kegant - v1.0 / PDXL
Powiązane słowa kluczowe i tagi
Wyróżnione obrazy

Zalecane podpowiedzi
score_9, score_8_up, score_7_up, score_6_up, score_5_up, score_4_up, solo
Zalecane negatywne podpowiedzi
dark,night,blur,jpeg artifacts,plants,flowers,cyberpunk,1girl
3d
Zalecane parametry
samplers
steps
cfg
resolution
Zalecane parametry wysokiej rozdzielczości
upscaler
upscale
steps
Wskazówki
Używaj 'dark' lub 'night' w negatywnych promptach, aby unikać zbyt ciemnych obrazów.
Dodaj 'blur' w negatywnym prompcie, aby zmniejszyć silne efekty głębi ostrości.
Pełne sylwetki są trudne do uzyskania; określ 'shoes', 'boots' lub 'feet/toes', aby poprawić wyniki.
Używaj prostych face detailerów dla lepszych twarzy na ujęciach z daleka; działają szybciej niż latent upscalery.
Obniż CFG i liczbę kroków w latent upscalerze dla miększego, 'malowanego' wyglądu mgły; wyższe CFG daje bardziej błyszczący, 'upieczony' wygląd.
Unikaj przeciążania promptów; czasem mniej znaczy więcej w tagowaniu w stylu danbooru.
Dodaj 'jpeg artifacts', 'plants', 'flowers' i 'cyberpunk' do negatywnych promptów, aby usunąć niechciane artefakty.
Określenie '1girl' w negatywnych promptach pomaga generować męskie postacie.
Najważniejsze informacje o wersji
to jest proste połączenie. nie było w tym przypadku żadnego treningu.
kegant
✨ prosty workflow comfyui: ✨ https://civitai.com/models/861472?modelVersionId=963859
AKTUALIZACJA V4: V4 bazuje w dużej mierze na zbiorze danych V3, chociaż niektóre obrazy zostały usunięte, co najważniejsze to przejście z pony na noobai-vpred jako model bazowy. Dlatego stosuj się do konwencji odpowiednich dla treningu noobai, z poprawnym tagowaniem w stylu danbooru. Aby uzyskać pomoc, zobacz niektóre z moich opublikowanych obrazów z przykładami stylów tagowania, które zwykle umieszczam na początku promptów. Ta wersja nie jest doskonała i prawdopodobnie będzie wymagać korekty, ponieważ niektóre tagi, takie jak blur i darkness, nadal sprawiają problemy (wiele generowanych obrazów będzie dość ciemnych). Używaj słów takich jak 'dark' lub 'night' w negatywnych promptach, jeśli obrazy utkwią w ciemnej fazie, lub 'blur', jeśli efekt głębi ostrości jest zbyt silny i to naprawi problem. Przejście z pony na NAIXL wiąże się z dużymi kompromisami, zwłaszcza w obszarach, które bardzo kocham, takich jak oświetlenie, bokeh, rozmycie i inne efekty kamery, na których oparty był kegant od v1. Żaden z pokazywanych obrazów nie był przerabiany w Photoshopie czy edytowany po comfy, ani i2i, ale używam face detailera. Ten checkpoint gorzej radzi sobie niż poprzednie pony z ujęciami z daleka, takimi jak 'full_body' czy 'wide_angle'. Używaj prostego face detailera, jego konfiguracja nie jest trudna, działają szybciej niż latent upscalery i zdecydowanie poprawiają twarze z daleka. Korzystam z tego przewodnika (i działa świetnie):
https://www.youtube.com/watch?v=gDBeKIa4sHA
