficznych Nvidia serii 50xx! Natomiast int4 działa na 40xx i starszych. (potrzebujesz co najmniej karty z serii 20xx)
Możesz też pobrać obie wersje bezpośrednio tutaj: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
PORADNIK INSTALACJI i WORKFLOW
Oto szybki poradnik instalacji i wstępny workflow.
https://civitai.com/articles/17313
SZCZEGÓŁOWY PORADNIK do workflow
https://civitai.com/articles/17358
Wciąż pracuję nad nowymi workflow dla Nunchaku.. więc poniższy workflow jest wciąż bardzo w fazie WIP (w trakcie pracy). Szczegółowy artykuł dodam w weekend.
Wersja V12 FP16_B_variant
Dzięki małemu błędowi, który popełniłem późno w nocy (2am) nazwałem i załadowałem "zły" checkpoint. To bardzo eksperymentalny checkpoint, nigdy nie miał być publikowany. Nie jest zbyt przetestowany, ale sprawdził się bardzo dobrze, gdy tworzyłem pokaz. Może być lepszy niż standardowa wersja.
Lubi się bardziej skłaniać ku azjatyckim twarzom.. To dlatego, że chciałem przetestować coś do mieszania z projektem pomocniczym, nad którym nadal pracuję. Podziel się ze mną swoimi doświadczeniami z tym checkpointem :-)
Wersja V12 AIO FP8
Ta wersja to wszystko w jednym (all in one) wersja V12. Oznacza to, że wszystkie clipy są wbudowane w model. Daje ten sam output co FP8_unet z moim spersonalizowanym clip_l.
Wersja V12 GGUF Q5_1
Ta wersja była na życzenie. Jakość nie jest zła..
Wersja V10B "BOB"
To alternatywna wersja V10. Stworzyłem ją, żeby ulepszyć FP8 wersję V10. W ogólnym rozrachunku wersja FP8 jest bardziej precyzyjna, a kolory lepsze. Niestety ostatnio nie mam dużo czasu.. (życie codzienne jest ważniejsze). Dlatego to zajęło tak długo.. Daj znać, jeśli wolisz tę wersję. Mam też FP16 wersję "BOB". W zależności od opinii rozważę opublikowanie wersji int4.
WORKFLOW:
Tutaj jest workflow dla V12 i V10: https://civitai.com/articles/17163
Wersja V10_int4_SVDQ "Nunchaku"
Na początku chcę podziękować theunlikely https://huggingface.co/theunlikely, który przekonwertował FP16_Unet na int4_SVDQ. Odwiedź jego stronę i zostaw like.
Ta wersja jest mniej więcej równa wersji FP8. Nawet w normlanym trybie w moim workflow jest około 2-3 razy szybsza niż zwykły model.. W trybie "fast" workflow mogę renderować 2MP obraz w około 19 sekund na mojej 3090Ti.
Czym jest SVDQ "Nunchaku"?
Ta nowa metoda kwantyzacji pozwala zmniejszyć modele Flux (w tym przypadku natywny model FP16) z 24GB do około 6.7GB. Ale to nie wszystko: możesz generować szybciej niż kiedykolwiek bez dużej utraty jakości. Oczywiście zauważysz drobne różnice względem mojego 32GB_Behemoth, ale do tego potrzebujesz dużo więcej VRAM/RAM, by go w ogóle uruchomić.
Więcej informacji tutaj: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Instalacja: Odwiedź mój poradnik workflow/instalacji: https://civitai.com/articles/15610
Wersja V10 "Behemoth" (FP16_AIO)
Ta wersja jest wciąż eksperymentalna. Głównym celem było uzyskanie bardziej realistycznych wyników. Udało mi się też zredukować trochę "linii Flux". Ten model bazuje na Colossus Project V5.0_Behemoth, V9.0 oraz innym projekcie, który nazywam "Ouroborus Project"
Wersja FP16 jest bardzo stabilna. Wkrótce wypuszczę też wersję FP8. Ta wersja też jest bardzo dobra, ale mniej stabilna..
Niech się bawisz podczas tworzenia :-)
Wersja V9.0:
Muszę sporo wyjaśnić.. Na początek, czemu to V9.0?
Właśnie wprowadziłem się do nowego mieszkania i z powodu błędów dostawcy internetu, nie miałem prawdziwego połączenia.. Podczas przeprowadzki zostawiłem komputer włączony. Efekt był taki, że stworzyłem dużo (głównie uszkodzonych) checkpointów. Mam jednak kilka bardzo dobrych wersji V8, które być może też opublikuję..
Co się zmieniło?
Dodałem nowe tekstury twarzy i skóry, biorąc zasadniczo najlepsze wyniki z V5.0. Model przeszedł też trening kończyn dla lepszej anatomii. Wersje V5.0 czasem obcinały głowę i stopy.. Myślę, że naprawiłem niektóre z tych problemów..
