AlbedoBase XL - v3.1-Large
精選圖片






推薦提示詞
(incredibly ultra lifelike, perfect professional precise, masterpiece, extremely beautiful, light and shadow
推薦反向提示詞
strabismus
(worst quality, normal quality, score_3, score_4
推薦參數
samplers
steps
cfg
resolution
vae
提示
若圖像生成無結果,嘗試切換到 CLIP SKIP 2 或略微修改提示詞如變換詞序或用詞。
使用句子形式提示詞通常比標籤列表提示詞更能提升圖像質量。
留空負面提示欄位通常可以獲得更佳圖像效果。
使用前請參考規格表尋找最佳設定。
嘗試使用特定負面提示詞如「斜視」來解決眼睛不對稱或像素化等問題。
版本亮點
• 使用 V3 版本遞迴腳本合併了超過 50 個精選最新的 SDXL 模型版本。
創作者贊助
如果您覺得模型有幫助,請考慮支持我們。您的捐助將全部用於推動 SDXL 社區的發展。
🙋🏼♂️ 加入我們 (discord) ㅤ|ㅤ 🛒 購買 ㅤ|ㅤ 🌱 捐贈
如果您覺得模型有幫助,請考慮支持我們。您的捐助將全部用於推動 SDXL 社區的發展。
🙋🏼♂️ 加入我們 (discord) ㅤ|ㅤ 🛒 購買ㅤ |ㅤ 🌱 捐贈
AlbedoBase XL (SFW&NSFW)
不需要使用 refiner,並且包含 VAE。
目標
Stable Diffusion XL 擁有 35 億參數(不包含 Refiner),約為 SD v1.5 版本的 3.6 倍。我相信這不僅僅是數字,而是能帶來性能顯著提升的關鍵。
社群持續爆炸性的貢獻讓 SD v1.5 整體性能大幅提升,因此我正努力在此 XL 版本中最佳還原這些改進。
我的目標是直接測試所有公開上傳至 Civitai 的 Checkpoints 和 LoRAs,並用多重篩選後判定最佳的資源來合併。這將超越像 Midjourney 這類企業圖像生成 AI 的性能。
目前,AlbedoBase XL v3.1 Large 已融合約 200 個精選檢查點和 251 個 LoRA。
更新紀錄
v3.1-Large
• 使用 V3 版本遞迴腳本合併了超過 50 個精選最新的 SDXL 模型版本。
規格表(370.7 MB): 下載


v3-mini
非常抱歉讓您久等了。
我處理一些個人事項,同時在製作新版過程中也遇到健康問題。即使現在寫這段文字,我仍在與挑戰奮鬥。
我覺得只做簡短更新不足夠,因此借此機會分享較為詳盡的說明,請您體諒。
自 2.0 版本推出後,我一直自學深度學習。沒有正式學歷,除了一些程式設計天賦外,背景僅限藝術領域。整合數學和科學知識不足,因此很難做出重大突破,但這段自學與研究的經歷是我人生的寶貴財富。
最近我偶然想到一個可能是重大突破的點子。從 2.0 版本開始反覆修改數百條公式和方法,我成功開發出一套相當有趣且成功的算法。模型合併基於 SDXL1.0 和 SD1.5,並挑選其他用心編輯的模型,歸類為「ANIME」、「REALISM」、「ARTISTIC」、「NSFW」及「BASE」五大分類,作為數據集輸入合併算法。成果相當迷人。
然而,算法開發雖具挑戰性,性能測試階段更加艱難。我身心健康因此大幅衰退,甚至明白獨自苦撐不下去,這才決定發布此版本。
現在很高興宣布期待已久的 AlbedoBaseXL V3 Mini 版本發布。此模型規模較小,但不侷限任何特定領域,在多個領域表現優異,有潛力成為 SDXL1.0 的新基礎模型。(參考:我的合併算法不是「線性合併」,基本上可視為新微調模型。)
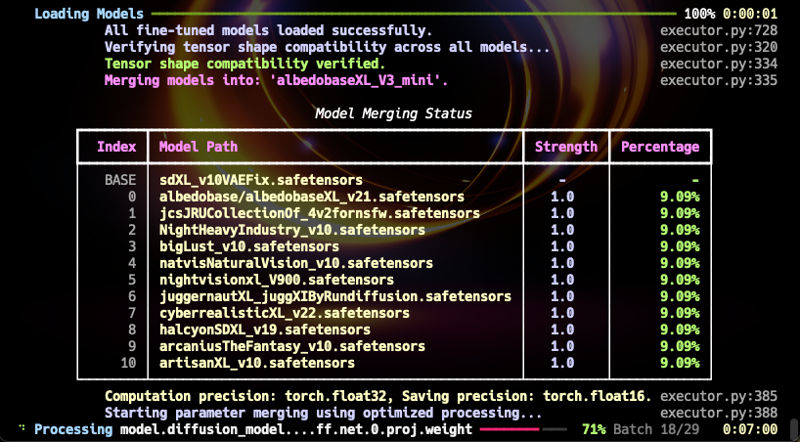
此模型與現有 AlbedoBase 系列一樣多才多藝,並且在各方面超越以往版本。(NSFW 內容雖非極端,但表現範圍較 v2.1 等前版更廣。專門的 NSFW 合併模型將於未來發布。)
另外,我注意到最近許多分享模型逐漸採用禁止合併或外部商業用途的許可證。這令人遺憾,導致我無法使用一些優秀模型進行合併。
感謝那些提供免費許可證,讓其用心製作的高質量模型可以用於合併的模型開發者們。
我將很快回歸。
我熱切期待您在 ANIME、REALISM、ARTISTIC、2.5D、3D 及 NSFW 等多領域進行性能測試。
作為模型開發者,我們只是播下種子。最終由您,模型使用者及藝術家,培育這些種子,綻放花朵與成果。
一如既往,感謝您的支持。
若想以小額資助支持我的工作,請考慮以下連結。我目前無法穩定就業,生計尚不明朗。
規格表(380.5 MB): 下載