AKTUALIZACJA V3: V3 to głównie aktualizacja potworów, z kilkoma cameo, ale co ważniejsze, oferuje dokładniejszą kontrolę nad elementami artystycznymi. Zrobiłem w tej wersji szalone rzeczy, jak ręczna edycja wielu źródłowych obrazów w GIMP, aby usunąć jak najwięcej artefaktów jpeg. Znaki wodne są nieobecne i nie trzeba ich tagować negatywnie, problem z roślinami i fauną został rozwiązany, a mam nadzieję, że męskie postacie generują się łatwiej, ponieważ dodałem ich wiele. Pełna lista tagów zawarta jest w sekcji 'about the version'. Wiele obrazów w v3 ma potężne tagi, takie jak 'film grain, halftone effect, dark fantasy, muted colors, sepia'. Często ich używam, ponieważ obrazy wyjściowe moich promptów zawierały te elementy. Jeśli nie chcesz ich widzieć i zamiast tego wolisz standardowe anime, używaj tych tagów w negatywnych promptach. Styl jest tak silny, że może się rozlać jeśli nie podasz promptu. Dodano bronie, takie jak miecze, 'massive sword' Guts'a oraz katana (od Cis). Generowanie obrazów z bronią zawsze będzie trudne ze względu na ograniczenia SDXL, ale mam nadzieję, że dodane obrazy katan i mieczy pomogą modelowi osiągać bardziej dokładne pozy z nimi.
AKTUALIZACJA V2: V2 to pierwsza wersja, którą trenowałem i wpływałem na nią ręcznie. Nadal bazuje głównie na stacku z V1, ale niektóre wagi zostały obniżone, a dodane przeze mnie obrazy i trening naprawiły niektóre problemy V1. V2 skupia się bardziej na stylu oświetlenia pustynnego i efektach, a także lekko zmienia styl artystyczny na trochę mniejsze oczy i mniejsze usta. Oświetlenie w tej wersji jest jeszcze bardziej ekstremalne i mam wrażenie, że gdybym próbował robić więcej z oświetleniem, wszystko by się zawaliło. Można to nazwać aktualizacją kegant dune.
kegant PDXL to model oparty na pony, skupiający się na przekształceniu pony w bardziej retro i surowy wygląd przy silnym nacisku na efekty świetlne.
Skupia się głównie na pieczonych wersjach 5 oddzielnych loranów i 1 embeddingu w modelu ponyv6. Te modele to:
https://civitai.com/models/366990/pony-custom-styles?modelVersionId=454703
https://civitai.com/models/341353/expressiveh-hentai-lora-style?modelVersionId=382152
https://civitai.com/models/550871/bss-styles-for-pony?modelVersionId=669776
https://civitai.com/models/122359/detail-tweaker-xl?modelVersionId=135867
https://civitai.com/models/118418/negativexl?modelVersionId=134583
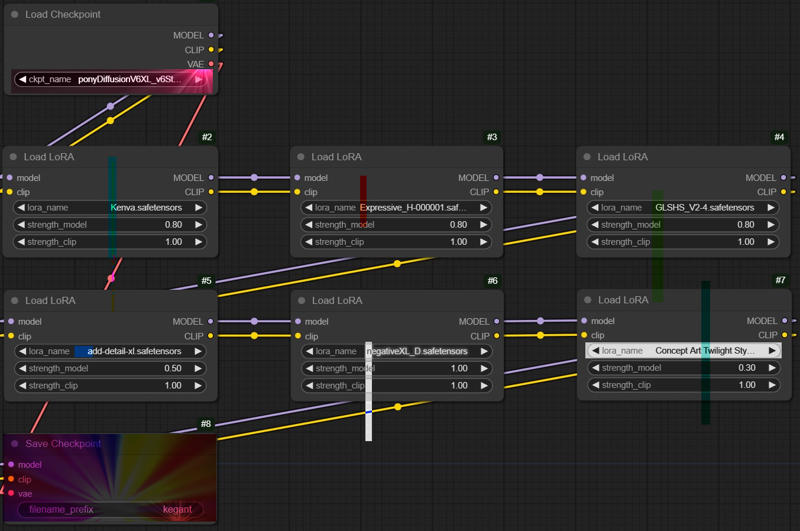 Jeśli nie widzisz obrazka, podczas łączenia zastosowano następujące ustawienia:
Jeśli nie widzisz obrazka, podczas łączenia zastosowano następujące ustawienia:
Kenva: .8
ExpressiveH: .8
GLSHS: .8
add_detail: .5
negativeXL_D: 1
Concept Art Twilight: .3
Proszę pamiętać, że model ma tendencję do generowania kobiet i preferuje postaci nie za daleko i nie za blisko. Tworzenie pełnych sylwetek może być trudne, ale jeśli określisz słowa takie jak 'shoes', 'boots' lub 'feet'/'toes', model jest bardziej skłonny do generowania pełnych sylwetek, których oczekujesz. Pamiętaj — To jest checkpoint oparty na pony. Preferuje tagowanie w stylu danbooru zamiast zwykłego angielskiego. Czasem mniej znaczy więcej. Przeciążanie prompta zbyt wieloma tagami utrudnia mu zrozumienie, co robić. Jeśli pełne sylwetki są dla Ciebie ważne, umieść ten tag na początku promptu, ponieważ im wyżej w promptcie coś się znajduje, tym więcej uwagi mu poświęca. Możesz też nadać temu tagowi wagę ręcznie, co jeszcze bardziej pomoże. Udostępniam wszystkie moje promptowe przykłady dla tego checkpointu, jeśli szukasz wskazówek.