Dodatkowo trenowałem na większej liczbie własnych zdjęć krajobrazów.. Tak, zrobiłem to wszystko podczas przeprowadzki... Łączny czas treningu to około 2 tygodni obliczeniowych, co nie jest tanie.. (każda godzina kosztuje mnie około 25 centów za prąd)
Mam nadzieję, że ta wersja Ci się spodoba.. Jeśli chcesz mnie wesprzeć: dodaj fajne obrazy lub przekaż napiwek na buzz albo Ko-fi..
Podziel się opinią :-)
Wersja 5.0:
V5.0 bazuje na V4.2 i V4.4 (która też niedługo będzie wydana). Dostała dodatkowy trening szczegółów skóry i anatomii, co głównie poprawiło takie elementy jak dłonie i sutki. Szczegóły twarzy są dużo lepsze. Starałem się też naprawić drobne linie flux..
W ogólności ta wersja jest bardziej realistyczna niż V4.2 i lepsza w drobnych szczegółach.. Tak jak wersja 4.2, jest to hybrydowy model de-distilled. Można go używać zasadniczo z tymi samymi ustawieniami co V4.2.
Oto nowy workflow do zabawy: https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
Podziel się, co myślisz o tej wersji w porównaniu z 4.2 lub V2.1..
Wersja 4.4 "Research":
Dodałem tę wersję dla kompletności.. Jest nieco bardziej realistyczna niż V4.2 i jest bazą dla wersji 5.0. Możesz ją przetestować, jeśli chcesz. Możesz też używać workflow dla V5.0 i V4.2..
Wersja 4.2:
Ta wersja to w zasadzie dalszy rozwój Demoncore Flux i Colossus Project Flux. Celem było uzyskanie bardziej stabilnych wyników oraz lepszych tekstur skóry, lepszych dłoni i większej różnorodności twarzy. Trenowałem ją na hybrydowym modelu, częściowo Demoncore Flux. Poprawiłem też nieco sutki i NSFW. Daj znać, czy wolisz V4.2 niż wersję 2.1 :-)
W obrazach showcase używałem tylko natywnych obrazów z rozdzielczością SDXL lub 2MP (np. 1216x1632). Model radzi sobie też z wyższymi rozdzielczościami.. Testowałem ten checkpoint do 2500x2500, ale zalecam około 2000x2000.
Co do ustawień, polecam około 30 kroków i 2-2.5 CFG. Ja używam głównie 2.2 lub 2.3 w moim workflow. Do pokazu używałem DPM++ 2M z prostym schedulerem.
Niedługo dodam więcej wersji, ale przed świętami mam mało czasu..
Ustawienia
Niebawem dodam nowy dedykowany workflow Comfy. Na razie możesz zawsze pobrać i otworzyć obrazy showcase..
"All in One" wersja działa też dobrze z Forge..
Zasadniczo działa z tymi samymi ustawieniami co wersja 2.1 (patrz niżej)
Daj mu 20-30 kroków z około 2.2 CFG..
Wersja 2.1_de-distilled_experimental (MERGE)
Ta wersja jest całkowicie inna i działa inaczej niż zwykły model Flux!
To eksperymentalne połączenie mojej wersji 2.0 z wersją de-distilled https://huggingface.co/nyanko7/flux-dev-de-distill. Stało się to trochę przez przypadek, ale efekty są oszałamiające. Otrzymasz niesamowite szczegóły. Bardzo dobrze reaguje na polecenia... Następne, co zrobię, to trenowanie bezpośrednio na modelu de-distilled. Już zrobiłem kilka testowych LORów z nim. To bardzo eksperymentalne, więc daj znać, jeśli znajdziesz błędy, których nie wymieniłem poniżej. Jeśli masz dobre obrazy, dodaj je.. dodaj też złe, to pomoże ulepszyć model :-). Możesz też wypróbować wersję 2.0 i powiedzieć, która wersja CI bardziej odpowiada.
!Uwaga!
Normalny workflow Flux nie działa z tą wersją. MUSISZ pobrać mój workflow, żeby działała!
Możesz też coś sam wymyślić, ale proszę nie obwiniaj mnie za złe obrazy. To też bardzo eksperymentalny model... sprawdź wady poniżej..
Zalety i wady tego checkpointu:
Ten checkpoint potrafi tworzyć ekstremalne detale.. Ma to jednak swoją cenę.. Jest wolniejszy w porównaniu do normalnych checkpointów Flux. Zaletą jest to, że często nie potrzebujesz już dodatkowego powiększania obrazu. Zamiast Flux Guidance, ten model używa skali cfg. Co oznacza też, że nie będzie działać z standardowymi workflow.
Możesz używać negatywnych promptów! To pomaga usunąć z obrazu niepożądane elementy.
