Stable Cascade - baza
Powiązane słowa kluczowe i tagi
Wyróżnione obrazy


Zalecane parametry
steps
resolution
Wskazówki
Używaj wersji Etapu C z 3,6 miliardami parametrów dla najlepszych wyników, ponieważ główne finetuning wykonano na niej.
Wariant Etapu B z 1,5 miliarda parametrów doskonale odtwarza małe i drobne detale.
Model jest dobrze przystosowany do efektywnego trenowania i wnioskowania dzięki mniejszej przestrzeni latentnej i obsługuje rozszerzenia takie jak finetuning, LoRA, ControlNet, IP-Adapter i LCM.
Model jest przeznaczony wyłącznie do celów badawczych i nie powinien być używany do generowania prawdziwych reprezentacji ani naruszania Polityki Akceptowalnego Użytku Stability AI.
Twarze i ludzie mogą nie być generowani poprawnie, ponieważ autoenkodowanie modelu jest stratne.
Sponsorzy twórcy
Demonstracje:
- multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
- ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Demonstracje:
multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Stable Cascade
Model ten jest oparty na architekturze Würstchen, a jego główną
różnicą w stosunku do innych modeli, takich jak Stable Diffusion, jest działanie w znacznie mniejszej przestrzeni latentnej. Dlaczego to
jest istotne? Im mniejsza przestrzeń latentna, tym szybsze można przeprowadzać wnioskowanie i tańsze staje się trenowanie.
Jak mała jest ta przestrzeń latentna? Stable Diffusion używa współczynnika kompresji 8, co powoduje, że obraz 1024x1024 jest
kodowany do rozmiaru 128x128. Stable Cascade osiąga współczynnik kompresji 42, co oznacza możliwość zakodowania obrazu
1024x1024 do 24x24, zachowując przy tym ostre rekonstrukcje. Model warunkowany tekstem jest trenowany w
silnie skompresowanej przestrzeni latentnej. Poprzednie wersje tej architektury osiągnęły 16-krotną redukcję kosztów względem Stable
Diffusion 1.5. <br> <br>
Dlatego ten rodzaj modelu jest dobrze dopasowany do zastosowań, w których ważna jest wydajność. Ponadto wszystkie znane rozszerzenia
takie jak finetuning, LoRA, ControlNet, IP-Adapter, LCM itd. są możliwe również z tym podejściem.
Szczegóły modelu
Opis modelu
Stable Cascade to model dyfuzyjny trenowany do generowania obrazów na podstawie tekstowego opisu.
Opracowany przez: Stability AI
Finansowany przez: Stability AI
Typ modelu: Generatywny model tekst-na-obraz
Źródła modelu
Na potrzeby badań polecamy nasze StableCascade repozytorium Github (https://github.com/Stability-AI/StableCascade).
Repozytorium: https://github.com/Stability-AI/StableCascade
Przegląd modelu
Stable Cascade składa się z trzech modeli: Etap A, Etap B i Etap C, tworzących kaskadę do generowania obrazów,
skąd pochodzi nazwa „Stable Cascade”.
Etapy A i B służą do kompresji obrazów, podobnie jak zadanie VAE w Stable Diffusion.
Jednak dzięki temu rozwiązaniu można osiągnąć znacznie wyższą kompresję obrazów. Podczas gdy modele Stable Diffusion używają
czynnika kompresji przestrzennej 8, kodując obraz o rozdzielczości 1024 x 1024 do 128 x 128, Stable Cascade osiąga
czynnik kompresji 42. To koduje obraz 1024 x 1024 do 24 x 24, przy jednoczesnym dokładnym dekodowaniu
