Old Consistency V32 Lora [FLUX1.D/PDXL] - Feminine v1.1 - e500 PDXL
Imagens em destaque


Prompts Recomendados
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes
a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
a woman eating at a restaurant, from above, from behind, all fours, ass, thong
score_9, score_8_up, score_7_up, score_6_up, BREAK 1girl, solo, mature female, yellow eyes, red hair
Prompts Negativos Recomendados
greyscale, monochrome, multiple views
Parâmetros Recomendados
samplers
steps
cfg
clip skip
resolution
vae
other models
Parâmetros Recomendados para Alta Resolução
upscaler
upscale
denoising strength
Dicas
Use múltiplos loopbacks para melhorar a fidelidade e consistência da imagem.
Mantenha prompts padrão e ordem lógica para evitar aberrações.
Use tags principais de pose e ângulo de visão como 'from front', 'from side', 'from above' para melhorar a precisão da pose.
Evite usar poses sexuais até que estejam devidamente refinadas.
Experimente várias tags de traços para cabelo, olhos, cores de roupas e materiais.
A ordem de carregamento afeta os resultados ao mesclar com outros modelos e LoRAs.
Modo seguro é ativado por padrão com opções para desbloquear conteúdos questionáveis e explícitos.
Use o sistema de tags de pose e diretiva para obter melhor controle sobre posicionamento de personagens e ângulos de câmera.
Destaques da Versão
Checagens de estabilidade;
conceito - imagens/testadas
corpo inteiro - 48/48
cowboy shot - 48/48
retrato - 48/48
close-up - 48/48
**************************************
Próxima iteração terá uma camada singular induzindo subgrupo de pose para olhos, marcada com ângulos de pose e incluindo mais imagens de olhos para variações de ângulo para solidificar o efeito. A cor direta dos olhos provavelmente não é necessária, a forma parece ser crucial conforme pesquisas.
olhos vermelhos - 39/48
corpo inteiro - 6/12
cowboy shot - 9/12
retrato - 12/12
close-up - 12/12
olhos azuis - 48/48
todas poses - 12/12
olhos verdes - 48/48
todas poses -12/12
olhos amarelos - 42/48
corpo inteiro - 6/12 - incerto por que é instável.
olhos aqua - 48/48
todas poses
olhos roxos - 48/48
todas poses
látex - 36/48
close-up - 5/12
retrato - 7/12 - requer imagens de retrato e close-up
cowboy shot - 12/12
corpo inteiro - 12/12
lingerie - 36/48
close-up - 7/12
retrato - 4/12 ? por quê? - requer imagens diretas de retrato e close-up de rosto
cowboy shot - 11/12
corpo inteiro - 12/12
casual - 48/48
todas poses - 12/12
biquíni - 48/48
todas poses - 12/12
vestido - 16/48
nenhuma pose bateu com o vestido correto, a menos que indicado com tags adicionais -> necessidade de marcar vestidos mais especificamente
A estabilidade da saída foi consideravelmente maior do que o esperado com uma série de tags úteis já embutidas no pony, incluindo;
<color> cabelo
<color> roupas
tamanho dos seios <size>
mulher <mature>
<color> brincos
<color> olhos
objeto <blurry>
área <background>
Há muitos potenciais de tags úteis aqui, então devem ser explorados como fiz.
Sucessos na sobreposição;
olhos vermelhos -> olhos azuis;
[olhos vermelhos:0.5], [olhos azuis:0.5] -> sobreposição ocasional, instável.
olhos vermelhos, olhos azuis -> sobreposição menos consistente
olhos vermelhos E olhos azuis -> sobreposição mais consistente, mais pesquisas necessárias
a maioria dos olhos enfrenta na verdade o mesmo problema, onde o modelo impõe muita cor dos olhos sobre a forma deles, então o experimento de camada dos olhos será interrompido e implementado baseado no experimento de manchas antes.
vestido -> látex
vestido, fenda lateral, vestido cocktail, látex, roupa de látex -> forma um traje baseado em múltiplas partes das camadas. A consistência é instável, mas o resultado é promissor.
látex -> vestido
látex, roupa de látex, vestido, fenda lateral -> forma um objeto mais vestido, que parece estar sobrepondo lacunas do vestido mais do que se usar o vestido primeiro. Isso indica que o treino do vestido está sobreajustado para a tarefa e precisa de reavaliação.
látex -> biquíni
látex, roupa de látex, biquíni -> forma leggings de látex misturadas com biquíni, o que sugere sobreajuste.
Acredito ter uma solução para o sobreposição de roupas, e junto com ela, soluções para olhos, cor de pele e mais. A maior parte da consistência deve vir da técnica de manchas.
Patrocinadores do Criador
Confira o Modelo Illustrious para capacidades complementares.
Use o fluxo ComfyUI para geração de imagens aprimorada e experimente loopings.
Explore o poderoso Modelo Flux como a base da IA.
Apoie NovelAI para sinergia superior na geração de histórias e imagens.
Créditos a Black Forest Labs pela criação do modelo Flux.
Melhore o fluxo de trabalho de marcação com TagGUI.
Configuração de treinamento feita com AIToolkit.
Inspirado e rival do PonyDiffusion.

PDXL + ILLUSTRIOUS TRAIN V3.34:
Illustrious não é um desdobramento do PDXL, é diferente e muito bom. Experimente se tiver a chance.
Treinei uma versão do Simulacrum especificamente para ele.
V3-2 Em vez de V3.22:
O objetivo da v3.22 acabou mudando e me perdi no labirinto dos testes flux e descobrindo novos mecanismos. Depois que aprendi e determinei que sei o suficiente sobre como fixar sujeitos, como marcar e como o próprio flux entende a marcação; posso realmente construir uma versão 3 adequada.