Czasem mogą pojawić się artefakty.. Możesz to rozwiązać prostym podwyższeniem skali (nad tym pracuję). Oto przykład.. to dziwnie nie występuje przy każdym seedzie.. AKTUALIZACJA: To nie jest problem modelu, a workflow.. Pracuję nad naprawą. Jeśli się pojawi, spróbuj ustawić pierwsze powiększenie na 1.14 zamiast 1.2.

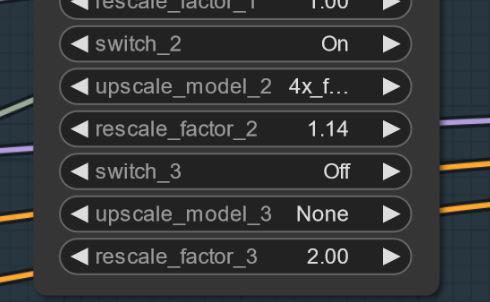
Ustawienia i Workflow V2.1:
Tutaj znajdziesz workflow: https://civitai.com/articles/8419
Ustawienia: w przeciwieństwie do normalnego Flux nie potrzebuje skali Flux Guidance. Używaj zamiast tego skali cfg. Zwykle używam 3 CFG w workflow.. Niektóre obrazy mogą wymagać niższych ustawień cfg.
Najważniejsze może być wyłączenie skali flux guidance..
Testowałem bez workflow z 30 krokami i 2-3 cfg. Te ustawienia mogą też działać dla Forge. Eksperymentuj.
Zalecam dodanie słowa "blurry" w negatywach
Sampler i scheduler:
Możesz wybierać spośród kilku działających samplerów:
Euler, Heun, DPM++2m, DEIS, DDIM działają świetnie.
Najczęściej używałem "simple" jako scheduler
Jeśli znajdziesz lepsze ustawienia, daj znać.. :-)
Dla Forge polecam używać modelu AIO.. tutaj przykład ustawień dla Forge
Wersja 2.0_dev_experimental
To wersja eksperymentalna.. Celem było stworzenie bardziej spójnego i szybszego modelu. Dodałem lory, które sam trenowałem, a potem połączyłem je w specjalny sposób (Tensor merge). Model ma spersonalizowany T5xxl zmodyfikowany przez "Attention Seeker". Dla zwiększenia szybkości i jakości dodałem Hyper Flux lora od ByteDance. To sprawiło, że model przesunął zakres działania.. Oto główny obraz tytułowy..
16 kroków V 2.0
 30 kroków V 1.0
30 kroków V 1.0
 Wady:
Wady:
Po pierwsze.. Ta wersja jest trochę większa niż poprzednia.. Po drugie, muszę jeszcze stworzyć wersję tylko Unet. Zaktualizuję, gdy to zrobię..
Ustawienia i Workflow V2.0:
Możesz teraz uruchomić model z mniej krokami.. 16 kroków odpowiada 30 krokom starego modelu.
Zalecam korzystanie z około 20-30 kroków, bo zazwyczaj daje to lepszą jakość.
Sampler: Wolę Euler ze schedulerem Simple. Guidance może być ustawiona między 1.5 a 3 (oczywiście możesz testować także poza tym zakresem). Guidance 1.8 dobrze działa dla realistycznych obrazów. Możesz też testować inne samplery. DPM++2M i Heun również działają świetnie.
Workflow 2.0:
Stworzyłem nowy workflow dla V2.0 i V1.0. Ma nowy Flux Prompt Generator. Działa też drugi etap upscalera. https://civitai.com/articles/7946
Forge:
Testowałem ten model z Forge i działał bardzo dobrze.. Obrazy mogą się różnić między Comfy UI a Forge..
Wersja 1.0_dev_beta:
To mój pierwszy model z tej serii. Proszę daj mi opinię i dodaj obrazy. To pomaga rozwijać projekt. Jest kilka wersji do wyboru. Najlepsza jakość to wersja FP16. FP16 jest duża i wymaga mocnej karty graficznej oraz dużo RAMu. FP8 to dobra równowaga między jakością a wydajnością. Jeśli chcesz wersję GGUF, pobierz Q8_0. Wersje GGUF Q4_0/4.1 były na życzenie. Są małe, ale tracisz trochę jakości.
W zasadzie są dwa typy moich modeli: "All in one", które wymagają pobrania tylko jednego pliku. Mają Clip_l, T5xxl fp8 i VAE wbudowane. (umieść ten plik w folderze checkpoints).
Drugi typ to wersje tylko UNET. Trzeba ładować pliki osobno.
W każdym przypadku musisz pobrać mój Clip_L, aby to działało prawidłowo..
Ważne jest też, by wybrać właściwy klip T5xxl. Dla FP8 jest to fp8_e4m3fn t5xxl clip. Dla FP16 jest to clip FP16. Upewnij się, że wybrałeś domyślny typ wag. (poniżej przykład obrazu dla wersji fp8)
Dla wersji GGUF potrzebujesz loadera GGUF!
