Stable Cascade - base
Palavras-chave e Tags Relacionadas
Imagens em destaque


Parâmetros Recomendados
steps
resolution
Dicas
Use a versão de 3,6 bilhões de parâmetros do Estágio C para melhores resultados, pois o finetuning principal foi feito nela.
Use a variante de 1,5 bilhão de parâmetros para o Estágio B para se destacar na reconstrução de detalhes pequenos e finos.
O modelo é bem adequado para treinamento e inferência eficientes devido ao espaço latente menor e suporta extensões como finetuning, LoRA, ControlNet, IP-Adapter e LCM.
O modelo é destinado apenas para fins de pesquisa e não deve ser usado para gerar representações factuais ou violar a Política de Uso Aceitável da Stability AI.
Rostos e pessoas podem não ser gerados corretamente, pois o autoencoding do modelo é com perda.
Patrocinadores do Criador
Demonstrações:
- multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
- ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Demonstrações:
multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Stable Cascade
Este modelo é baseado na arquitetura Würstchen e sua principal
diferença para outros modelos como Stable Diffusion é que ele trabalha em um espaço latente muito menor. Por que isso é
importante? Quanto menor o espaço latente, mais rápida pode ser a inferência e mais barato se torna o treinamento.
Quão pequeno é o espaço latente? Stable Diffusion usa um fator de compressão de 8, resultando em uma imagem 1024x1024
codificada para 128x128. Stable Cascade alcança um fator de compressão de 42, significando que é possível codificar uma
imagem 1024x1024 para 24x24, mantendo reconstruções nítidas. O modelo condicional de texto é então treinado no
espaço latente altamente comprimido. Versões anteriores desta arquitetura alcançaram uma redução de custo de 16x sobre Stable
Diffusion 1.5. <br> <br>
Portanto, este tipo de modelo é bem adequado para usos onde a eficiência é importante. Além disso, todas as extensões conhecidas
como finetuning, LoRA, ControlNet, IP-Adapter, LCM etc. também são possíveis com este método.
Detalhes do Modelo
Descrição do Modelo
Stable Cascade é um modelo de difusão treinado para gerar imagens a partir de um prompt de texto.
Desenvolvido por: Stability AI
Financiado por: Stability AI
Tipo de modelo: Modelo generativo texto-para-imagem
Fontes do Modelo
Para fins de pesquisa, recomendamos nosso repositório StableCascade no Github (https://github.com/Stability-AI/StableCascade).
Repositório: https://github.com/Stability-AI/StableCascade
Visão Geral do Modelo
Stable Cascade consiste em três modelos: Estágio A, Estágio B e Estágio C, representando uma cascata para gerar imagens,
daí o nome "Stable Cascade".
Os Estágios A & B são usados para comprimir imagens, similar ao que o VAE faz no Stable Diffusion.
No entanto, com esta configuração, pode-se alcançar uma compressão muito maior das imagens. Enquanto os modelos do Stable Diffusion usam um
fator espacial de compressão de 8, codificando uma imagem com resolução de 1024 x 1024 para 128 x 128, o Stable Cascade alcança
um fator de compressão de 42. Isso codifica uma imagem 1024 x 1024 para 24 x 24, enquanto ainda é capaz de decodificar a imagem com precisão.