Obrigado a todos que suportaram meu ciclo de aprendizado e experimentação. Foi uma montanha-russa legítima de testes, falhas e alguns verdadeiros sucessos. Sei o que pode ser feito, como fazer, e tenho uma metodologia para abordar e iterar sobre o que aprendi para criar o que quero criar. O processo não é perfeito e será refinado conforme avanço, então será uma questão de entendimento e desenvolvimento iterativo, não importa o que eu construa. Estou confiante o suficiente para dizer que encontrei e atravessei o primeiro grande declive do efeito Dunning-Kruger e que posso começar a aprender e ensinar informações úteis após os experimentos, enquanto tento o melhor para processar e entender as informações de forma útil para usuários básicos e avançados.
Determinei que minha abordagem original para a V4 é viável, mas o processo que eu usava não é válido como pensei originalmente enquanto aprendia iterativamente os sistemas. Mais aspectos aprendidos e mais falhas para aprender, para desenvolver o terreno preparado para os sucessos que virão.
Versionamento baseado em diretivas.
Planejo introduzir TRÊS treinamentos principais por versão e uma versão "vanilla" nd singular.
Usarei treinamentos baseados em diretivas gerais não só para o sistema principal, mas também para imagens temáticas principais específicas para disseminar todos os aspectos temáticos pretendidos no sistema.
A parte técnica do processo de marcação será única e difícil de entender para quem não está familiarizado com a razão por trás do que estou fazendo no sistema, então as imagens e marcações provavelmente serão altamente confusas se quiser detalhes específicos.
O sistema de marcação simplista permanecerá por si só e continuará plenamente capaz de produzir os resultados necessários quando necessário.
A versão "nd" ou "no directive" para cada lançamento garantirá que as diferenças de teste e resultados sejam similares, como o pássaro na mina; é hora de ir quando o pássaro para de cantar. Provavelmente esses modelos irmãos poderão ser mesclados e normalizados para reutilização e mistura de conceitos que podem ou não ter funcionado devido à diretiva usada.
A fixação em personagens INDIVIDUAIS é agora o objetivo mais importante para este modelo. Haverá apenas um personagem fixado e a resolução para esse personagem será escalada para uma proporção descendente e ascendente correspondente aos parâmetros corretos de formatação do treinamento FLUX.
Os problemas da V3.2 foram menos pronunciados do que eu pensei:
A maior parte da preocupação com o resultado baseava-se em informações ausentes que planejo corrigir ao longo do tempo. É apenas uma questão de desenvolvimento iterativo.
Dito isso, a versão treinada da 3.21 está atualmente em testes e será lançada em breve. Ela tem capacidade aprimorada de controle de pose e um foco alterado usando uma diretiva de câmera relativamente longa.
O resultado mostrou boa compatibilidade com a maioria das loras que testei e até funciona com algumas loras muito rígidas que não parecem ser manobradas ou rotacionadas com a v32 atual.
Tem boa compatibilidade com Flux Unchained, múltiplos modelos de personagem, modelos de rosto, modelos humanos, etc. A maioria do sistema não sobrepõe ou quebra outros sistemas até agora, o que é bom.
Problemas da V3.2 para resolver:
Há algumas questões de consistência com algumas poses e ângulos. Também há alguma contaminação cruzada com várias outras loras quando usam as tags "from side", "from behind", "from above" e "from below". Vou usar novas tags como uma espécie de unidade de verificação e treinar uma LORA totalmente separada para garantir fidelidade no controle de câmera no futuro.
Parece funcionar bem principalmente para anime, mas quando loras entram em jogo, há problemas.
Tags de combinação para a versão 3.21;
Há alguns testes base que preciso executar para garantir que a câmera funcione corretamente baseado no posicionamento, então vou testar tags como:
um sujeito visto de frente por cima
um sujeito visto de lado pela frente enquanto por cima
um sujeito visto de trás por cima enquanto na frente
um sujeito visto de lado por cima enquanto atrás
e outras tags similares no base flux_dev, para garantir que o que construí posicionará corretamente a câmera e a fidelidade da imagem não será perdida no processo.
Pelo que entendi, o sistema treina profundidades enormes se usar opções genéricas como essas. Mais testes são necessários para ter certeza.
Tags como "grabbing from behind", "sex from behind" provavelmente não cooperarão com tags "behind", então usarei as tags "rear".
"from side", "from behind", "straight-on", "facing the viewer" e tudo diretamente ligado a algum safebooru, danbooru, gelbooru específico de personagem, rotações de posicionamento não serão treinados. Será totalmente baseado em VISUALIZAR um personagem, ao invés de INTERAGIR com ele.
Também não queremos braços em POV na maioria das vezes, então será necessário muito teste para garantir que a marcação não gere braços, pernas, troncos acidentalmente e fique fixada no sujeito individual em questão.
Algumas das poses, francamente, não funcionaram:
Há um sistema de combinação de tags em jogo aqui que simplesmente não fez seu trabalho, então será necessário um novo conjunto de combinações para controlar o personagem corretamente.
As pernas estão deformadas ou não existem.
Os braços podem estar deformados ou mal posicionados.
Os pés estão faltando.
O tronco superior aparece demais com muita frequência. <<< overfitted
O tronco inferior não mostra roupas corretamente.
O pescoço não exibe adereços corretos como cachecóis, toalhas, gargantilhas, colares, etc.
Os mamilos e genitais estão um caos absoluto. Precisa haver uma pasta adequada com suas variações para um controlador NSFW apropriado neste caso.
NAI deve ser especificamente ajustado por estilo e refinado como estilo.
Opções de roupas geram tipos de corpo com mais frequência do que deveriam.
A classificação explícita é quase impossível de acessar às vezes, outras vezes explode como um trem de carga.
Não há imagens com questão suficiente para ponderar, e o sistema de marcação explícita também deveria ser marcado com questionável para garantir que a informação questionável seja acessada.
Alguns personagens de anime aparecem com perspectiva ruim, o que é ruim considerando que o objetivo é ter perspectiva associativa correta.
Posição de quatro apoios é bastante sólida, mas definitivamente tem problemas de perspectiva. Não parece tratar personagens de anime como 3d com frequência suficiente, então os ambientes ao redor das imagens precisam de mais fidelidade.