Znane informacje o V1.0:
To pierwszy model serii, więc może mieć problemy z niektórymi promptami lub stylami, np. artystycznymi. Kolejne wersje będą trenowane bardziej. Daj znać, czego model nie potrafi..
Ustawienia i Workflow:
Testowałem z około 30 krokami, Euler ze schedulerem Simple. Guidance może być od 1.5 do 3 (oczywiście możesz testować też poza tym zakresem)
Guidance 1.8 dobrze działa dla realistycznych obrazów.
Eksperymentuj z tymi ustawieniami.. Jeśli masz dobre wyniki, podziel się nimi.
Do treningu dodałem obrazy showcase.. We wnętrzu znajduje się workflow dla Comfy. Oto workflow do pobrania: https://civitai.com/articles/7946
Model "All in one":
Tylko UNET:
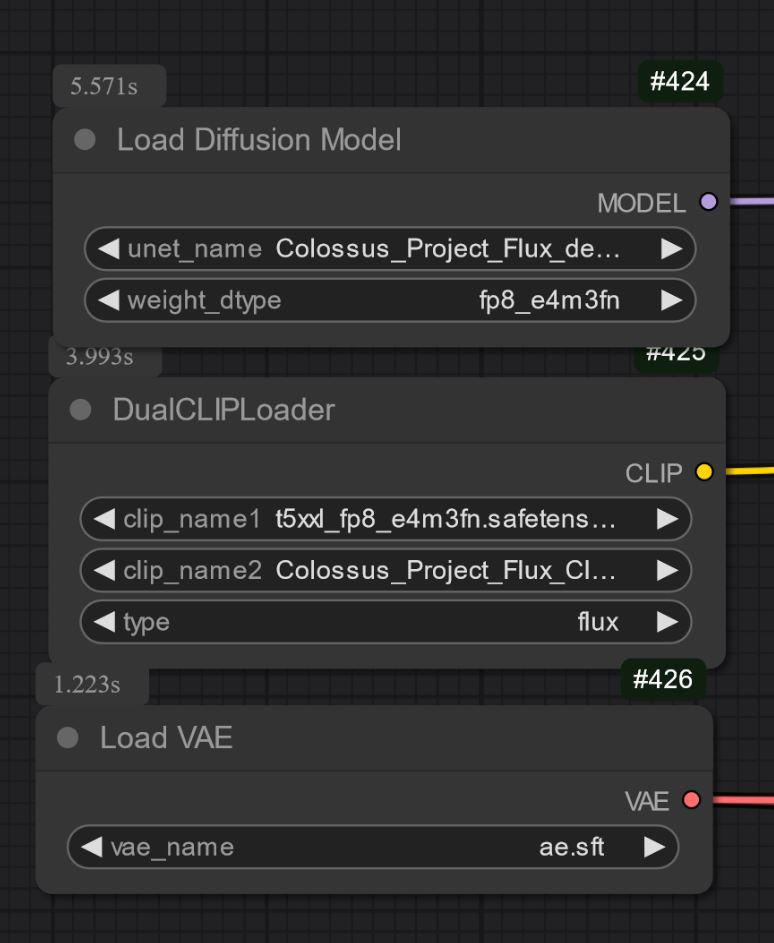 Musisz też pobrać clip_L. To plik 240MB.
Musisz też pobrać clip_L. To plik 240MB.
GGUF: Dodałem workflow dla GGUF tutaj: https://civitai.com/articles/7946
Ważne:
Model deweloperski nie jest przeznaczony do użytku komercyjnego. Wersję "schnell" opublikuję gdzie indziej. Jest bardziej przeznaczona do użytku osobistego lub naukowego.
Licencja:
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
Podziękowania:
theunlikely https://huggingface.co/theunlikel (jeszcze raz dziękuję)
Wersja 2.1/V4.2/5.0: Flux_dev_de-distill od nyanko7
https://huggingface.co/nyanko7/flux-dev-de-distill
Od V2.0: Hyper Lora od ByteDance https://huggingface.co/ByteDance/Hyper-SD
Black Forest za ich niesamowity model Flux https://huggingface.co/black-forest-labs

Szczegóły modelu
Typ modelu
Model bazowy
Wersja modelu
Hash modelu
Twórca
Dyskusja
Proszę się log in, aby dodać komentarz.
Kolekcja modeli - Colossus Project Flux

Colossus Project Flux - v12_int4_SVDQ_nunchaku

Colossus Project Flux - V12 "Hephaistos" FP8_UNET

Colossus Project Flux - v10_AIO_FP8
















