Isso traz o grande benefício de treinamento e inferência mais baratos. Além disso, o Estágio C é responsável
por gerar os pequenos latentes 24 x 24 dado um prompt de texto. A figura a seguir mostra isso visualmente.
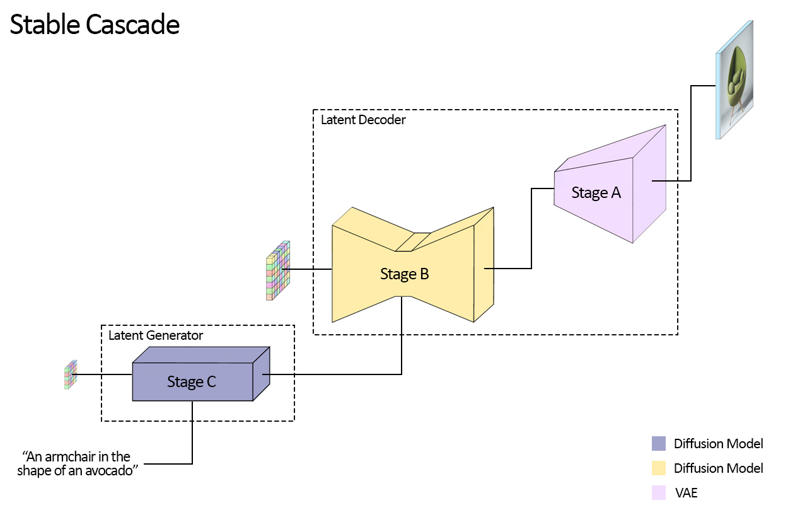
Para este lançamento, estamos fornecendo dois checkpoints para o Estágio C, dois para o Estágio B e um para o Estágio A. O Estágio C vem com
versões de 1 bilhão e 3,6 bilhões de parâmetros, mas recomendamos fortemente usar a versão de 3,6 bilhões, pois a maior parte do trabalho foi
feita em seu finetuning. As duas versões para o Estágio B somam 700 milhões e 1,5 bilhões de parâmetros. Ambas alcançam
excelentes resultados, porém a de 1,5 bilhão se destaca na reconstrução de detalhes pequenos e finos. Portanto, você obterá
os melhores resultados se usar a variante maior de cada um. Por fim, o Estágio A contém 20 milhões de parâmetros e é fixo devido
ao seu tamanho pequeno.
Avaliação
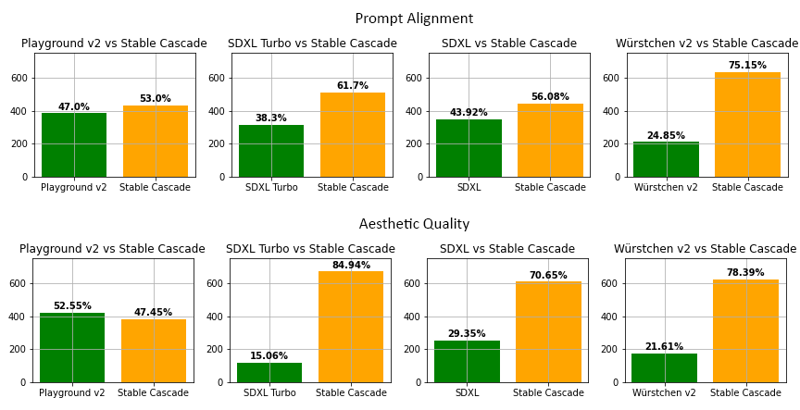
De acordo com nossa avaliação, Stable Cascade apresenta melhor desempenho tanto no alinhamento de prompt quanto na qualidade estética em quase todas
comparações. A imagem acima mostra os resultados de uma avaliação humana usando uma mistura de parti-prompts (link) e prompts estéticos. Especificamente, Stable Cascade (30 passos de inferência) foi comparado contra Playground v2 (50 passos de inferência), SDXL (50 passos de inferência), SDXL Turbo (1 passo de inferência) e Würstchen v2 (30 passos de inferência).
Exemplo de Código
⚠️ Importante: Para o código abaixo funcionar, você deve instalar diffusers a partir deste branch enquanto o PR está em desenvolvimento.
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Gato antropomórfico vestido como piloto"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
#Agora decoder_output é uma lista com suas imagens PILUsos
Uso Direto
O modelo é destinado a fins de pesquisa por enquanto. Áreas e tarefas possíveis de pesquisa incluem
Pesquisa em modelos gerativos.
Implantação segura de modelos que têm potencial para gerar conteúdo prejudicial.
Investigar e entender limitações e vieses dos modelos gerativos.
Geração de obras de arte e uso em design e outros processos artísticos.
Aplicações em ferramentas educacionais ou criativas.
Usos excluídos são descritos abaixo.
Uso Fora do Escopo
O modelo não foi treinado para ser uma representação factual ou verdadeira de pessoas ou eventos,
e portanto usar o modelo para gerar tal conteúdo está fora do escopo das capacidades deste modelo.
O modelo não deve ser usado de forma que viole a Política de Uso Aceitável da Stability AI.
Limitações e Viés
Limitações
Rostos e pessoas em geral podem não ser gerados corretamente.
A parte de autoencoding do modelo é com perda de dados.
Recomendações
O modelo é destinado apenas para fins de pesquisa.
Como Começar com o Modelo

Detalhes do Modelo
Tipo de modelo
Modelo base
Versão do modelo
Hash do modelo
Criador
Discussão
Por favor, faça log in para deixar um comentário.
Coleção de Modelos - Stable Cascade
Imagens por Stable Cascade - base
Imagens com anime










Imagens com arte










Imagens com modelo base

Imagens com logo










