Anime Illust Diffusion XL - v0.5-alpha
Palavras-chave e Tags Relacionadas
Imagens em destaque





Prompts Recomendados
frieren from sousou no frieren,impasto style,beautiful color, detailed, aesthetic
best quality,masterpiece,vivid color,1girl,solo,bangs
Prompts Negativos Recomendados
worst quality:1.3,low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxl_neg
Parâmetros Recomendados
samplers
steps
cfg
resolution
vae
other models
Parâmetros Recomendados para Alta Resolução
denoising strength
Dicas
Reduza o peso nas palavras-chave de estilo artístico, por exemplo, (by xxx:0.6).
Ordene suas tags de prompt para melhores resultados.
Use o VAE do modelo ou sdxl-vae.
Destaques da Versão
Adicionados 143 novos gatilhos. Esta versão é beta do AIDXLv0.5, os novos estilos são instáveis. Para uma experiência melhor, recomendo o AIDXLv0.41.
Adicionado 143 novos gatilhos. Esta versão é uma versão beta do AIDXLv0.5. Os novos estilos não são estáveis. Eu recomendaria AIDXLv0.41 para uma melhor experiência.
Patrocinadores do Criador
Patrocínio de poder computacional: Agradecimentos à comunidade @NieTa (捏Ta (nieta.art)) pelo suporte computacional;
Suporte de dados: Agradecimentos a @KirinTea_Aki (Perfil do Criador KirinTea_Aki | Civitai) e @Chenkin (Civitai | Compartilhe seus modelos) pelo fornecimento de grande quantidade de dados;
Não haveria versão 0.7 sem eles.
Introdução ao Modelo (Parte em inglês)
I Conteúdos
Nesta introdução, você aprenderá sobre:
Informações do modelo (ver Seção II);
Instruções de uso (ver Seção III);
Parâmetros de treinamento (ver Seção IV);
Lista de Palavras-Chave (ver Apêndice Parte A)
II AIDXL
Anime Illustration Diffusion XL, ou AIDXL, é um modelo dedicado a gerar ilustrações de anime estilizadas. Possui mais de 800 estilos de ilustração embutidos (com atualizações frequentes), ativados por palavras-chave específicas (ver Apêndice A).
Vantagens:
Composição flexível em vez de poses tradicionais de IA.
Detalhes habilidosos em vez de caos desordenado.
Reconhece personagens de anime melhor.
III Guia do Usuário
1 Uso básico
1.1 Prompt
Palavras-chave: Adicione as palavras-chave fornecidas no Apêndice A para estilizar a imagem. Palavras-chave adequadas melhorarão muito a qualidade;
Recomenda-se reduzir o peso para palavras-chave de estilo artístico, por exemplo, (by xxx:0.6).
Ordenação semântica: Ordenar suas tags ou frases no prompt ajudará o modelo a entender seu significado.
Ordem recomendada das tags: Palavra-chave (by xxx) -> personagem (uma garota chamada frieren da série sousou no frieren) -> raça (elfo) -> composição (plano cowboy) -> estilo (impasto ) -> tema (tema fantasia) -> ambiente principal (na floresta, durante o dia) -> fundo (fundo degradê) -> ação (sentado no chão) -> expressão (sem expressão) -> características principais (cabelo branco) -> características do corpo (rabo de cavalo duplo, olhos verdes, lábios separados) -> vestuário (vestido branco) -> acessórios de vestuário (babados) -> outros itens (um gato) -> ambiente secundário (grama, luz do sol) -> estética (cor bonita, detalhado, estético) -> qualidade ((melhor qualidade:1.3))
Prompts negativos: (pior qualidade:1.3), baixa qualidade, baixa resolução, desordenado, abstrato, feio, desfigurado, má anatomia, rascunho, mãos deformadas, dedos fundidos, assinatura, texto, múltiplas vistas
1.2 Parâmetros de Geração
Resolução: Assegure o número total de pixels (=largura * altura) em torno de 1024*1024 com largura e altura divisíveis por 32 para melhores resultados no AIDXL. Por exemplo, 832x1216 (2:3), 1216x832 (3:2), e 1024x1024 (1:1), etc.
