Illustrious XL 1.0 - v1.0
Wyróżnione obrazy


Zalecane podpowiedzi
night, vivid colors
Zalecane negatywne podpowiedzi
very displeasing, displeasing, bad anatomy, artistic error, lowres, bad hands, signature, artist name, multiple views, artist sign
Zalecane parametry
samplers
steps
cfg
resolution
Wskazówki
Używaj zarówno opisów w języku naturalnym, jak i promptów opartych na tagach Danbooru dla bardziej zniuansowanego generowania obrazów.
Kompatybilny z modułami LoRA i ControlNet, pozwalając na dostosowanie stylu, pozy i kompozycji.
Illustrious XL v1.0 to surowy, wstępnie wytrenowany model bazowy idealny do dalszego dopasowywania lub szkolenia LoRA.
Sponsorzy twórcy
Odwiedź naszą stronę, aby zobaczyć, nad czym pracujemy i poznać nasz najnowszy model!
→https://www.illustrious-xl.ai/
Z radością informujemy, że teraz możesz generować obrazy bezpośrednio za pomocą naszych modeli Illustrious XL na naszej oficjalnej stronie: illustrious-xl.ai. Uruchomiliśmy pełną platformę do generowania obrazów z wysoką rozdzielczością, obsługą języka naturalnego i niestandardowymi ustawieniami — oraz kilkoma ekskluzywnymi modelami, których nie znajdziesz na innych portalach. Poznaj nasze zaktualizowane poziomy modeli i nazewnictwo tutaj: Model Series. Potrzebujesz pomocy na start? Zapoznaj się z naszym przewodnikiem użytkownika generowania obrazów: ILXL Image Generation User Guide.
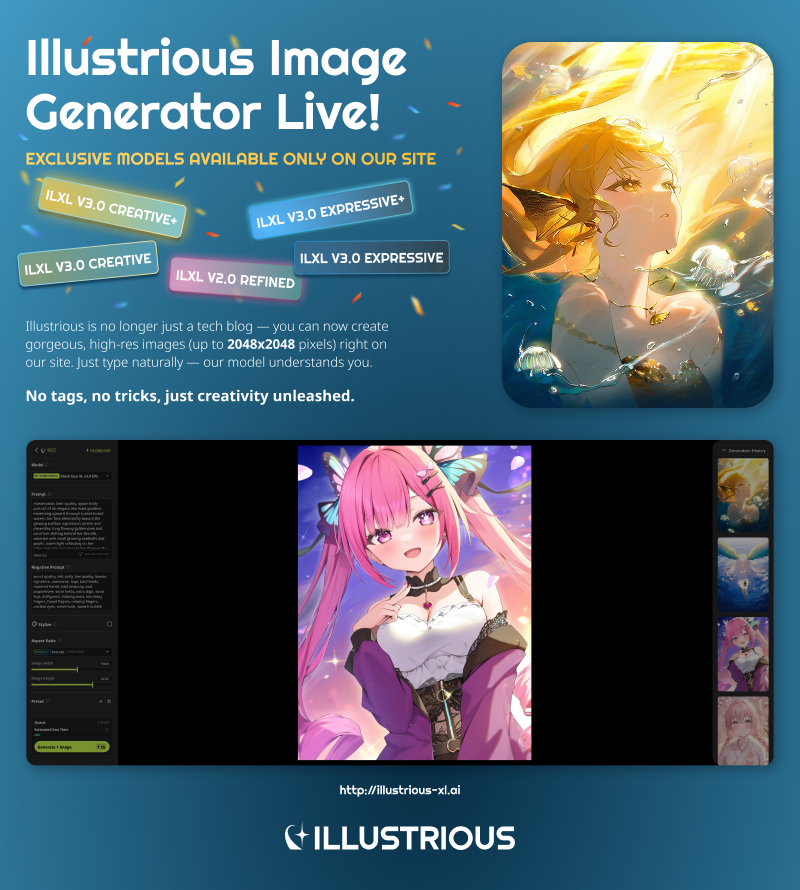 Odwiedź naszą stronę, aby zobaczyć, nad czym pracujemy i poznać nasz najnowszy model!
Odwiedź naszą stronę, aby zobaczyć, nad czym pracujemy i poznać nasz najnowszy model!
→https://www.illustrious-xl.ai/
Z radością informujemy, że teraz możesz generować obrazy bezpośrednio za pomocą naszych modeli Illustrious XL na naszej oficjalnej stronie: [illustrious-xl.ai]. Uruchomiliśmy pełną platformę generowania obrazów z wysoką rozdzielczością, obsługą języka naturalnego i niestandardowymi ustawieniami — oraz kilkoma ekskluzywnymi modelami, których nie znajdziesz na żadnym innym portalu. Poznaj nasze zaktualizowane poziomy modeli i nazewnictwo tutaj: [Model Series]. Potrzebujesz pomocy przy rozpoczęciu? Zapoznaj się z naszym przewodnikiem użytkownika generowania obrazów: [ILXL Image Generation User Guide].