Posição de quatro apoios não funciona em uma formação sem muitos ajustes.
Ajoelhado não funciona em uma formação sem muitos ajustes.
Formações e grupos parecem ter uma formatação única para flux e isso merece investigação adicional. Quase como habilitar um loop interno para cada uma das iterações.
Houve alguns sucessos:
A fidelidade base não sofreu para a maioria das imagens.
Muitas novas poses FUNCIONAM, mesmo que às vezes sejam estranhas.
O estilo anime foi alterado de uma forma única NAI com um toque de realismo.
Múltiplos personagens podem ser posicionados, embora de forma estranha às vezes.
Ficar em qualquer ângulo tem fidelidade e qualidade de imagem absolutamente fantásticas com o estilo NAI.
V3.3 terá que esperar.
Roteiro V3.3:
Atualizei os recursos no final deste documento e separei a documentação antiga em um artigo próprio para arquivamento.
Com o resultado agora refletindo melhor minha visão, posso mudar o foco para o próximo passo da lista; Sobreposições.
V3.3 vai introduzir o que chamo de etiquetas offset queimadas de alta alfa, que vão facilitar coisas como fazer quadrinhos, interfaces de jogos, sobreposições, barras de saúde, displays, etc.
Teoricamente, você pode criar seus próprios jogos falsos em consistency se eu fizer uma sobreposição correta com as queimaduras certas.
Isso vai estabelecer a base para impor personagens em qualquer posição a partir de qualquer profundidade da cena, mas isso vem depois.
Já é possível criar spritesheets de forma justa, então vou explorar o sistema de tags embutido nos próximos dias para testar todos esses subsistemas usando um pouco de esforço no prompting e poder computacional. Há alta probabilidade de já existir algo assim e só precisar ser descoberto.
Objetivos V4:
Se tudo correr bem, o sistema inteiro deve estar pronto para capacidade total de produção incluindo modificação de imagem, edição de vídeo, edição 3d, e muito mais que simplesmente não consigo compreender ainda.
v33 sobreposições
Isso é um pouco equivocado, pois é mais uma estrutura de definição de cena para a próxima estrutura
Este será o que tomará menos e mais tempo ao mesmo tempo e tenho alguns experimentos com alfa para fazer funcionar, mas tenho certeza que sobreposição será uma opção não só para exibir mensagens, mas também para controle de cena devido a maneira como a profundidade funciona.
v34 imposição de personagens, planejamento de valor de rotação e ajustes cuidadosos de pontos de vista:
Garantir que certos personagens existam e sigam diretivas é um objetivo primário, pois às vezes simplesmente não seguem.
Será implementada uma valoração completa baseada em números para rotação usando pitch/yaw/roll em graus. Não será perfeito pois não tenho as habilidades matemáticas, nem os conjuntos de imagens nem as habilidades em software 3d para fazer isso, mas será um bom começo e espero que se conecte ao que o FLUX já possui.
v35 controladores de cena
Pontos de interação complexos em cenas, controle de câmera, foco, profundidade e mais que permitem construção completa de cena junto com os personagens posicionados nelas.
Pense nisso como uma versão 3d do controlador de sobreposição, mas em esteróides se quiser.
v36 controladores de iluminação
Mudanças de iluminação segmentadas e controladas por cena que afetam todos os personagens, objetos e criações contidos.
Cada luz será posicionada e gerada com base em regras específicas definidas no unreal usando múltiplos tipos de iluminação, fontes, cores, etc.
Teoricamente o FLUX deve preencher as lacunas.
v37 tipos de corpo e personalização corporal
Com a introdução dos tipos básicos de corpo, quero introduzir uma criação de tipo corporal mais complexa que inclui, mas não se limita a coisas como:
corrigir poses que não funcionam corretamente
adicionar uma série de poses adicionais
cabelo mais complexo:
interação do cabelo com objetos, cabelo cortado, cabelo danificado, cabelo descolorido, cabelo multicolorido, cabelo preso, perucas, etc
olhos mais complexos:
olhos de vários tipos, abertos, fechados, semicerrados, etc
expressões faciais de vários tipos:
feliz, triste, :o, sem olhos, rosto simples, sem rosto, etc
tipos de orelhas:
pontudas, arredondadas, sem orelhas, etc
cores de pele de vários tipos:
clara, vermelha, azul, verde, branca, cinza, prata, preta, preta intensa, marrom claro, marrom, marrom escuro e mais.
Vou tentar evitar temas sensíveis aqui pois as pessoas realmente se importam bastante com cor de pele, mas quero apenas uma variedade de cores como as roupas.
controladores de tamanho para braço, perna, tronco superior, cintura, quadris, pescoço e cabeça:
bíceps, ombro, cotovelo, punho, mãos, dedos, etc com ajustes para comprimento, largura e circunferência.
clavícula e quaisquer tags do tronco que existam
cintura e quaisquer tags da cintura que existam
generalizações e especificidades de tamanho corporal baseadas em um gradiente de 1 a 10, em vez de algum sistema pré-definido usado em qualquer booru
v38 roupas e personalização de roupas
Quase 200 roupas, cada uma com seus próprios parâmetros personalizados.
v39 500 personagens de videogames, anime e mangá amostrados a partir de dados de alta fidelidade
quinhentos cigaret- err... Quer dizer... Muitos personagens. Sim. Definitivamente não uma quantidade absurdamente grande de personagens baseados em memes sem ligação racional a design ou arquétipo de personagem.
Depois disso você pode construir qualquer coisa ou treinar qualquer personagem.
Aumento maciço de fidelidade e qualidade:
incluindo dezenas de milhares de imagens de várias fontes de anime de alta qualidade, modelos 3d e semi-realismo fotográfico para sobrepor e treinar esta versão particularmente refinada do flux em uma submissão estilística que se encaixe dentro dos parâmetros.
cada imagem será avaliada em fidelidade e marcada dentro de uma proporção de score_1 a score_10 de maneira similar ao pony, mas terei minha própria abordagem única dependendo de quão bem ou mal funcionar.