Sampler e passos: Use o sampler "Euler Ancester", chamado Euler A na webui. Amostragem em cerca de ~28 passos com escala CFG de 7 a 9.
'Refinar': A imagem gerada por text2image às vezes fica borrada, nesse caso é necessário 'refinar' usando image2image ou inpainting etc.
Para ampliação simples, pode-se consultar: Amplie para tamanhos enormes e adicione detalhes com SD Upscale, é fácil! : r/StableDiffusion (reddit.com)
Outros componentes: Não é necessário usar nenhum modelo refinador. Use o VAE do próprio modelo ou o
sdxl-vae.
P: Como reproduzir a capa do modelo? Por que não consigo reproduzir a mesma imagem da capa usando os mesmos parâmetros de geração?
R: Porque os parâmetros de geração mostrados na capa não são os parâmetros de text2image, mas sim os parâmetros de image2image (para ampliação). A imagem base é gerada majoritariamente pelo sampler Euler Ancester ao invés do sampler DPM.
2 Uso Especial
2.1 Estilos Generalizados
A partir da versão 0.7, o AIDXL resume vários estilos semelhantes e introduz palavras-chave de estilo generalizado. Essas palavras representam cada uma uma categoria comum de estilo de ilustração animada. Note que as palavras de estilo geral não necessariamente correspondem ao significado artístico original da palavra, mas são palavras-chave especiais que foram redefinidas.
2.2 Personagens
A partir da versão 0.7, o AIDXL aprimorou o treinamento para personagens. O efeito de algumas palavras-chave de personagem já pode alcançar o efeito de Lora e separar bem o conceito do personagem das suas roupas.
O método para acionar personagens é: {personagem} \({direitos autorais}\). Por exemplo, para acionar a heroína Lucy na animação "Cyberpunk: Edgerunners", use lucy \(cyberpunk\); para acionar o personagem Gan Yu no jogo "Genshin Impact", use ganyu \(genshin impact\). Aqui, "lucy" e "ganyu" são nomes de personagens, "\(cyberpunk\)" e "\(genshin impact\)" são as origens correspondentes, e os parênteses são escapados com barras "\" para evitar serem interpretados como tags ponderadas. Para alguns personagens, a parte de direitos autorais não é necessária.
A partir da versão v0.8, há um método de ativação mais fácil: uma {garota/garoto} chamada {personagem} da série {direitos autorais}.
Para a lista de palavras-chave de personagens, consulte: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 na branch main (huggingface.co). Além disso, algumas palavras-chave extras não mencionadas neste documento também podem estar incluídas.
Alguns personagens requerem um passo extra para ativação. Quando usado, se o personagem não puder ser completamente reproduzido com uma única palavra-chave, as principais características do personagem precisam ser adicionadas ao prompt.
O AIDXL suporta vestir personagens. Palavras-chave de personagem geralmente não trazem o conceito de características das roupas do personagem. Se desejar adicionar vestimentas, é necessário adicionar a tag da roupa no prompt. Por exemplo, vestido de noite prateado, decote profundo dá a roupa do personagem St. Louis (Luxurious Wheels) do jogo Azur Lane. Da mesma forma, você pode adicionar as tags de roupas de qualquer personagem a outros personagens.
2.3 Tags de Qualidade
Tags de qualidade e estética são formalmente treinadas. Inserí-las nos prompts afetará a qualidade da imagem gerada.
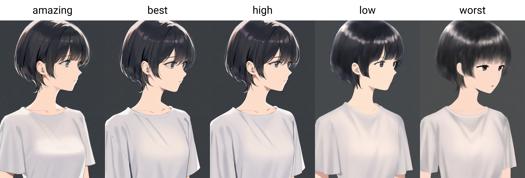
A partir da versão 0.7, o AIDXL treina e introduz tags de qualidade oficialmente. As qualidades são divididas em seis níveis, do melhor para o pior: qualidade incrível, melhor qualidade, alta qualidade, qualidade normal, baixa qualidade e pior qualidade.
Recomenda-se adicionar peso extra às tags de qualidade, por exemplo, (qualidade incrível:1.5).
