Colossus Project Flux - v10_Behemoth_AIO_FP16
相關關鍵字和標籤
精選圖片

推薦提示詞
photography of a young woman as an (goth) with (razor cut haircut), a sports car, soft lighting, spray painted with a intricate comic style robot theme and "COLOSSUS X" cyberpunk theme, projection lighting, its night and its raining, biopunk, the road is reflecting shot on Pentax K-1 Mark II with Pentax FA 43mm f-1.9 Limited, Neutral color palette heterochromia (blue and brown) Mixed race, shot on Pentax K-1 Mark II with Pentax FA 43mm f-1.9 Limited, photo by Tami Bone
推薦反向提示詞
blurry
blurry, low res
推薦參數
samplers
steps
cfg
resolution
vae
提示
使用負向提示詞 'blurry' 以提升圖像品質。
為達最佳真實感,建議 cfg 指導強度介於 1.5 至 3,1.8 為真實圖像的良好平衡值。
推薦使用的取樣器包括 Euler、Heun、DPM++ 2M、deis 及 DDIM,Simple 排程器表現良好。
某些檢查點須關閉 Flux 引導比例,改用 cfg 比例。
建議使用一體化模型,因其內建 Clip_L、T5xxl 及 VAE,使用方便。
安裝及工作流程請參考描述中的 civitai.com 官方指南。
存在兩個量化版本 FP4 及 int4:FP4 適用於 Nvidia 50xx 顯卡,int4 適用於 40xx 及以下(至少需 20xx 顯卡)。
SVDQ Nunchaku 量化大幅縮減模型大小,提升生成速度,僅有細微品質損失。
版本亮點
此版本仍屬實驗階段。主要焦點是取得更真實結果,也成功減少部分「Flux 線條」。此版本基於 Colossus Project V5.0_Behemoth、V9.0 及另一個我稱為 "Ouroborus Project" 的項目。
FP16 版本相當穩定。我也即將發布 FP8 版,此版相當優良但不及 FP16 穩定。
你可以自己試驗,告訴我對此版本的看法。
祝創作愉快 :-)
創作者贊助
如果你喜歡此模型並想支持創作者,請考慮通過 Ko-fi 捐款。
請查看由 Muyang Li 以及 Nunchakutech 完成的 FP4/int4 量化版本。
工作流程和安裝指南可參考 civitai.com/articles/17313 與 civitai.com/articles/17358。
轉換與量化代碼庫訪問:GitHub ComfyUI-nunchaku。
在一座山脈深處,沉睡著一個巨人,既可幫助人類,也可能帶來毀滅……
一個巨像崛起……
繼 SDXL 系列後,現在是此項目 FLUX 系列的時候……這次我從零開始訓練。訓練中我使用了自己的影像,利用我快速的 Flux 模型 DemonFlux/Colossus Project schnell 加上我的 SDXL Colossus Project 12 作為精煉器創造它們。
此 SD Flux 檢查點幾乎能生成所有類型圖像……Colossus 在生成極度真實照片、動漫及藝術圖像方面表現出色。
如果你喜歡,歡迎給我反饋。如果你願意支持我,可以通過這裡幫忙。我花了不少錢建造了一台真正能訓練 Flux 模型的電腦……訓練和測試也耗費大量時間和電力……
https://ko-fi.com/afroman4peace
版本 V12 "Hephaistos"
發布這個檢查點讓我又喜又悲……V12 將是該系列的最後一個檢查點……主要原因是即將實施的歐盟人工智能法律……另一原因是 Flux .1 DEV 本身的許可證。謝謝大家的支持!過去一年我投注大量時間於此專案。現在是時候轉向新的專案了。
無論如何……我會以一個高點結束這個系列……
V12 基於 V10B "BOB",但將這系列最佳部分整合合併於一個檢查點。(這是利用新合併方法完成,耗時約 1 小時 30 分鐘,使用了我所有 128GB 記憶體。)我也相比 V10 強化了臉部和皮膚紋理。眼睛更加真實且更具「生命感」。
親自試試並給我 V12 的反饋。由於網路較慢,會先上傳 FP8_UNET,接著是 FP8 "一體化" 版本,然後是 FP16_unet 和 FP16_BEHEMOTH。我也會嘗試將其轉換成 int4 和 fp4(祝我好運)。
一如既往,請給我 V12 的反饋……
版本 V12 "Behemoth"(一體化)
此「一體化」模型是我 V12 系列最佳的版本……當然也是最大的一個 :-)
Behemoth 內建了定制的 T5xxl 和 Clip_l。如果你偏好品質勝於數量,這個檢查點適合你!
版本 V12 FP4/int4
感謝 Nunchakutech 的 Muyang Li 進行 V12 量化。https://huggingface.co/nunchaku-tech 及其驚人的 Nunchaku!