Lançamento V3.2 - 4k passos:
Este não é para crianças, com certeza. Este é um modelo base SFW/QUESTIONÁVEL/NSFW que pode ser treinado para qualquer coisa.
Também NÃO foi construído para ser um criador de conteúdo adulto, mas pode ser com o prompt certo. Faz parte do pacote quando você habilita comportamentos por ensinar certas coisas à IA, você ganha bagagens. As imagens são aproximadamente 33% cada atualmente, mais ou menos. É ponderado PARA conteúdo seguro, similar ao funcionamento do NAI.
Tenho uma postura firme de habilitar e ensinar informações para que o indivíduo decida o que fazer com elas. Ensinar uma IA sem censura a várias coisas usando um grau controlado e cuidadoso acredito ser saudável para a progressão e crescimento da IA para um entendimento de alta fidelidade, assim como saudável para quem gera imagens DA IA não precisar ver pesadelos 24/7.
Esta coisa mostra uma promessa além de tudo que já vi por uma larga margem.
Use minha carga de trabalho ComfyUI. Está anexada a todas as imagens abaixo.
Modo seguro ativado por padrão:
questionável < desbloqueia mais traços aleatórios questionáveis
explícito < desbloqueia coisas divertidas para aparecer aleatoriamente
Tags de ativação de perspectiva: tente misturar; from front, side view, etc
from front, front view,
from side, side view,
from behind, rear view,
from above, above view,
from below, below view,
Poses principais adicionadas e aprimoradas:
all fours
kneeling
squatting
standing
bent over
leaning
lying
upside-down
on stomach
on back
arm placements
leg placements
head tilts
head directions
eye directions
eye placement
eye color solidity
hair color solidity
breast size
ass size
waist size
uma grande variedade de opções de roupas
uma grande variedade de opções de personagens
uma grande variedade de expressões faciais
posições sexuais ainda em grande desenvolvimento e eu realmente recomendo evitar usá-las até que sejam devidamente refinadas. Elas estão MUITO além da minha capacidade no momento e não tenho energia para determinar a rota a seguir.
O criador de poses, criador de ângulos, configuração de situação, imponedor de conceito e estrutura de interpolação já estão prontos e treinarei mais versões.
Aproveite.
Roteiro V3.2:
25/08/2024 5:16 - Identifiquei que o processo funcionou e o sistema é funcional além das expectativas. A IA desenvolveu comportamentos emergentes que posicionam personagens de forma exponencialmente mais poderosa do que o previsto. Os testes começaram e o resultado parece fantástico.
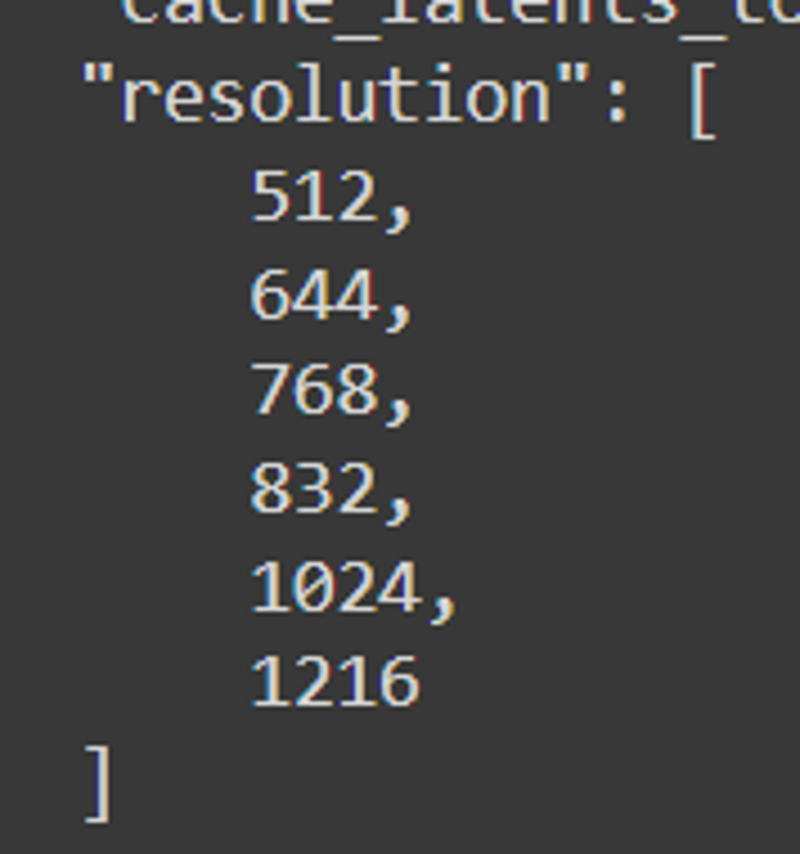
Resoluções finais: 512, 640, 768, 832, 1024, 1216
25/08/2024 15h - Tudo está devidamente marcado e as poses preparadas. O verdadeiro treinamento começa agora e o processo envolverá múltiplos testes multidimensionais, testes de contagem lr, checagem de passos e muito mais para avaliar o candidato correto para o lançamento v32.
25/08/2024 4h - A primeira versão da v32 mostrou deformidade mínima por volta do passo 1400 e então deformidade grave perto do passo 2200, o que indica que a marcação preguiçosa WD14 falhou. Marcações manuais virão. Vai ser uma manhã interessante.
24/08/2024 noite - Está em modo de cozimento agora.
 Suspeito que este não funcione. Auto-marquei tudo e excluí os ângulos de pose por enquanto. Vou ver o que o wd14 pode fazer sozinho. Depois do treinamento, seja ele bem-sucedido ou não, vou restaurar os ângulos de pose originais e a ordem de marcação estabelecida. Vamos ver como funciona agora com todos os dados intencionais agrupados e os casos de uso densos.