2.4 Tags Estéticas
Desde a versão 0.7, foram introduzidas tags estéticas para descrever características estéticas especiais das imagens.
2.5 Fusão de Estilos
Você pode mesclar alguns estilos em seu estilo personalizado. 'Mesclar' significa na verdade usar múltiplas palavras-chave de estilo ao mesmo tempo. Por exemplo, chun-li, qualidade incrível, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Algumas dicas:
Controle o peso e a ordem dos estilos para ajustar o estilo.
Anexe ao prompt ao invés de preceder.
IV Estratégia de Treinamento e Parâmetros
AIDXLv0.1
Usando o SDXL1.0 como modelo base, treinando cerca de 22 mil imagens rotuladas por aproximadamente 100 épocas em um agendador cosseno com taxa de aprendizado de 5e-6 e número de ciclos = 1 para obter o modelo A. Depois, usando uma taxa de aprendizado de 2e-7 e os mesmos outros parâmetros para obter o modelo B. O modelo AIDXLv0.1 é obtido pela fusão dos modelos A e B.
AIDXLv0.51
Estratégia de Treinamento
Retoma o treinamento do AIDXLv0.5, com três etapas de treinamento em sequência:
Treinamento com legendas longas: Use todo o conjunto de dados, com algumas imagens legendadas manualmente. Inicie o treinamento tanto do U-Net quanto do codificador de texto com o otimizador AdamW8bit, alta taxa de aprendizado (em torno de 1.5e-6) com agendador cosseno. Pare o treinamento quando a taxa de aprendizado decair abaixo de um limite (cerca de 5e-7).
Treinamento com legendas curtas: Reinicie o treinamento a partir do output do passo 1 com os mesmos parâmetros e estratégia, mas com um conjunto de dados de legendas mais curtas.
Etapa de refinamento: Prepare um subconjunto do conjunto de dados do passo 1 contendo imagens selecionadas manualmente de alta qualidade. Reinicie o treinamento a partir do output do passo 2 com baixa taxa de aprendizado (cerca de 7.5e-7), com agendador cosseno com reinícios de 5 a 10 ciclos. Treine até o resultado ser esteticamente bom.
Parâmetros Fixos de Treinamento
Sem ruído extra como offset de ruído.
Min snr gamma = 5: acelera o treinamento.
Precisão completa bf16.
Otimizador AdamW8bit: equilíbrio entre eficiência e desempenho.
Conjunto de Dados
Resolução: resolução total de 1024x1024 (= altura vezes largura) com estratégia oficial modificada de bucketing do SDXL.
Legenda: legendas geradas pelo modelo WD14-Swinv2 com limiar de 0.35.
Recorte close-up: as imagens são recortadas em vários close-ups. Útil para imagens grandes ou raras.
Palavras-chave: mantenha a primeira tag das imagens como suas palavras-chave.
AIDXLv0.6
Estratégia de Treinamento
Retoma o treinamento do AIDXLv0.52 com uma estratégia adaptativa de repetições - para cada imagem legendada no conjunto de dados, aumenta o número de repetições no treinamento sujeito às seguintes regras:
Regra 1: Quanto maior a qualidade da imagem, maior seu número de repetições;
Regra 2: Se a imagem pertence a uma classe de estilo:
Se a classe ainda não está ajustada ou está subajustada, aumente manualmente o número de repetições da classe, ou automaticamente aumente as repetições para que o total das repetições dos dados na classe atinja um valor pré-definido, cerca de 100.
Se a classe já está ajustada ou superajustada, diminua manualmente o número de repetições da classe forçando-o a 1 e descarte se a qualidade for baixa.
Regra 3: O número de repetições limita seu número final para não exceder um certo limite, cerca de 10.
Essa estratégia possui as seguintes vantagens:
Protege as informações originais do modelo contra o novo treinamento, seguindo a mesma ideia da imagem regularizada;
Controla melhor o impacto dos dados de treinamento;
Equilibra o treinamento entre diferentes classes, motivando classes ainda não ajustadas e prevenindo superajuste nas já ajustadas;
Economiza significativamente recursos computacionais, facilitando a adição de novos estilos ao modelo.
