AlbedoBase XL - v1.1
Palavras-chave e Tags Relacionadas
Imagens em destaque



Prompts Negativos Recomendados
strabismus
inconsiderate details
Parâmetros Recomendados
samplers
steps
cfg
resolution
vae
Parâmetros Recomendados para Alta Resolução
upscaler
upscale
steps
denoising strength
Dicas
Se a geração de imagem não produzir resultado, tente mudar para CLIP SKIP 2 ou modificar levemente o prompt, alterando a ordem ou as palavras.
Usar prompts em forma de frase tende a melhorar a qualidade da imagem mais do que usar listas de tags.
Deixar o campo de prompt negativo vazio frequentemente gera melhores resultados nas imagens.
Verifique a grade de especificações para configurações ideais antes de usar.
Experimente alguns prompts negativos específicos como 'estrabismo' para resolver problemas como olhos assimétricos ou pixelização.
Destaques da Versão
v1.1
Estabilizado.
Mais detalhado.
Se você se considera um usuário avançado, recomendo a versão 1.0. Se a versão 1.0 encontrar as configurações corretas, pode gerar obras muito mais vívidas.
A grade de especificações (349.7 MB): download
Patrocinadores do Criador
Se você encontrou valor no modelo, por favor considere oferecer seu apoio. Sua contribuição será inteiramente dedicada ao avanço da comunidade SDXL.
Se você encontrou valor no modelo, por favor considere oferecer seu apoio. Sua contribuição será inteiramente dedicada ao avanço da comunidade SDXL.
🙋🏼♂️ junte-se a nós (discord) ㅤ|ㅤ 🛒 comprarㅤ |ㅤ 🌱 doar
AlbedoBase XL (SFW&NSFW)
O refinador é desnecessário, e o VAE está incluído.
OBJETIVO
Stable Diffusion XL tem 3,5 bilhões de parâmetros (excluindo o refinador), cerca de 3,6 vezes mais que a versão SD v1.5. Acredito que isso não é apenas um número, mas um número que pode resultar em uma melhoria significativa de desempenho.
Faz um tempo que percebemos que o desempenho geral do SD v1.5 melhorou além da imaginação graças às contribuições explosivas da nossa comunidade. Por isso, estou trabalhando para concluir este modelo AlbedoBase XL a fim de reproduzir de forma ideal a melhoria de desempenho ocorrida no v1.5 também nesta versão XL.
Meu objetivo é testar diretamente o desempenho de todos os Checkpoints e LoRAs publicados publicamente no Civitai e combinar somente os recursos julgados ótimos após passarem por vários filtros. Isso vai superar o desempenho de IA’s geradoras de imagens de empresas como Midjourney.
Até o momento, o AlbedoBase XL v3.1 Large tem cerca de 200 checkpoints selecionados e 251 LoRAs combinados.
LOG
v3.1-Large
• Combinou mais de 50 versões selecionadas dos modelos SDXL mais recentes usando o script recursivo empregado na V3.
A grade de especificações (370.7 MB): download