Suspeito que este não funcione. Auto-marquei tudo e excluí os ângulos de pose por enquanto. Vou ver o que o wd14 pode fazer sozinho. Depois do treinamento, seja ele bem-sucedido ou não, vou restaurar os ângulos de pose originais e a ordem de marcação estabelecida. Vamos ver como funciona agora com todos os dados intencionais agrupados e os casos de uso densos.Com 4000 imagens suspeito que vai levar um tempo para cachear os latentes, mas com a atenção dedicada às bonecas e corpos do "caso de uso", deve acabar ficando bom pelo menos.
24/08/2024 meio-dia -
 Estamos afiados.
Estamos afiados. Tudo está formatado para ter implicações de sombras no fundo, o que ajuda o flux a gerar imagens baseadas em superfícies e locais. Tudo é construído para poses faltantes que o flux não consegue manejar. Tudo é construído para focar nos sujeitos que podem ser multiplicativamente sobrepostos em múltiplos locais.
Tudo está formatado para ter implicações de sombras no fundo, o que ajuda o flux a gerar imagens baseadas em superfícies e locais. Tudo é construído para poses faltantes que o flux não consegue manejar. Tudo é construído para focar nos sujeitos que podem ser multiplicativamente sobrepostos em múltiplos locais.Tenho focado no posicionamento correto dos braços e garantindo que braços marcados que se sobrepõem construam braços do ponto A ao B.
24/08/2024 manhã - Aparentemente há alguns problemas com braços também, mas está tudo bem, vou colocar isso na lista. Obrigado por apontar, certamente há alguma contaminação cruzada que precisa ser resolvida. Uso um sistema específico de loopback no comfyui que não está presente no sistema do site, então talvez eu precise desabilitar a geração no local para esta versão.
 23/08/2024 - Estou com cerca de 340 novas imagens anime detalhadas com poses quase uniformes, identificadores pitch/yaw/roll para garantir solidez, mudanças de coloração, diferenciação de tamanho com seios, cabelo e bumbum. Faltam 554 imagens. A V3.2 será fortemente dedicada a anime, depois planejo usar imagens de pony para produzir realismo sintético suficiente para criar elementos necessários de realismo também. A menos que o flux permita isso após o treinamento, caso em que usarei o flux.
23/08/2024 - Estou com cerca de 340 novas imagens anime detalhadas com poses quase uniformes, identificadores pitch/yaw/roll para garantir solidez, mudanças de coloração, diferenciação de tamanho com seios, cabelo e bumbum. Faltam 554 imagens. A V3.2 será fortemente dedicada a anime, depois planejo usar imagens de pony para produzir realismo sintético suficiente para criar elementos necessários de realismo também. A menos que o flux permita isso após o treinamento, caso em que usarei o flux. Isso DEVE garantir fidelidade e separação de classificação pose a pose, especialmente porque tenho uma nova metodologia de usar as palavras-chave "from" e "view". Teoricamente deve funcionar quase idêntico ao controle de pose do NovelAI quando estiver pronto, que é basicamente meu objetivo. Os personagens e a diferenciação entre eles é uma história totalmente diferente, claro.
Isso DEVE garantir fidelidade e separação de classificação pose a pose, especialmente porque tenho uma nova metodologia de usar as palavras-chave "from" e "view". Teoricamente deve funcionar quase idêntico ao controle de pose do NovelAI quando estiver pronto, que é basicamente meu objetivo. Os personagens e a diferenciação entre eles é uma história totalmente diferente, claro.Tudo deve estar perfeitamente ordenado e alinhado, senão simplesmente não adicionará o contexto necessário na taxa necessária para afetar o modelo base o bastante para ser útil.
Por design, o SEGURO será o padrão, então o sistema inteiro será construído ponderado para seguro, com a habilidade de ativar NSFW.
Treinarei múltiplas iterações desta LORA específica para garantir que a diferenciação entre os dois possa permanecer rigorosa, permitindo que o público NSFW também seja atendido com a versão mais NSFW.
Minha esperança é que, quando treinado; eu possa despejar um conjunto de dados escolhido de 50.000 imagens no sistema e ele criará algo mágico. Algo potencialmente no mesmo nível de poder do pony para qualquer coisa que o coração desejar. Então posso descansar sabendo que o universo está grato. Depois disso vocês provavelmente podem despejar qualquer coisa nele e ele vai criar o que quiserem devido ao poder inato do flux com a espinha da consistência.
Planejo liberar os dados de treinamento para o conjunto inicial completo de imagens da consistência v3.2 quando estiver organizado, treinado, testado e pronto. Vou liberar os dados v3 neste final de semana quando tiver tempo.
Identifiquei uma série de inconsistências de pose, principalmente com a palavra-chave "lying" acoplada às palavras-chave de ângulo. Vou testar cada combinação e reforçar a consistência final antes de avançar para a próxima fase; as escolhas básicas de roupa, mudanças de roupas e derivativos baseados nas poses que funcionam e que não funcionam. Sem mencionar que preciso incluir informações mais detalhadas para os elementos questionáveis e NSFW depois também. Vocês podem imaginar o que são esses após a próxima versão.
Até lá, preciso garantir que as poses realmente funcionem conforme as diretivas, então criarei novas palavras-chave de combinação intencionais, reforçando a contagem total de poses para mais imagens por pose, mais imagens por ângulo, e mais ângulos por situação. Também criarei uma série de dados que funcionam como espaços reservados para criar situações e imagens mais complexas, mas o flux realmente não precisa de muitas, então farei isso conforme avanço. Também incluirei uma série de tags "base" que definirão padrões para certas coisas ao atingirem pontos de falha para outras coisas. Isso deve ajudar um pouco com a consistência.
Documentação V3:
Testado principalmente no FLUX.1 Dev e4m3fn em fp8, então o checkpoint preparado para merge refletirá esse valor quando o upload for concluído. https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
Roda no modelo base FLUX.1 Dev, mas funcionará em outros modelos, merges e com outras loras. Os resultados serão mistos. Experimente a ordem de carregamento, pois os valores do modelo mudam em sequência em graus variados.