Parâmetros Fixos de Treinamento
Iguais aos do AIDXLv0.51.
Conjunto de Dados
O conjunto de dados do AIDXLv0.6 é baseado no AIDXLv0.51. Além disso, as seguintes otimizações foram aplicadas:
Ordenação semântica das legendas: ordene as tags das legendas pela ordem semântica, por exemplo, "arma, 1 garoto, segurando, cabelo curto" -> "1 garoto, cabelo curto, segurando, arma".
Eliminação de duplicatas nas legendas: remova tags duplicadas, mantendo a que retém mais informação. Tags duplicadas significam tags com significados semelhantes como "cabelo longo" e "cabelo muito longo".
Tags extras: adicione manualmente tags adicionais a todas as imagens, por exemplo, "alta qualidade", "impasto" etc. Isso pode ser rapidamente feito com algumas ferramentas.
V Agradecimentos Especiais
Patrocínio de poder computacional: Agradecimentos à comunidade @NieTa (捏Ta (nieta.art)) pelo suporte de poder computacional;
Suporte de dados: Agradecimentos a @KirinTea_Aki (Perfil do Criador KirinTea_Aki | Civitai) e @Chenkin (Civitai | Compartilhe seus modelos) pelo fornecimento de grande quantidade de dados;
Não haveria versão 0.7 sem eles.
VI AIDXL vs AID
2023/08/08. O AIDXL foi treinado no mesmo conjunto de dados que o AIDv2.10, mas supera o AIDv2.10. O AIDXL é mais inteligente e pode fazer muitas coisas que modelos baseados em SD1.5 não conseguem. Também faz um ótimo trabalho distinguindo conceitos, aprendendo detalhes da imagem, lidando com composições difíceis ou até impossíveis para SD1.5 e AID. No geral, tem um potencial absoluto. Continuarei atualizando o AIDXL.
VII Patrocínio
Se você gosta do nosso trabalho, seja bem-vindo a nos patrocinar via Ko-fi(https://ko-fi.com/eugeai) para apoiar nossa pesquisa e desenvolvimento. Obrigado pelo seu suporte~
介绍 do Modelo (Parte em Chinês)
I Índice
Nesta introdução, você aprenderá:
Introdução do modelo (ver Seção II);
Guia de uso (ver Seção III);
Parâmetros de treinamento (ver Seção IV);
Lista de palavras-chave (ver Apêndice A)
II Introdução ao Modelo
Anime Illustration Diffusion XL, ou AIDXL, é um modelo dedicado à geração de ilustrações 2D. Ele possui mais de 800 estilos embutidos (aumentando com as atualizações) ativados por palavras-chave específicas (ver Apêndice A).
Vantagens: composições ousadas, sem sensação de pose forçada, foco no sujeito principal, sem muitos detalhes complexos, conhece muitos personagens de anime (ativados pelo nome em romaji, por exemplo, "ayanami rei" para "绫波丽", "kamado nezuko" para "祢豆子").
III Guia de Uso (em constante atualização)
1 Uso Básico
1.1 Como escrever prompts
Use palavras-chave: utilize as palavras-chave do Apêndice A para estilizar a imagem. Palavras apropriadas melhorarão muito a qualidade da geração;
Tags de prompt: use prompts tagueados para descrever o objeto a ser gerado;
Ordenação dos prompts: ordenar seus prompts ajudará o modelo a entender o significado. Ordem recomendada:
Palavra-chave (by xxx)->protagonista (1girl)->personagem (frieren)->raça (elf)->composição (cowboy shot)->estilo (impasto)->tema (fantasia)->ambiente principal (floresta, dia)->fundo (fundo degradê)->ação (sentada)->expressão (sem expressão)->características principais do personagem (cabelos brancos)->características do corpo (rabo de cavalo duplo, olhos verdes, lábios separados)->roupa (vestido branco)->acessórios da roupa (babados)->outros objetos (varinha mágica)->ambiente secundário (grama, luz do sol)->estética (cor bonita, detalhado, estético)->qualidade (melhor qualidade)
Prompts negativos: pior qualidade, baixa qualidade, baixa resolução, desordenado, abstrato, feio, desfigurado, má anatomia, mãos deformadas, dedos fundidos, assinatura, texto, múltiplas vistas
1.2 Parâmetros de Geração
Resolução: garanta a resolução total (altura x largura) perto de 1024*1024 e largura e altura múltiplas de 32. Exemplo 832x1216 (3:2), 1216x832 (3:2), 1024x1024 (1:1).
