Animagine XL 4.0 - v4 Opt
精選圖片





推薦提示詞
1girl, firefly (honkai: star rail), honkai (series), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
masterpiece, high score, great score, absurdres
1girl, sensitive, looking at viewer, solo, masterpiece, high score, great score, absurdres
推薦反向提示詞
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
推薦參數
samplers
steps
cfg
resolution
提示
使用基於標籤的描述及標籤排序法獲得更佳效果:1girl/1boy/1other,角色名,系列名,分級,其他標籤,最後加入質量提升。
在提示末尾添加質量提升標籤:masterpiece、high score、great score、absurdres。
使用推薦的負面提示詞以避免不必要的瑕疵與錯誤。
最佳 CFG Scale 範圍為4到7,建議設為5。
建議採樣步數為25至28,推薦28步。
首選採樣器為 Euler Ancestral(Euler a)。
注意模型限制,如複雜人體解剖及文字渲染困難。
近期角色可能因訓練數據有限而準確度較低。
版本亮點
隨著Animagine XL 4.0 Opt(優化版)發布,模型透過新增數據集進一步精煉,加強了其一般用途的性能。此次更新帶來多項改進:
提升穩定性,獲得更一致的輸出
增強人體解剖比例的準確度
減少生成圖像中的噪點與瑕疵
修正低飽和度問題,使色彩更豐富
提升色彩準確性,結果更具視覺吸引力
創作者贊助
支持 Animagine XL 開發
- 捐贈 ETH/USDT 至
0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C - GitHub 贊助:https://github.com/sponsors/cagliostrolab/
- 加入 Discord 社群:https://discord.gg/cqh9tZgbGc
請閱讀我們詳盡的提示指導,詳見 Cagliostrolab Blog
概覽
Animagine XL 4.0,亦稱作 Anim4gine,是極致的動漫主題微調SDXL模型,也是Animagine XL系列的最新作品。雖為續作,此模型基於Stable Diffusion XL 1.0重新訓練,使用了來自多個來源的840萬張多樣化動漫風格圖片(知識截止於2025年1月7日),微調時長約2650 GPU小時。與前版本相同,該模型使用標籤排序法進行身份和風格訓練。
隨著 Animagine XL 4.0 Opt(優化版) 發佈,模型透過新增數據集進一步精煉,提升了穩定性、人體解剖準確度、降噪效果、色彩飽和度及整體色彩準確度。這些改良使 Animagine XL 4.0 Opt 更加穩定且視覺上更具吸引力,同時保持系列一貫的高品質。
更新紀錄
- 2025-02-13 – 新增 Animagine XL 4.0 Opt 和 Animagine XL 4.0 Zero
穩定性提升以獲得更一致的輸出
人體解剖增強,比例更精確
生成圖像中的噪點與瑕疵減少
修正低飽和度問題,色彩更豐富
提升色彩準確性,結果更悅目
- 2025-01-24 – 初始發佈
模型詳情
模型類型:基於擴散的文本到圖像生成模型
模型描述:專為根據文本提示生成及修改動漫主題圖像的模型
使用指南
提示指引摘要可見於以下圖片。