Isso é nada menos que uma espinha para o FLUX. Ele fortalece tags úteis muito semelhantes ao danbooru, para estabelecer controle e assistência de câmera que facilita muito criar personagens personalizáveis em situações que o FLUX provavelmente PODE FAZER, mas que exigem muito mais esforço para fazer por padrão.
Recomendo MUITO rodar múltiplos loopbacks para garantir fidelidade da imagem. Consistência melhora qualidade e fidelidade ao longo de múltiplas iterações.
Forte foco no indivíduo. No entanto, devido à forma como estruturei as resoluções, pode lidar com MUITAS pessoas em situações similares. As loras que causam mudanças imediatas na tela sem contexto geralmente são totalmente inúteis, pois geralmente não contribuem para o contexto. Loras mais específicas para adicionar TRAÇOS a pessoas ou criar interações contextuais entre pessoas parecem funcionar bem. Roupas funcionam, tipos de cabelo funcionam, controle de gênero funciona. A maioria das loras que testei funcionam, mas existem algumas que não fazem nada.
Não é um merge. Não é combinação de loras. Esta lora foi criada usando dados sintéticos gerados por NAI e AutismPDXL ao longo de um ano. O conjunto de imagens é bastante complexo e as imagens escolhidas para criar essa não foram fáceis de selecionar. Exigiu muito tentativa e erro. Muito mesmo.
Há uma SÉRIE de tags principais introduzidas com esta lora. Ela adiciona toda uma espinha ao FLUX que ele simplesmente não tem por padrão. O padrão de ativação é complexo, mas se você construir seu personagem parecido com o NAI, vai parecer similar a como o NAI cria personagens.
O potencial e poder deste modelo não devem ser subestimados. É uma lora absolutamente poderosa e seu potencial está além do meu alcance.
Ainda pode produzir aberrações se não for tratado com cuidado. Se usar prompts padrão e uma ordem lógica, deve construir arte bonita em pouco tempo.
Resoluções: 512, 768, 816, 1024, 1216
Passos sugeridos: 16
Guia FLUX: 4 ou 3-5 se for teimoso, 15+ se for muito teimoso
CFG: 1
Executei 2 loopbacks. O primeiro foi upscale 1.05x e denoise entre 0.72-0.88, e o segundo foi denoise 0.8 quase nunca alterado, dependendo de quantos traços quero introduzir ou remover.
BANCO DE TAGS PRINCIPAIS:
anime - converte o estilo de poses, personagens, roupas, rostos, etc em anime
realistic - converte o estilo para realista
from front - vista frontal de uma pessoa, situação com ombros alinhados, voltados para o espectador, com o centro de massa do tronco voltado para o espectador.
from side - vista lateral de uma pessoa, ombro vertical voltado para o espectador, ou seja, os ombros são verticais e o personagem está de lado
from behind - vista diretamente de trás da pessoa
straight-on - vista com ângulo vertical direto, para ângulo plano horizontal
from above - inclinação entre 45 a 90 graus olhando para baixo para o indivíduo
from below - inclinação entre 45 a 90 graus olhando para cima para o indivíduo
face - imagem focada nos detalhes do rosto, útil para incluir detalhes do rosto especialmente se forem persistentes
full body - vista de corpo inteiro do indivíduo, útil para poses mais complexas
cowboy shot - tag padrão cowboy shot, funciona bem com anime, menos com realismo
looking at viewer, looking to the side, looking ahead
facing to the side, facing the viewer, facing away
looking back, looking forward
tags misturadas criam resultados mistos, mas com saídas variadas
from side, straight-on - câmera horizontal apontada para o lado do indivíduo ou indivíduos
from front, from above - inclinação de 45 graus olhando para baixo da câmera acima à frente
from side, from above - inclinação de 45 graus olhando para baixo da câmera acima ao lado
from behind, from above - inclinação de 45 graus olhando para baixo da câmera acima atrás
from front, from below
from front, from above
from front, straight-on
from front, from side, from above
from front from side, from below
from front from side, straight-on
from behind, from side, from above
from behind, from side, from below
from behind, from side, straight-on
from side, from behind, from above
from side, from behind, from below
from side, from behind, straight-on
Essas tags podem parecer similares, mas a ordem frequentemente cria resultados muito distintos. Usar a tag from behind antes da from side, por exemplo, pesa o sistema para o lado de trás em vez do lado, mas você frequentemente verá o tronco superior torcendo e o corpo angulando 45 graus para qualquer lado.
O resultado é misto, mas definitivamente utilizável.
Traços, coloração, roupas, etc também funcionam
cabelo vermelho, cabelo azul, cabelo verde, cabelo branco, cabelo preto, cabelo dourado, cabelo prata, cabelo loiro, cabelo castanho, cabelo roxo, cabelo rosa, cabelo aqua
olhos vermelhos, olhos azuis, olhos verdes, olhos brancos, olhos pretos, olhos dourados, olhos prateados, olhos amarelos, olhos castanhos, olhos roxos, olhos rosas, olhos aqua
roupa de látex vermelha, azul, verde, preta, branca, dourada, prateada, amarela, marrom, roxa
biquíni vermelho, azul, verde, preto, branco, amarelo, marrom, roxo, rosa
vestido vermelho, azul, verde, preto, branco, amarelo, marrom, rosa, roxo
saias, camisas, vestidos, colares, trajes completos
múltiplos materiais; látex, metálico, jeans, algodão, etc
poses podem ou não funcionar bem com a câmera, podem necessitar ajustes
all fours
kneeling
lying
lying, on back
lying, on side
lying, upside down
kneeling, from behind
kneeling, from front
kneeling, from side
squatting
squatting, from behind
squatting, from front
squatting, from side
controlar pernas e tal pode ser muito exigente, então experimente um pouco
legs
legs together
legs apart
legs spread
feet together
feet apart
centenas de outras tags usadas e incluídas, milhões de combinações potenciais
Use-as em conjunto antes de quaisquer especificadores de traços pessoais, mas depois do prompt para o flux em si.