Não use "Clip Skip", ou seja, Clip Skip = 1.
Sampler e passos: use o sampler "euler_ancester" (Euler A na webui). Use 28 passos com CFG Scale 7.
Não precisa usar refinador (Refiner).
Use o VAE base ou sdxl-vae.
2 Uso Especial
2.1 Estilização Geral
A versão 0.7 consolidou vários estilos parecidos e introduziu palavras-chave de estilo geral, cada uma representando uma categoria comum de ilustração animada.
Atenção que essas palavras-chave podem ter significado artístico diferenciado do original, pois foram redefinidas.
2.2 Personagens
A versão 0.7 aprimorou o treinamento de personagens. Algumas palavras-chave de personagem já oferecem efeito similar a Lora, separando bem conceito e roupa.
Método: nome do personagem \(obra\). Exemplo: protagonista Lucy em "Cyberpunk: Edgerunners" usa lucy \(cyberpunk\); personagem Gan Yu em "Genshin Impact" usa ganyu \(genshin impact\). Parênteses escapados com barras para evitar interpretação errada. Para alguns personagens, obra pode ser omitida.
Consulte selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 para lista de palavras-chave. Palavras extras também podem ser incluídas.
Se um único termo não reproduz o personagem integralmente, adicione características principais no prompt.
Suporta roupas nos personagens; a palavra-chave do personagem normalmente não inclui isso. Para adicionar roupa, inclua tags de roupa no prompt, exemplo vestido de noite prateado, decote profundo para personagem St. Louis (Luxurious Wheels) do jogo Azur Lane. Também pode adicionar roupas de um personagem a outro.
2.3 Tags de Qualidade
Tags de qualidade e estética são formalmente treinadas. Usá-las nos prompts influencia a qualidade da imagem.
Os níveis de qualidade são: qualidade incrível, melhor qualidade, alta qualidade, qualidade normal, baixa qualidade e pior qualidade.
2.4 Tags Estéticas
Desde a versão 0.7, tags estéticas são usadas para descrever características especiais das imagens.
2.5 Combinação de Estilos
Você pode combinar diversos estilos em seu estilo customizado. "Combinar" significa usar múltiplas palavras de estilo ao mesmo tempo. Exemplo: chun-li, qualidade incrível, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Dicas:
Controle os pesos e a ordem para ajustar estilo.
Anexe ao prompt em vez de preceder.
3 Avisos
Use modelos VAE, embeddings de texto e modelos Lora compatíveis com SDXL. Nota: sd-vae-ft-mse-original não é compatível com SDXL; EasyNegative, badhandv4 e outros embeddings negativos também não;
Versões 0.61 e inferiores: recomenda-se fortemente usar embeddings negativos específicos do modelo para a geração de imagens, pois são personalizados e tendem a ter efeito positivo para o modelo;
Novas palavras-chave adicionadas em cada versão podem ter efeitos fracos ou instáveis na versão atual.
IV Parâmetros de Treinamento
SDXL1.0 como base, uso de cerca de 20 mil imagens etiquetadas com taxa de aprendizado 5e-6 e um ciclo em agendador cosseno para cerca de 100 épocas resultando no Modelo A. Depois, taxa de aprendizado 2e-7 com outros parâmetros iguais para o Modelo B. Modelo AIDXLv0.1 deriva da fusão de A e B.
Outros parâmetros de treinamento veja na seção em inglês.
V Agradecimentos Especiais
Patrocínio de poder computacional: obrigado à comunidade @捏Ta (捏Ta (nieta.art)) pelo suporte computacional;
Suporte de dados: obrigado a @秋麒麟热茶 (Perfil KirinTea_Aki | Civitai) e @风吟 (Perfil Chenkin | Civitai) pelo suporte massivo de dados;
Sem eles não haveria versão 0.7.