此版本令人震撼,結合了前所未有的品質與速度。
注意!
有兩個版本 FP4 和 int4。FP4 僅適用於 Nvidia 50xx 顯卡!int4 適用於 40xx 及以下型號。(至少需要 20xx 系列顯卡)
你也可以直接下載兩個版本:https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
安裝指南及工作流程
這裡有快速安裝指南和進行中工作流程。
https://civitai.com/articles/17313
詳細工作流程指南
https://civitai.com/articles/17358
我仍在製作新的 Nunchaku 工作流程……以下工作流程仍處於進行中,我會在週末補充詳細文章。
版本 V12 FP16_B_variant
因為我凌晨兩點犯的小失誤,我誤命名並上傳了「錯誤」檢查點。這是非常實驗性的檢查點,原不打算公開。測試不多,但在展示時表現出色。或許比標準版還好。
它偏向亞洲臉孔,因為我想測試混入我仍在開發的側專案。告訴我你對此檢查點的體驗 :-)
版本 V12 一體化 FP8
此版本為 V12 的一體化版本,所有 Clip 模型均內嵌其中。輸出與 FP8_unet 加上我自定義的 clip_l 相同。
版本 V12 GGUF Q5_1
這版是顧客需求產生,品質不錯。
版本 V10B "BOB"
這是 V10 的替代版本,旨在改進 V10 的 FP8 版本。整體來說 FP8 版更精準、色彩更好。最近較忙(現實生活優先),所以發布慢。告訴我你喜歡這版嗎。我也有 "BOB" 的 FP16 版本。根據反饋,也會考慮發布 int4 版本。
工作流程:
這是 V12 和 V10 的工作流程:https://civitai.com/articles/17163
版本 V10_int4_SVDQ "Nunchaku"
首先感謝 theunlikely https://huggingface.co/theunlikely 將 FP16_Unet 轉換成 int4_SVDQ。訪問他的頁面點贊支持。
這版本大致與 FP8 版相當。即使在我工作流程的普通模式下,速度比普通模型快約 2 至 3 倍……在「快模式」可於 3090ti 上約 19 秒渲染 2MP 圖像。
什麼是 SVDQ "Nunchaku"?
這種新量化方法可將 Flux 模型(此為原生 FP16 模型)從 24GB 壓縮至約 6.7GB。不僅如此,生成速度也前所未有地提升,且質量損失極小。雖然和 32GB_Behemoth 略有差異,但運行此版本需要更多 VRAM/RAM。
更多資訊請訪問:https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
安裝:請參考我的工作流程/安裝指南:https://civitai.com/articles/15610
版本 V10 "Behemoth" (FP16_AIO)
此版本仍在實驗階段。主要焦點是獲得更真實結果,同時減少「Flux 線條」。本版本基於 Colossus Project V5.0_Behemoth、V9.0 及我稱為 "Ouroborus Project" 的另一個項目。
FP16 版本非常穩定。我也即將發布 FP8 版本,該版本表現也很好但不如 FP16 穩定。
你可以試用並告訴我看法。
願你創作愉快 :-)
版本 V9.0:
必須多說點……首先為何會是 V9.0?
最近搬入新公寓,因為網絡供應商故障,沒有真正網路連線……搬家期間,我讓電腦持續運行。結果產生很多(多數破損)檢查點。不過我有些不錯的 V8 版本,或許也會發布。
有什麼改變?