Illustrious XL v1.0 – model generatywny skupiony na ilustracjach w wysokiej rozdzielczości
Przegląd
Illustrious XL v1.0 to zaawansowany model generatywny opracowany przez OnomaAI, oparty na architekturze Stable Diffusion XL, wytrenowany na bazie naszego poprzedniego checkpointu, Illustrious XL v0.1, zaprojektowany do tworzenia oszałamiających obrazów w wysokiej rozdzielczości. Osiąga niespotykaną dotąd natywną rozdzielczość 1536×1536 w ramach SDXL, przekraczając wcześniejsze limity detali i klarowności. Model płynnie łączy rozumienie języka naturalnego z tagami w stylu Danbooru, umożliwiając stosowanie zarówno opisów tekstowych, jak i konkretnych tagów, dla elastycznego i skutecznego przetwarzania promptów. W efekcie, Illustrious XL v1.0 to potężna podstawa dla twórców poszukujących wszechstronności w generowaniu treści bez utraty jakości.
Zakres wiedzy
Illustrious XL v1.0 jest wytrenowany w lipcu 2024 roku, z wiedzą sięgającą czerwca 2024.
Jednak dzięki natywnej obsłudze LoRA w wersji 0.1, nie musisz martwić się ograniczeniami wiedzy!
Kluczowe cechy
Natywna rozdzielczość 1536×1536:
Pionierski model Stable Diffusion XL obsługujący natywnie rozdzielczość 1536 px. Generuje obrazy o wyjątkowej szczegółowości, ostrości i klarowności w wysokich rozdzielczościach, które wcześniej były niedostępne w SDXL. Obsługuje szeroki zakres rozdzielczości od 512x512 do 1536x1536 — rozdzielczości takie jak 1248x1824 są możliwe do uzyskania bez żadnych modyfikacji wysokiej rozdzielczości.
Wskazówki oparte na NLP + tagach:
Integruje zaawansowane przetwarzanie języka naturalnego wraz z promptami opartymi na tagach Danbooru. Podejścia tagowe są bardziej zwięzłe i precyzyjne, jednak ten hybrydowy system promptów pozwala używać opisów w czystym angielskim lub precyzyjnych tagów (albo obu) – model rozumie i wykorzystuje oba, dając Ci większą kontrolę i niuanse w generowaniu obrazów.
Szeroka kompatybilność:
W pełni kompatybilny z szerokim zakresem rozszerzeń i dodatków. Moduły LoRA, ControlNet i inne metody adaptacji wytrenowane na Illustrious v0.1 działają bezproblemowo z wersją 1.0. Możesz łączyć i dopasowywać ulepszenia, aby dostosować styl, pozę lub kompozycję bez utraty kompatybilności.
Wstępnie wytrenowany model bazowy:
Illustrious XL v1.0 jest udostępniany jako wstępnie wytrenowany checkpoint bazowy, bez dodatkowego dostosowywania pod kątem konkretnych estetyk czy uprzedzeń. Ten „surowy” model oferuje solidną podstawę do dalszego treningu – idealną dla twórców chcących zastosować własne fine-tuning (np. szkolenie LoRA) w celu osiągnięcia określonych stylów artystycznych lub specjalistycznych wyników. To elastyczny punkt startowy dla nowych innowacji.
Plany na przyszłość
Wyższe rozdzielczości w wersjach v2/v3:
W planach są nadchodzące wydania wersji Illustrious XL v2 i v3, które będą wspierać jeszcze większe rozdzielczości, celując w rozdzielczość do 2k i więcej. Spodziewaj się jeszcze więcej detali i możliwości skalowania, umożliwiających ultra-ostre obrazy w dużym formacie.
Modele z parametryzacją v oraz kontrola kolorów:
Gotowa jest specjalistyczna wariacja z parametryzacją v, która przełamuje wcześniej uważane za granice SD XL, zarówno teoretycznie, jak i praktycznie. W przyszłych wydaniach planowane jest również skupienie na rozszerzonej kontroli kolorów, dającej użytkownikom precyzyjne dostosowanie balansu i spójności kolorów w generowanych obrazach.
Stałe ulepszanie:
Mapa drogowa Illustrious jest ambitna – każda iteracja będzie integrować opinie społeczności i najnowsze badania. Kontynuujemy badania nad wysoką rozdzielczością, przełamując dotychczasowe bariery z zachowaniem staranności i zaawansowanych metod.
Illustrious v0.1 (huggingface) | OnomaAI TooToon | Warunki użytkowania

Szczegóły modelu
Dyskusja
Proszę się log in, aby dodać komentarz.