1. 提示結構
本模型以基於標籤的描述和標籤排序法訓練。請使用此結構化模板:
1girl/1boy/1other, 角色名, 所屬系列, 分級, 其他任意順序的標籤,最後加上質量提升
2. 質量提升標籤
在提示末尾添加以下標籤:
masterpiece, high score, great score, absurdres
3. 推薦的負面提示
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. 最佳設定
CFG Scale:4-7(建議為5)
採樣步數:25-28(建議為28)
推薦採樣器:Euler Ancestral(Euler a)
5. 推薦解析度
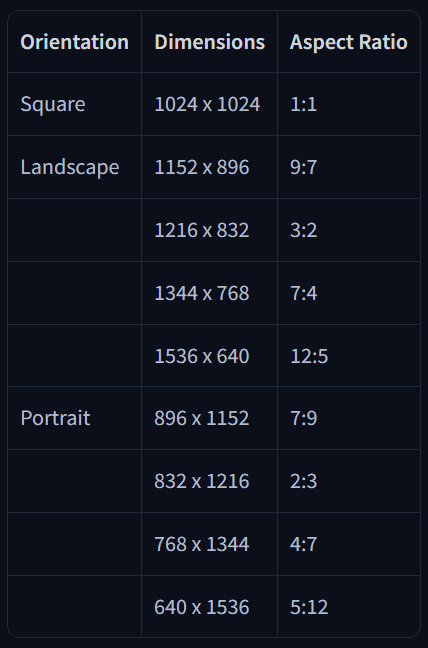
6. 最終提示範例結構
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
特殊標籤
本模型支援多種特殊標籤,用於控制圖像生成過程中的不同面向。這些標籤經過精心權重設置與測試,以確保各種提示均能獲得一致的結果。
質量標籤
質量標籤是影響整體圖像質量與細節水平的基本控制參數。可用質量標籤如下:
masterpiecebest qualitylow qualityworst quality
評分標籤
評分標籤比基本質量標籤更精細控制圖像品質,對控制輸出質量影響更大。可用評分標籤如下:
high scoregreat scoregood scoreaverage scorebad scorelow score
時間標籤
時間標籤可根據特定時期或年份影響藝術風格,適用於生成帶有年代特色的作品。支援的年份標籤如下:
year 2005year {n}year 2025
分級標籤
分級標籤用於控制生成圖像的內容安全等級,應負責任地使用並遵守相關法律及平台政策。支援的分級如下:
safesensitivensfwexplicit
訓練資訊
模型採用尖端硬體與優化超參數訓練,以確保最高質量輸出。以下為訓練過程中使用的詳細技術規格與參數:

致謝
此長期項目得以實現,離不開Stability AI、Novel AI及Waifu Diffusion Team的突破性工作、創新貢獻及詳盡文件。我們特別感謝提供啟動資金的Main,助力我們邁過V2階段。此版本衷心感謝社群各位持續支持,尤其包括:
Moescape AI:我們重要的模型分發及測試合作夥伴
Lesser Rabbit:提供重要計算及研究資助
Kohya SS:打造全面開源訓練框架
discus0434:創造業界領先的開源美學預測器2.5
早期測試者:致力於提供寶貴回饋與全面質量保證
貢獻者
我們向對本項目做出重大貢獻的團隊成員致以最誠摯的感謝,部分成員如下:
模型
Gradio
關係、財務及質量保證
數據
募款重新開放!
我們很高興推出透過 GitHub Sponsors 支持訓練、研究及模型開發的新募款方式。您的支持助我們推動AI的可能性。
您可以幫助我們:
捐款:可透過ETH或USDT捐款至以下地址。
分享:推廣我們的模型並分享您的創作!
回饋:告訴我們如何改進。
捐款地址:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
Github 贊助頁: https://github.com/sponsors/cagliostrolab/
為何我們使用加密貨幣?
當我們最初透過 Ko-fi 募款並使用 PayPal 作為提款方式時,PayPal 帳戶被標記並最終被封禁,即使我們努力說明專案用途。不幸的是,我們被迫退還所有捐款,並失去可靠的支持渠道。為避免類似問題並確保透明度,我們現已改用加密貨幣作為募款途徑。
想用非加密貨幣方式捐款?
雖然我們在 PayPal 使用上遇到不佳經驗,若您願意支持但不想使用加密貨幣,歡迎通過 Discord 伺服器 聯絡我們了解其他捐款方式。
加入我們的 Discord 伺服器
歡迎加入我們的 Discord 伺服器: https://discord.gg/cqh9tZgbGc
限制
提示格式:限制於基於標籤的文字提示;自然語言輸入可能效果不佳
人體解剖:處理複雜人體解剖細節(特別是手部姿勢與手指數量)可能有困難
文字生成:圖像中同時生成文字目前不被支持且不建議使用
新角色:近期角色可能因訓練數據有限而準確度較低
多角色:多角色場景可能需仔細設計提示詞
解析度:高解析度(例如1536x1536)可能出現劣化,因為訓練使用原始 SDXL 解析度
風格一致性:可能需要使用特定風格標籤,因訓練更注重身份保持而非風格一致
授權
本模型採用Stability AI 原版CreativeML Open RAIL++-M 授權,無任何修改或額外限制。授權條款與原SDXL授權完全一致,包括:
✅ 允許:商業使用、修改、分發、私人使用
❌ 禁止:非法行為、有害內容生成、歧視與剝削
⚠️ 要求:包含授權副本、註明變更、保留通知
📝 保證:以「現狀」提供,無任何保證
完整且具權威的條款請參考原版 SDXL 授權。