obrazu. Przynosi to wielką korzyść w postaci tańszego trenowania i wnioskowania. Ponadto, etap C odpowiada
za generowanie małych latentów 24 x 24 na podstawie tekstowego opisu. Poniższe zdjęcie pokazuje to wizualnie.
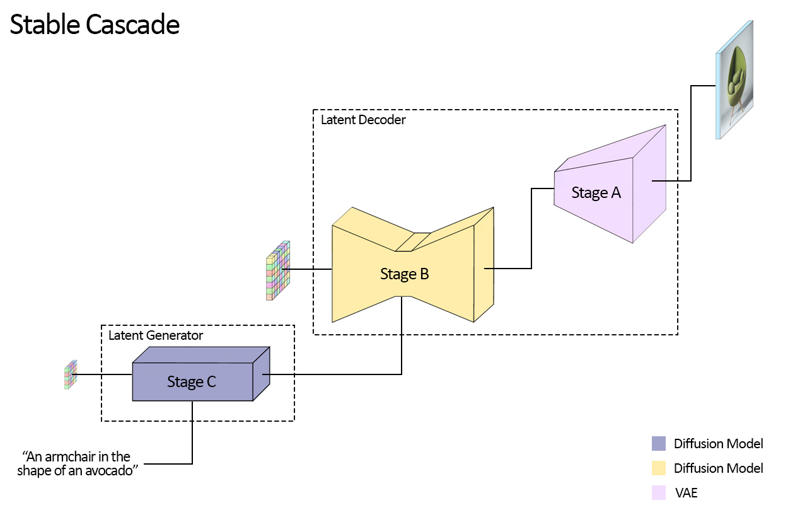
Na tę wersję udostępniamy dwa checkpointy dla Etapu C, dwa dla Etapu B i jeden dla Etapu A. Etap C ma wersję z
1 miliardem oraz 3,6 miliardem parametrów, ale zdecydowanie zalecamy użycie wersji 3,6 miliarda, ponieważ na niej wykonano główne finetuning.
Dwie wersje Etapu B zawierają odpowiednio 700 milionów i 1,5 miliarda parametrów. Obie osiągają
świetne wyniki, jednak wariant 1,5 miliarda wyróżnia się w odtwarzaniu małych i drobnych detali. Dlatego uzyskasz
najlepsze efekty, używając większej wersji każdego z etapów. Na koniec, etap A zawiera 20 milionów parametrów i jest stały ze względu na
swoją niewielką wielkość.
Ocena
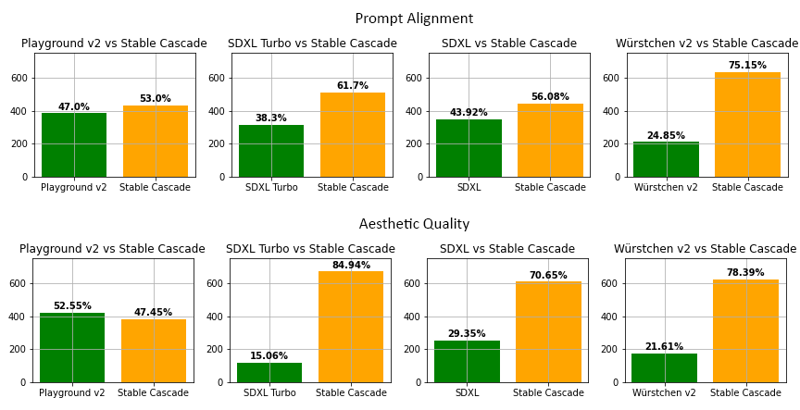
Według naszych ocen, Stable Cascade wypada najlepiej zarówno pod względem zgodności z opisem, jak i jakości estetycznej w prawie wszystkich
porównaniach. Powyższe zdjęcie przedstawia wyniki oceny ludzkiej, używającej mieszanki parti-prompts (link) i estetycznych promptów. Konkretne porównanie Stable Cascade (30 kroków wnioskowania) z Playground v2 (50 kroków wnioskowania), SDXL (50 kroków wnioskowania), SDXL Turbo (1 krok wnioskowania) oraz Würstchen v2 (30 kroków wnioskowania).
Przykład kodu
⚠️ Ważne: Aby poniższy kod działał, musisz zainstalować diffusers z tej gałęzi podczas gdy PR jest w toku.
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Anthropomorphic cat dressed as a pilot"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
#Teraz decoder_output to lista z twoimi obrazami PILZastosowania
Bezpośrednie użycie
Model jest obecnie przeznaczony wyłącznie do celów badawczych. Możliwe obszary badań i zadania obejmują
Badania nad modelami generatywnymi.
Bezpieczne wdrażanie modeli, które mogą generować szkodliwe treści.
Analizowanie i rozumienie ograniczeń oraz uprzedzeń modeli generatywnych.
Generowanie dzieł sztuki oraz zastosowanie w projektowaniu i innych procesach artystycznych.
Zastosowania w narzędziach edukacyjnych lub kreatywnych.
Wyłączone zastosowania opisano poniżej.
Zastosowania poza zakresem
Model nie był trenowany do wiernego lub prawdziwego odzwierciedlania ludzi lub wydarzeń,
dlatego używanie modelu do generowania takich treści jest poza jego możliwościami.
Model nie powinien być używany w sposób naruszający Politykę Akceptowalnego Użytku Stability AI.
Ograniczenia i uprzedzenia
Ograniczenia
Twarz i ludzie w ogóle mogą nie być generowani poprawnie.
Część autoenkodująca modelu jest stratna.
Rekomendacje
Model przeznaczony jest wyłącznie do celów badawczych.
Jak zacząć pracę z modelem

Szczegóły modelu
Typ modelu
Model bazowy
Wersja modelu
Hash modelu
Twórca
Dyskusja
Proszę się log in, aby dodać komentarz.
Kolekcja modeli - Stable Cascade
Obrazy autorstwa Stable Cascade - baza
Obrazy z anime










Obrazy z sztuka










Obrazy z model bazowy

Obrazy z logo