v3-mini
Peço sinceras desculpas por mantê-los esperando tanto tempo.
Estive lidando com alguns assuntos pessoais e, enquanto trabalhava na nova versão, também enfrentei problemas de saúde. Mesmo ao escrever isto, ainda estou lutando contra esses desafios.
Senti que não seria suficiente apenas fornecer uma breve atualização, portanto peço sua compreensão ao compartilhar esta mensagem mais detalhada.
Desde o lançamento da versão 2.0, venho me dedicando a estudar deep learning de forma autodidata. Não tenho um diploma formal e, além de uma aptidão modesta para programação, meu histórico é nas artes. Por isso, me falta a base matemática e científica para grandes avanços, dado o tempo e esforço que investi. Apesar disso, a experiência de imergir nesse estudo e pesquisa autodirigidos tem sido um tesouro inestimável na minha vida.
Recentemente, encontrei uma ideia que pode ser um avanço significativo. Depois de revisar centenas de fórmulas e métodos desde a versão 2.0, desenvolvi um algoritmo bastante intrigante e bem-sucedido. O processo de mesclagem de modelos foi baseado no SDXL1.0 e SD1.5, junto com outros modelos criteriosamente selecionados. Estes foram categorizados em cinco classificações principais: “ANIME,” “REALISMO,” “ARTÍSTICO,” “NSFW,” e “BASE,” e alimentados no algoritmo de mesclagem como conjuntos de dados. Essa abordagem resultou em desfechos fascinantes.
No entanto, por mais desafiador que tenha sido desenvolver o algoritmo, nada foi tão árduo quanto a fase de testes de desempenho. Minha saúde física e mental se deteriorou significativamente nesse período, a ponto de perceber que não conseguiria continuar esse trabalho sozinho. Isso me levou a decidir lançar esta versão.
E agora, estou entusiasmado para anunciar o lançamento da tão aguardada versão AlbedoBaseXL V3 Mini. Embora este modelo seja uma mesclagem em menor escala, não está limitado a nenhuma área específica e apresenta desempenho notável em vários domínios. Tem potencial para servir como novo modelo base para o SDXL1.0. (Para referência, meu algoritmo de mesclagem não é uma “mesclagem linear,” então pode ser basicamente considerado um novo modelo fine-tuned.)
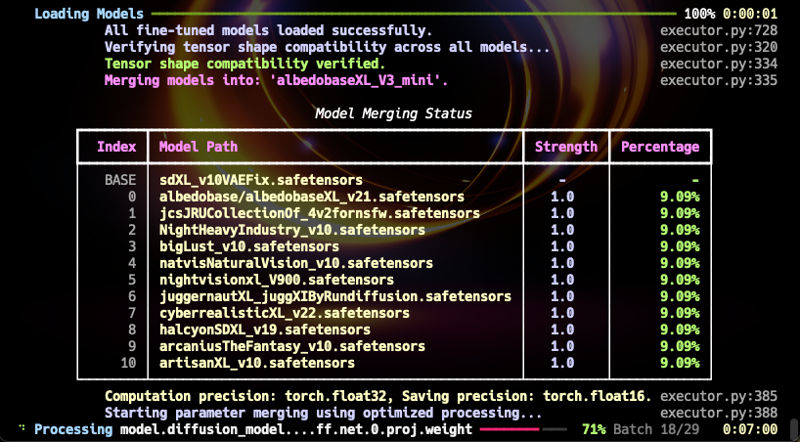
Este modelo, junto com os modelos AlbedoBase existentes, é versátil e supera todas as versões anteriores em todos os aspectos. (O conteúdo NSFW, embora não extremo, oferece uma gama mais ampla de expressão comparado a versões anteriores como v2.1. Um modelo dedicado à mesclagem NSFW será lançado futuramente.)
Por outro lado, notei que muitos modelos compartilhados recentemente começaram a adotar licenças que proíbem mesclagem ou comercialização externa. Isso tem sido decepcionante, pois me impediu de usar alguns modelos excelentes para mesclagem.
Gostaria de expressar minha sincera gratidão aos desenvolvedores de modelos que forneceram licenças gratuitas, permitindo que seus modelos de alta qualidade — frutos de considerável tempo e esforço — possam ser usados para mesclagem.
Voltarei em breve.
Aguardo ansiosamente seus testes de desempenho em uma ampla gama de áreas, incluindo ANIME, REALISMO, ARTÍSTICO, 2.5D, 3D e NSFW.
Como desenvolvedores de modelos, apenas plantamos as sementes. Vocês, usuários e artistas dos modelos, são quem as cultivam e fazem florescer.
Obrigado, como sempre.
Para quem desejar apoiar meu trabalho com uma pequena contribuição financeira, considere utilizar os links abaixo. Atualmente não consigo garantir emprego e enfrento um futuro incerto em relação ao meu sustento.
A grade de especificações (380.5 MB): download


v2.1
Recompilar e ajustar v0.1 a 2.0 usando novo algoritmo e fórmula de mesclagem.
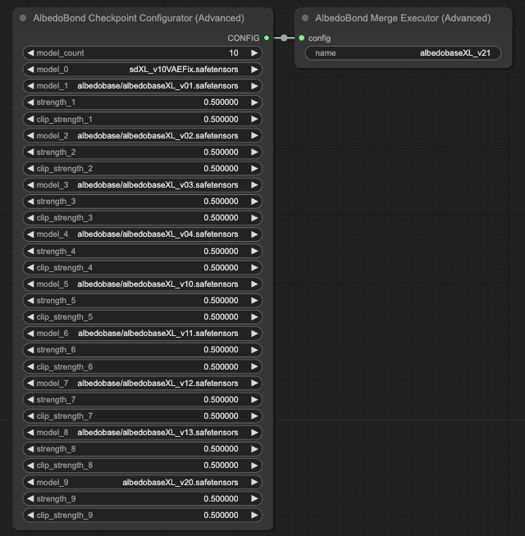
A grade de especificações (424.5 MB): download

v2.0
Gostaria de agradecer a todos que me ajudaram no lado AlbedoBase XL Pre. Sem vocês, a data de lançamento provavelmente teria sido muito mais tarde. Muito obrigado!
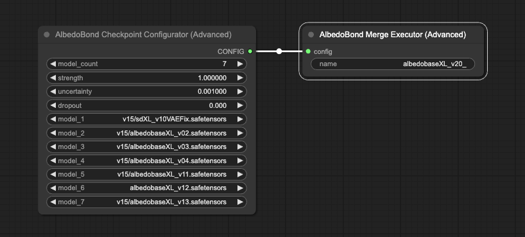
Escrevi um script personalizado para convergir os modelos existentes do AlbedoBase XL em um só. Alinhando intrinsecamente os pesos de linha e coluna de todos os blocos U-NET e CLIP conforme uma fórmula única minha.
Se você encontrar um bug na geração de imagens (se nada for gerado), por favor mude para CLIP SKIP 2 ou modifique um pouco o prompt! Pode haver combinações de prompts que o CLIP não reconhece. Nesse caso, pode-se mudar a ordem das palavras, usar palavras diferentes ou, mais simplesmente, alterar o CLIP SKIP. Trabalharei gradualmente para resolver esses problemas no futuro, como na v1.3.
A grade de especificações (403.5 MB): download
v1.3
Para ilustrar a qualidade associada à aleatoriedade do modelo, padronizei o valor de seed em '9' para todas as imagens de demonstração usadas para amostragem e as gerei imediatamente.
Especialmente nesta versão, devido ao impacto significativo dos prompts negativos, deixar o campo de prompt negativo vazio provavelmente produzirá resultado de boa qualidade.
A grade de especificações (438.7 MB): download

