SD XL - v1.0 Poprawka VAE
Powiązane słowa kluczowe i tagi
Wyróżnione obrazy












Zalecane negatywne podpowiedzi
(deformed iris, deformed pupils), text, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, (extra fingers), (mutated hands), poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, (fused fingers), (too many fingers), long neck, camera
Zalecane parametry
samplers
steps
cfg
resolution
Wskazówki
Model jest przeznaczony do celów badawczych, w tym generowania dzieł sztuki, narzędzi edukacyjnych oraz bezpiecznego wdrażania.
Nie służy do generowania faktograficznych lub prawdziwych reprezentacji ludzi czy zdarzeń.
Ograniczenia obejmują niedoskonały fotorealizm, brak możliwości generowania czytelnego tekstu, trudności z kompozycyjnymi promptami oraz możliwe błędy w generowaniu twarzy.
Model korzysta z dwóch wstępnie wytrenowanych enkoderów tekstowych: OpenCLIP-ViT/G oraz CLIP-ViT/L.
Proces dwustopniowy obejmuje generowanie latentów bazowych, a następnie wyrafinowanie wysokiej rozdzielczości za pomocą SDEdit (img2img).
Sponsorzy twórcy
Pierwotnie Opublikowane na Hugging Face i udostępnione tutaj za zgodą Stability AI.
Pierwotnie Opublikowane na Hugging Face i udostępnione tutaj za zgodą Stability AI.
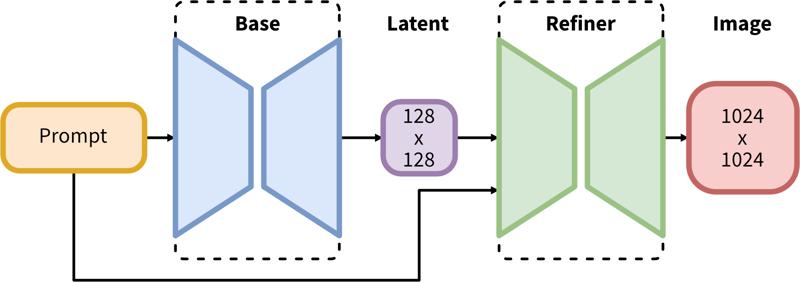
SDXL składa się z dwustopniowego procesu latentnej dyfuzji: najpierw używamy modelu bazowego do generowania latentów o pożądanym rozmiarze wyjściowym. W drugim kroku korzystamy ze specjalistycznego modelu wysokiej rozdzielczości i stosujemy technikę zwaną SDEdit (https://arxiv.org/abs/2108.01073, znaną również jako "img2img") do latentów wygenerowanych w pierwszym kroku, używając tego samego promptu.
Opis Modelu
Opracowany przez: Stability AI
Typ modelu: Model generatywny tekst-na-obraz oparty na dyfuzji
Opis modelu: Jest to model umożliwiający generowanie i modyfikowanie obrazów na podstawie promptów tekstowych. To Latent Diffusion Model, wykorzystujący dwa stałe, wstępnie wytrenowane enkodery tekstowe (OpenCLIP-ViT/G i CLIP-ViT/L).
Zasoby z dodatkowymi informacjami: Repozytorium GitHub.
Źródła Modelu
Repozytorium: https://github.com/Stability-AI/generative-models
Demo [opcjonalnie]: https://clipdrop.co/stable-diffusion
Zastosowania
Bezpośrednie użycie
Model jest przeznaczony wyłącznie do celów badawczych. Możliwe obszary badań i zadania to:
Generowanie dzieł sztuki oraz użycie w projektowaniu i innych procesach artystycznych.
Zastosowania w narzędziach edukacyjnych lub kreatywnych.
Badania nad modelami generatywnymi.
Bezpieczne wdrażanie modeli mających potencjał do generowania szkodliwych treści.
Badanie i rozumienie ograniczeń oraz uprzedzeń modeli generatywnych.
Wykluczone zastosowania opisane są poniżej.
Użycie poza zakresem
Model nie był trenowany, aby generować faktyczne lub prawdziwe odwzorowania ludzi czy zdarzeń, dlatego używanie go do tworzenia takich treści wykracza poza możliwości tego modelu.
Ograniczenia i uprzedzenia
Ograniczenia
Model nie osiąga idealnego fotorealizmu
Model nie potrafi generować czytelnego tekstu
Model ma trudności z bardziej złożonymi zadaniami wymagającymi kompozycyjności, jak np. wygenerowanie obrazu odpowiadającego „czerwonemu sześcianowi na niebieskiej kuli”
Twarze i ludzie ogólnie mogą nie być generowani poprawnie.
Część autoenkodera modelu jest stratna.
Uprzedzenia
Pomimo imponujących możliwości generowania obrazów, modele te mogą wzmacniać lub potęgować społeczne uprzedzenia.
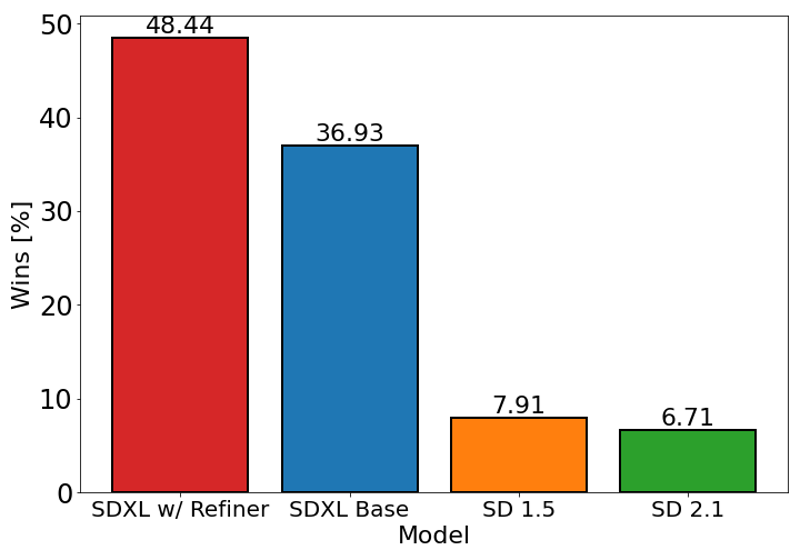
Wykres powyżej ocenia preferencje użytkowników dla SDXL (z i bez wyrafinowania) w porównaniu do Stable Diffusion 1.5 i 2.1. Model bazowy SDXL radzi sobie znacząco lepiej niż poprzednie wersje, a model połączony z modułem wyrafinowania osiąga najlepsze wyniki ogólne.

Szczegóły modelu
Typ modelu
Model bazowy
Wersja modelu
Hash modelu
Dyskusja
Proszę się log in, aby dodać komentarz.