CRIANDO PROMPTS:
Apenas faça. Digite qualquer coisa e veja o que acontece. O FLUX já tem muita informação, então use as poses etc para aprimorar suas imagens.
Exemplo:
uma mulher sentada em uma cadeira na cozinha, from side, from above, cowboy shot, 1girl, sitting, from side, cabelo azul, olhos verdes

uma super-heroína voando no céu jogando uma pedra, há uma aura ameaçadora brilhante e poderosa ao redor dela, realista, 1girl, from below, roupa de látex azul, colar preto, unhas pretas, lábios pretos, olhos pretos, cabelo roxo
 uma mulher comendo em um restaurante, from above, from behind, all fours, bumbum, tanga
uma mulher comendo em um restaurante, from above, from behind, all fours, bumbum, tanga Funcionou. Geralmente funciona.
Funcionou. Geralmente funciona.
Legitimamente, isso deve lidar com a maioria das loucuras, mas certamente estará fora do meu escopo compreensivo. Tentei mitigar o caos e incluir tags suficientes de pose para fazer funcionar, então tente manter-se nas mais centrais e úteis.
Mais de 430 tentativas falhas separadas para criar isto, finalmente levou a uma série de teorias bem-sucedidas. Farei um relatório completo das informações necessárias e provavelmente liberarei os dados de treinamento usados neste final de semana. Foi um processo longo e difícil. Espero que gostem todos.
Documentação V2:
Na noite passada eu estava muito cansado, então não terminei de compilar a escrita completa e os achados. Espere ela assim que possível, provavelmente durante o dia enquanto estiver no trabalho estarei rodando testes e marcando valores.
Introdução ao Treinamento Flux:
Anterioremente, o PDXL requeria apenas um pequeno conjunto de imagens com tags danbooru para produzir resultados finos comparáveis ao NAI. Menos imagens era uma força pois reduzia o potencial, nesse caso menos imagens não funcionaram. Precisa de algo, mais. Mais fogo com mais poder.
O modelo tem muito ali, mas as diferenças entre os vários dados aprendidos têm variância consideravelmente maior do que esperado inicialmente. Mais variância significa mais potenciais, e não conseguia entender por que funcionaria com essa alta variância.
Após uma pesquisa descobri que o modelo é tão poderoso POR CAUSA DISSO. Ele pode produzir imagens "DIRECIONADAS" baseado na profundidade, onde a imagem é segmentada e sobreposta a outra usando o ruído de outra imagem como guia. Isso me fez pensar, como posso treinar >>ISSO<< sem destruir os detalhes principais do modelo. Primeiro pensei em fazer isso com redimensionamento, mas lembrei do bucketing. Então isso leva à primeira parte aqui.
Basicamente entrei nisso às cegas, configurando baseado em sugestões e determinando resultados baseados no que vi. É um processo lento, então estive pesquisando e lendo artigos paralelamente para acelerar. Se tivesse capacidade mental faria tudo de uma vez, mas sou só uma pessoa e tenho trabalho. Joguei tudo que podia no processo. Se tivesse mais tempo faria 50 dessas simultâneas, mas realmente não tenho tempo para configurar. Eu poderia pagar, mas não poderia configurar.
Usei o que achava melhor baseado na minha experiência com SD1.5, SDXL, e treinamentos PDXL lora. Funcionou razoavelmente, mas há algo claramente errado e entrarei em detalhes.
Formatação de Treinamento:
Fiz alguns testes.
Teste 1 - 750 imagens aleatórias da minha amostra danbooru:
LR UNET - 4e-4
Notei que a maioria dos outros elementos não importavam muito e podiam ficar no padrão, exceto atenção ao bucketing de resolução.
Somente 1024x1024, recorte centralizado
Entre 2k-12k passos
Escolhi 750 imagens aleatórias de uma das pools de tags danbooru uniformes
Rodei o moat tagger nelas e acrescentei as tags ao arquivo, garantindo que não sobrescrevessem
O resultado não foi promissor. O caos era esperado. Introdução de novos elementos humanos como genitais foi ou acerto ou perde, ou simplesmente não existia a maior parte do tempo. Está em linha com o que vi em outras descobertas.
Não esperava que o modelo inteiro sofresse, pois as tags geralmente não se sobrepunham.
Rodei o teste duas vezes e tenho duas loras inúteis com cerca de 12k passos cada. Testes de 1k a 8k mostraram quase nada útil para desvio em direção a qualquer objetivo, mesmo observando os picos e vales das pools de tags.
Há algo mais aqui. Algo que perdi, e que não acho ser humanista ou descrição clip. Há algo... mais.
Perto deste ponto de falha fiz uma descoberta. Este sistema de profundidade é interpolativo e baseado em dois prompts completamente diferentes e desviantes. Esses dois prompts são na verdade interpolativos e cooperativos. Como determina isso não sei, mas vou ler os artigos para entender a matemática envolvida.
Teste 2 - 10 imagens:
LR UNET - 0.001 <<< LR muito poderoso
256x256, 512x512, 768x768, 1024x1024
Os passos iniciais mostravam desvios, similar ao quanto queimava nos testes SD3. Não era bom. O bleeding começou perto do passo 500. Foi basicamente inútil no passo 1000. Sei que basicamente usei repeat aqui, mas parecia um bom experimento para falhar.
Desvios são extremamente danosos aqui. Introduz um novo elemento de contexto e depois o transforma em uma máquina de snacks. Substitui elementos das pessoas por quase nada útil ou por artefatos queimados similar a um inpaint mal configurado. Foi interessante ver o quão resistente o FLUX é e ainda assim funciona. Esse teste mostrou a resiliência do FLUX e foi realmente forte contra minhas tentativas.
Foi uma falha, requer testes adicionais com configurações diferentes.