Como pode ver, conforme o número de Passos aumenta, torna-se compatível com todos os samplers, e a qualidade também melhora.
Devido ao efeito do LoRA que desenvolvi e combinei, como descrito abaixo, usar prompts em forma de frase, ao invés de lista de tags, está diretamente relacionado à melhoria da qualidade.
Combinei 45 checkpoints e 7 LoRAs. Depois disso, combinei AlbedoBase v0.4 e v0.3 em ordem, menos de 0~5%, para reativar os modelos diluídos e desatualizados da mesclagem.
Dentre os 7 LoRAs, um foi criado por mim. Ele envolve analisar e anotar legendas para um total de 174 fotos pictóricas de alta qualidade usando GPT4-V. A mesclagem deste LoRA resultou em imagens surpreendentemente claras e uma compreensão impressionante dos prompts.
Meus LoRAs criados por mim estão exclusivamente disponíveis para compra aos meus apoiadores Ko-fi no nível Creative ou superior.
v1.2
Combinei os 22 checkpoints mais recentes.
A grade de especificações (565.6 MB): download
v1.1
Estabilizado.
Mais detalhado.
Se você se considera um usuário avançado, recomendo a versão 1.0. Se a versão 1.0 encontrar as configurações corretas, pode gerar obras muito mais vívidas.
A grade de especificações (349.7 MB): download
v1.0
Combinei 106 LoRAs.
Combinei 19 Checkpoints.
O modelo pode produzir resultados diferentes dependendo das configurações escolhidas, por isso é importante verificar a grade de especificações antes de usá-lo.
Descobri que usar alguns prompts negativos específicos pode ajudar a resolver problemas como olhos assimétricos ou imagens pixeladas. A Grade de Especificações pode variar dependendo do seu dispositivo CPU ou GPU, por favor use como referência geral. Experimente alguns prompts negativos para melhorar a qualidade (ex: estrabismo). Notei que é difícil satisfazer todas as configurações igualmente à medida que o número de LoRAs combinados aumenta. Porém, quero que foquem nesta vantagem da versão 1.0, pois ela pode produzir obras com qualidade incrível em vários aspectos com as configurações certas. Voltarei com uma versão mais estável no futuro.
Você pode encontrar valores úteis de configuração nas demonstrações ou buscando por outros usuários.
Como sempre, é melhor deixar o prompt negativo em branco para melhores resultados.
Esta v1.0 exigiu muito trabalho, então estou fazendo uma pausa. Espero que aproveitem o modelo, e se mesclá-lo, por favor compartilhe gratuitamente no Civitai. Assim, todos podemos continuar melhorando.
A grade de especificações (479.4 MB): download
v0.4
Combinei 132 LoRAs.
Combinei 4 Checkpoints.
A grade de especificações: download
v0.3
Melhorado em todos os samplers.
Alcançou realismo vívido.
Estabilizado.
A grade de especificações: download
v0.2
Melhorias significativas em clareza e detalhes.
Melhoria na implementação de mãos e pés.
Grandes melhorias estéticas; composição, abstração, fluxo, luz e cor, etc.
v0.1
Após ajuste fino apropriado no modelo SDXL1.0
, combinei cuidadosamente e propositalmente mais de 40 modelos de alta qualidadepublicamente disponíveis no Civitai.
Os testes focaram principalmente em garantir qualidade máxima com o menor número de tokens no prompt, não tendo sido confirmado quanto a melhora na qualidade usando muitos tokens. (Por favor, realizem seus próprios testes e compartilhem os resultados)
Tipicamente, os resultados mais bonitos são obtidos no ponto intermediário entre realidade e animação.
No entanto, com prompt apropriado, geralmente não há nada que não possa expressar. (Afirmo que possui valor abundante como modelo base que supera outros em mesclagem. Porém, lembrem-se que atualmente esta é a v0.1)

Detalhes do Modelo
Tipo de modelo
Modelo base
Versão do modelo
Hash do modelo
Palavras treinadas
Criador
Discussão
Por favor, faça log in para deixar um comentário.
Coleção de Modelos - AlbedoBase XL





Imagens por AlbedoBase XL - v1.1
Imagens com 3d










Imagens com tudo em um



Imagens com anime










Imagens com modelo base

Imagens com fotorealista