Mimo to, ten checkpoint nie jest tak elastyczny jak goat (aka v6), ale za elastyczność płacisz mniej oświetleniem, stylem artystycznym i szybkością generowania. Generowanie tego samego zestawu obrazów ze wszystkimi zintegrowanymi lorasami jest około 3 razy szybsze w porównaniu do robienia tego z v6 i całym stackiem, co było głównym celem tego checkpointu.
✨ Proszę, dzielcie się swoimi świetnymi dziełami poniżej! ✨
Dziękuję wszystkim za wypróbowanie mojego pierwszego checkpointu.
Proszę odnieść się do strony Pony V6 dla bardziej szczegółowych wytycznych dotyczących promptów.
☄️ Zalecenia dotyczące generowania
* Wszystkie podglądowe obrazy zostały wygenerowane bez LORA, oprócz dwóch ostatnich z Haruko Haruhara i Lain, ponieważ pony nie zna tych postaci, które są bardzo stylizowane i trudne do promptowania samodzielnie. Nie użyto innych zasobów, tylko czysty tekst do obrazu z drugim etapem latentnego upscale (bez pixel upscalingu).
Większość przykładowych obrazów wygenerowano metodami ancestral samplers następujących typów na pierwszym przejściu:
Sampler: Euler A / DPM++A
Typ harmonogramu: Karras
Kroki: 20 - 30
CFG: 2 - 6
Clip Skip: 2
Denoise: 1
Użyty latentny upscaler był podobny do powyższego, zazwyczaj wybierano wariant Eulera, gdyż jest zwykle szybszy w generacji obrazów.
Sampler: Euler A / DPM++A
Typ harmonogramu: Karras
Kroki: 15
CFG: 2 - 6
Denoise - 0.5
Upscale przez: 1.5-2.0
Aby uzyskać wskazówki dotyczące generowania, im niższy CFG na latentnym upscalerze (i kroki), tym bardziej obraz będzie wyglądał na 'malowany', z miękkimi, mniej wyraźnymi cechami, co tworzy efekt 'mgły' na niektórych obrazach. Odwrotnie, im wyższy CFG, tym bardziej obraz wygląda na 'upieczony' i błyszczący. CFG 3.0 to prawdopodobnie najlepszy kompromis między wszystkimi lorami, który akcentuje je najlepiej. W przypadku dołączonego obrazka Harley Quinn użyłem ustawienia 10 CFG, aby pokazać, jak to wygląda, chociaż jest to bardzo abstrakcyjne.
PROSZĘ zapoznaj się z moim dołączonym workflow, który pokazuje, jak możesz w pełni wykorzystać kegant, czy preferujesz elegancki, błyszczący design, czy miękkie, ekstremalne retro klimaty z efektami ziarna filmu.
Ostatnia uwaga - ten checkpoint ma tendencję do dodawania 'artefaktów jpeg' oraz różnych elementów fauny takich jak 'rośliny' i 'kwiaty'. Również ma tendencję do dodawania elementów 'cyberpunk'. Dodaj te słowa do negatywnych promptów jeśli chcesz ich uniknąć, powinno to pomóc je usunąć. W przypadku prac z męskimi postaciami, określenie '1girl' w negatywnych promptach bardzo pomaga, chociaż checkpoint, jak wspomniano, bardzo preferuje kobiety.

Szczegóły modelu
Dyskusja
Proszę się log in, aby dodać komentarz.
Kolekcja modeli - kegant

Obrazy autorstwa kegant - v1.0 / PDXL
Obrazy z anime










Obrazy z surowy










Obrazy z oświetlenie










Obrazy z retro










Obrazy z styl