Teste 3 - 500 imagens de pose:
LR UNET - 4e-4 <<< Isso deveria ser dividido por 4 e receber o dobro dos passos.
Bucketing completo - 256x256, 256x316, etc. Deixei livre e dei muitas imagens de vários tamanhos para bucketing. Foi um resultado inesperado.
O resultado é LITERALMENTE o núcleo deste modelo de consistência, tamanho foi o poder do resultado. Parece ter causado um pouco mais de dano do que pensei, mas foi bastante significativo.
Algo a notar; Anime geralmente não usa profundidade de campo. Este modelo parece AMAR profundidade de campo e blur para diferenciar profundidade. É necessário aplicar algum tipo de depth controlnet a essas imagens para garantir variação de profundidade, mas não sei como fazer isso facilmente. Treinar mapas de profundidade junto com mapas normais pode funcionar, mas pode destruir o modelo devido à falta de prompting negativo.
Mais testes necessários. Mais dados de treinamento necessários. Mais informações necessárias.
Teste 4 - pacote de consistência de 5000:
LR UNET - 4e-4 <<< Isso deve ser dividido por 40 e receber 20x passos, mais ou menos. Treinar algo assim no núcleo do modelo não é simples nem rápido. A matemática atual não é boa para garantir que o núcleo não quebre, por isso rodei isso e liberei os achados iniciais.
Escrevi uma seção inteira aqui mais uma subsequente e ia chegar à seção de achados, mas cliquei para trás no mouse e removeu tudo, então vou reescrever depois.
As grandes falhas:
A taxa de aprendizado estava MUITO ALTA para meus loras iniciais de 12k passos. Todo o sistema é baseado em aprendizado por gradiente sim, mas a taxa que ensinei foi ALTA DEMAIS para reter a informação sem quebrar o modelo. Simplificando, não os queimei, re treinei o modelo para fazer o que queria. O problema é que eu não sabia o que queria, então todo sistema baseava-se em coisas não direcionadas e sem profundidade de gradiente. Logo, estava fadado a falhar, mais passos ou não.
O ESTILO para FLUX não é o que as pessoas pensam que é baseado em PDXL e SD1.5. O sistema de gradiente estiliza sim, mas a estrutura toda sofre muito quando tenta impor INFORMAÇÃO DEMAIS rapidamente. É ALTAMENTE destrutivo comparado às loras PDXL que eram mais conjuntos de imposição. Elas aumentavam o que já existia muito mais do que treinar informações completamente novas.
Achados Críticos:
ALFA, ALFA, e MAIS ALFA<<<< Este sistema roda fortemente em gradientes alfa, não é brincadeira. Tudo DEVE ser tratado especificamente para lidar com gradientes alfa baseados em detalhes fotográficos. Distância, profundidade, proporção, rotação, offset, etc são peças integrais ao modelo e para criar um estilizador composicional adequado tudo precisa de mais que um único prompt.
TUDO deve ser descrito corretamente. Marcação simples danbooru é essencialmente estilo. Você força o sistema a reconhecer o estilo que quer implementar, então não pode impor conceitos novos sem incluir as tags adequadas de alocação de conceito. Senão o vinculador de estilo e conceito falha e dá lixo como saída. Lixo entra, lixo sai.
Treinamento de pose é ALTAMENTE potente usando grandes quantidades de informação de poses. O sistema JÁ reconhece a maioria das tags, só não sabemos quais ainda. Treinar poses para vincular o que EXISTE ao que VOCÊ QUER usando tags específicas será muito potente para organizar tags e afinar.
Documentação de Passos;
v2 - 5572 imagens -> 92 poses -> 4000 passos FLUX
O objetivo original de levar NAI ao SDXL agora foi aplicado ao FLUX também. Acompanhe as versões futuras.
Testes de estabilidade requeridos, até agora mostra capacidade distinta além do que o PDXL pode lidar. Precisa de treinamento adicional, mas é bem mais poderoso do que o esperado para essa baixa contagem de passos.
Acredito que a primeira camada de treinamento de pose usa cerca de 500 imagens, mais ou menos, então essa é a que mais pesa. Os dados completos serão liberados no HuggingFace quando juntar um conjunto organizado e a contagem. Não quero liberar imagens incorretas ou lixo que peguei.
Continue lendo aqui:
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
Referências Importantes:
Eu não fumo, mas o FLUX precisa às vezes.
Um fluxo de trabalho e assistente de geração de imagens. Usei principalmente os nodes básicos do ComfyUI, mas uso outros para experimentar e salvar.
Um modelo de IA poderoso e difícil de entender com enorme potencial.
Sem eles, eu nunca teria pensado em fazer isso. Um grande agradecimento a toda a equipe do NAI pelo trabalho árduo e pela potência monstruosa do gerador de imagens, junto com seu incrível assistente de escrita. Joguem dinheiro para eles.
Criaram o Flux e merecem grande parte do crédito pela flexibilidade do modelo. Eu só estou refinando e direcionando o que é quase um leviatã para seu destino.
Um assistente de tags poderoso e potente. Quase escrevi o meu próprio até encontrar esta maravilha.
Usei para treinar minhas versões Flux. É um pouco sensível e meio difícil, mas funciona bem em vários sistemas e faz o trabalho.
Não posso esquecer o rival no campo de batalha. A besta é um monstro absoluto gerando imagens com enorme campo de gradiente, uma ferramenta valiosa para pesquisa e aprendizado, e grande inspiração para esta direção e progresso.

Detalhes do Modelo
Tipo de modelo
Modelo base
Versão do modelo
Hash do modelo
Criador
Discussão
Por favor, faça log in para deixar um comentário.
![Old Consistency V32 Lora [FLUX1.D/PDXL] Feminine v1.1 - e500 PDXL](https://diffus-s3.b-cdn.net/images/gallery/thumbnails/model_533690_be70b0496a7b4f37b5ae5a53be1892d6.webp?fit=cover)
















