v2.1
使用新合併算法和公式重新合併並調整 v0.1 至 2.0。
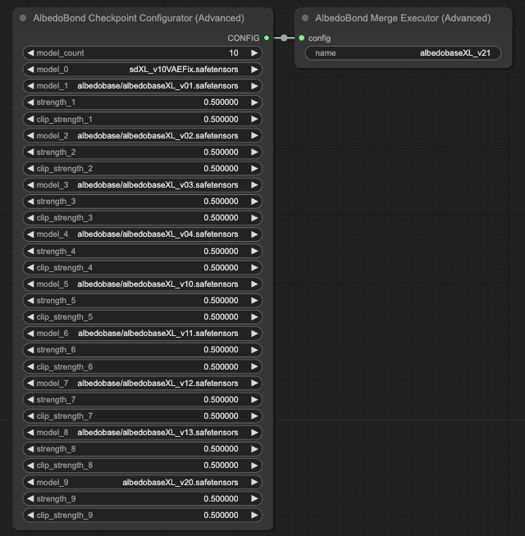
規格表(424.5 MB): 下載

v2.0
感謝所有在AlbedoBase XL Pre 版本提供協助的人們。沒有你們,發布日期可能會延後很多。非常感謝!
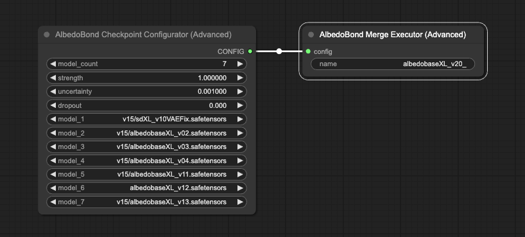
我編寫了自訂腳本,將現有的 AlbedoBase XL 模型合併為一體。細緻調整所有 U-NET 和 CLIP 模塊的行列權重,依據我獨特的公式。
若圖像生成時出現無結果的錯誤,請切換到 CLIP SKIP 2 或稍微修改提示詞,如改變詞序或用詞!可能出現 CLIP 無法識別的提示組合。此時可調整詞序、替換字詞或簡單使用 CLIP SKIP。未來我會像 v1.3 一樣循序解決這些問題。
規格表(403.5 MB): 下載
v1.3
為展現模型隨機性所致品質,我將所有取樣展示圖的種子值固定為 '9',並立即生成。
尤其此版本,因負面提示影響顯著,負面提示欄位留空往往能產生優質效果。
規格表(438.7 MB): 下載

如圖所示,隨著步數增加,對所有採樣器均適用,且品質提升。
由於我開發並合併的 LoRA 影響,與標籤(詞列表)相比,使用句子形式提示詞能直接提升品質。
我合併了 45 個檢查點和 7 個 LoRA。之後按序融合 AlbedoBase v0.4 和 v0.3 約 0~5% 不等,以喚醒過時稀釋合併模型。
7 個 LoRA 中,有一個是我創建的。它使用 GPT4-V 分析並標註了總計 174 張高品質圖片的說明文字。合併此 LoRA 後,圖像驚人地清晰,並且對提示詞理解極佳。
我自創 LoRA專為 Ko-fi Creative 等級以上支持者提供購買。
v1.2
合併了 22 個最新檢查點。
規格表(565.6 MB): 下載
v1.1
穩定性提升。
更細緻。
若您是進階使用者,推薦使用 1.0 版本。1.0 版本找到合適設定後,能輸出更鮮明艷麗的作品。
規格表(349.7 MB): 下載
v1.0
合併了 106 個 LoRA。
合併了 19 個檢查點。
模型輸出結果隨設定不同而異,使用前請參考規格表。
我發現使用某些特定負面提示可解決眼睛不對稱或圖像像素化問題。規格表可能因 CPU 或 GPU 設備而異,僅供參考。請嘗試幾個負面提示(如斜視)提升品質。隨合併 LoRA 數量增加,無法兼顧所有設定,但我希望您專注於 1.0 版本此優勢,能透過適合設定創造出驚人品質作品。未來我將推出更穩定版本。
您可於展示頁或透過搜尋尋找有用設定值。
一如既往,為獲得最佳結果,建議負面提示欄位留空。
v1.0 製作繁重,我會短暫休息。希望您喜歡此模型,若合併請在 Civitai 分享免費資源,大家共同優化。
規格表(479.4 MB): 下載
v0.4
合併了 132 個 LoRA。
合併了4個檢查點。
規格表: 下載
v0.3
所有採樣器均有改善。
達到逼真寫實效果。
穩定性提升。
規格表: 下載
v0.2
在圖像清晰度和細節上有顯著提升。
改善手腳細節表現。
美学方面重大提升;包含構圖、抽象感、流動性、光影及色彩等。
v0.1
在適當微調 SDXL1.0 模型後,精心且有目的地合併逾 40 個高質量公開模型於 Civitai 平臺。
測試主要聚焦於以最少提示詞達到最高品質,尚未確認大量提示詞時品質提升的幅度。(請自行測試並分享結果)
通常最美的效果出現在現實與動畫的中間點。
然而只要使用適當提示詞,基本上沒有什麼無法表現的。(我認為本模型作為合併基底模型具豐富價值,且優於其他,僅此目前為 v0.1 版本說明)







