VI Registro de Atualizações
2023/08/08: AIDXL foi treinado com o mesmo conjunto que AIDv2.10, mas com desempenho superior. É mais inteligente, realiza muitas tarefas que modelos baseados em SD1.5 não conseguem; distingue conceitos, aprende detalhes, lida com composições difíceis para SD1.5 e AID. Em resumo, tem muito potencial e continuará sendo atualizado.
2024/01/27: A versão 0.7 adicionou muito conteúdo, o tamanho do dataset dobrou em relação à versão anterior.
Para obter boas etiquetas, experimentou-se novos algoritmos como ordenação de tags, randomização hierárquica e separação de características de personagens. Projeto: Eugeoter/sd-dataset-manager (github.com);
Para controle reforçado, scripts especiais baseados em Kohya-ss foram feitos;
Para controlar a fusão de diferentes gerações de modelos, foram desenvolvidos algoritmos heurísticos; para alcançar estilização suficiente, evitou-se fusão dos codificadores de texto e camadas OUT do UNET para não prejudicar o estilo;
Para filtrar dados, foram treinados modelos de detecção de marcas d'água, classificação de imagens e avaliação estética.
VII Apoie-nos
Se gostar do nosso trabalho, por favor nos patrocine via Ko-fi(https://ko-fi.com/eugeai) para apoiar nossa pesquisa e desenvolvimento, obrigado pelo suporte!
Apêndice / 附录
A. Lista de Palavras-Chave Especiais / 特殊触发词列表
Palavras-chave de estilo artístico: Clique aqui
Palavras-chave de estilo de pintura: flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: Cores planas, usando linhas para descrever luz e sombra
平涂:Cores planas, usando linhas e manchas para descrever luz e sombra
clean color: Estilo entre flat color e flat-pasto. Coloração simples e limpa.
Cor limpa: Estilo intermediário entre flat color e flat-pasto
celluloid: Coloração de anime
Cor de celuloide: Coloração de anime
flat-pasto: Cor quase plana, usando gradiente para descrever luz e sombra
Cor quase plana, usando gradientes para luz e sombra
thin-pasto: Contorno fino, usando gradiente e espessura da tinta para descrever luz, sombra e camadas
Contorno fino com gradiente e espessura da tinta para luz, sombra e camadas
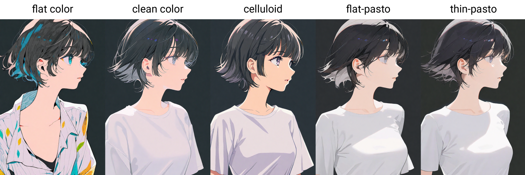
pseudo-impasto: Uso de gradientes e espessura da tinta para descrever luz, sombra e camadas
Pseudo-impasto / semi-impasto: Gradientes e espessura da tinta para luz, sombra e camadas
impasto: Uso da espessura da tinta para descrever luz, sombra e gradação
Impasto: Espessura da tinta para luz, sombra e gradação
realistic
Realista
photorealistic: Redefinido para estilo mais próximo do real
Fotorealista: Estilo redefinido para ser mais próximo do mundo real
cel shading: Estilo de modelagem 3D de anime
Sombreamento cel: Estilo 3D de anime
3d

Palavras-chave estéticas:
beautiful
Bonito
aesthetic: senso artístico ligeiramente abstrato
Estético: sensação artística levemente abstrata
detailed
Detalhado
beautiful color: uso sutil de cor
Cor bonita: uso sutil de cor
lowres
messy: composição ou detalhes bagunçados
Bagunçado: composição ou detalhes desordenados
Palavras-chave de qualidade: qualidade incrível, melhor qualidade, alta qualidade, baixa qualidade, pior qualidade




Detalhes do Modelo
Tipo de modelo
Modelo base
Versão do modelo
Hash do modelo
Palavras treinadas
Criador
Discussão
Por favor, faça log in para deixar um comentário.
Coleção de Modelos - Anime Illust Diffusion XL


Imagens por Anime Illust Diffusion XL - v0.5-alpha
Imagens com anime










Imagens com modelo base

Imagens com ilustração