我將 V5.0 的最佳結果重新訓練於面部和皮膚紋理,並針對腳部/腿部做了解剖訓練。V5.0 有時頭部和腳部會被截斷,我想我修正了部分問題。
此外我增加了更多自有風景圖像訓練。是的,這都是搬家時完成的……大約兩週的整體訓練時間,計算時間不便宜(每小時電費約 0.25 歐元)。
無論如何希望你喜歡此版本。如想支持,請上传好圖或捐贈給我,如在 Buzz 或 Kofi。
告訴我你的想法 :-)
版本 5.0:
V5.0 基於 V4.2 和即將發布的 V4.4,增加了皮膚細節和整體解剖訓練,主要修復了手部和乳頭等問題。臉部細節更精細。我也嘗試修正了一些細微的 Flux 線條。
整體來說,此版本比 V4.2 更真實,細節更豐富。如同 V4.2,此版本也是混合去蒸餾模型。基本上可以用與 V4.2 相同的設置。
這裡有新的工作流程可供嘗試:https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
告訴我你比較喜歡此版本還是 4.2 或 V2.1……
版本 4.4 "Research":
為了完整性,我加入此版。其比 V4.2 稍微真實,是版本 5.0 的基礎。可使用 V5.0 和 V4.2 的工作流程。
版本 4.2:
此版本基本是 Demoncore Flux 與 Colossus Project Flux 的進階版。目標是獲得更穩定結果與更好皮膚紋理、手部及多樣臉孔。訓練了混合模型,其中部分為 Demoncore Flux。也加強了乳頭和 NSFW 細節。告訴我你是否偏好 V4.2 而非 2.1 :-)
展覽圖像只使用 SDXL 解像度或 2MP 解像度原生圖像(例如 1216x1632)。此模型可處理更高解像度,我測試至 2500x2500,建議以約 2000x2000 為佳。
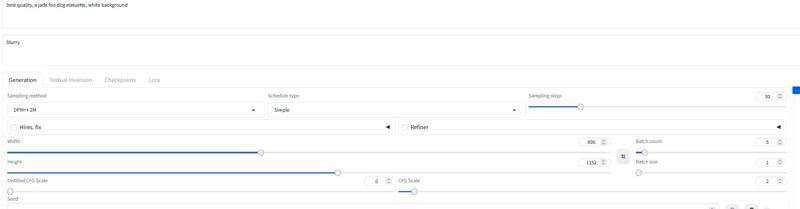
建議設置約 30 步驟和 2-2.5 cfg,工作流程中多用 2.2 或 2.3。展覽使用 DPM++ 2M 和簡單排程器。
我將陸續補充更多版本,但聖誕節前時間有限……
設置
我很快會新增專用 Comfy 工作流程。你可以先下載並打開展覽圖片。
「一體化版本」也適用於 Forge。
基本上使用與版本 2.1(如下)相同的設置。
設定 20-30 步驟,cfg 約 2.2 左右。
版本 2.1 去蒸餾實驗合併版(MERGE)
此版本完全不同,實際運作也不同於普通 Flux 模型!
它是我版本 2.0 與一個去蒸餾版本https://huggingface.co/nyanko7/flux-dev-de-distill間的實驗性合併。部分偶然,但結果驚人。細節出色,對提示詞反應靈敏……下一步是直接在去蒸餾模型上訓練。我已做一些測試 Lora。這屬高度實驗性,若發現錯誤請告知,也歡迎分享好或不佳的圖像,有助於改善。可嘗試使用 2.0 版,看看哪種檢查點適合你。
注意!
普通 Flux 工作流程不適用此版本。請下載我的工作流程使用!
你也可自行探索,但請勿因圖像不佳責怪我。這是高度實驗模型,以下列出缺點……
該檢查點優缺點:
本檢查點能創造極致細節,但代價是比普通 Flux 檢查點慢。優點是通常不需額外放大。此模型使用 cfg 比例代替 Flux 引導比例,因此不適用標準工作流程。
支援負向提示,協助剔除不想要的圖像元素。
有時會出現偽影,可通過小幅簡單放大修復(我正在努力改進)。這情況非模型本身問題,而是工作流程問題。若發生,可嘗試首次放大比例設為 1.14 而非 1.2。

版本 2.1 設置與工作流程:
工作流程請見:https://civitai.com/articles/8419
設置:與普通 Flux 不同,不需 Flux 引導比例,使用 cfg 比例。我在工作流程多用 3 cfg,某些圖像則需較低值。
最重要的是關閉 Flux 引導比例……
未用工作流程時我測試過 30 步驟,2-3 cfg。Forge 也建議用此設置,歡迎試驗。
建議在負向提示中加入 "blurry" 字詞。
取樣器與排程器:
可選用多種取樣器:
Euler、Heun、DPM++2m、deis、DDIM 均表現良好。
我多用 "simple" 作為排程器。
如有更好設置,歡迎告訴我 :-)
Forge 推薦用一體化模型。這是 Forge 的設置範例:
版本 2.0_dev_experimental
這是實驗版本,目標是創建更連貫且更快速模型。我訓練了自有 lora,再利用特殊方式(Tensor merge)合併模型。搭配定制的 T5xxl,並用 "Attention Seeker" 修改。為提升速度和品質,合併了來自 ByteDance 的 Hyper Flux lora。這意味著工作區域有所偏移。主標題圖片如下。
16 步驟 V 2.0
 30 步驟 V 1.0
30 步驟 V 1.0
 缺點:
缺點:
首先此版比上一版稍大,需要創建只含 Unet 的版本,我完成後將會更新。
版本 2.0 設置與工作流程:
現可用較少步驟運行,16 步相當於舊版 30 步。
我仍建議多約 20-30 步,以獲更佳品質。
取樣器:偏好 Euler 搭配 simple 排程器。指導強度設於 1.5-3 皆可(當然也可自行測試範圍外)。1.8 對真實圖像效果良好。也可嘗試其他取樣器,如 DPM++2M、Heun 等均表現優秀。
工作流程 2.0:
為 V2.0 與 V1.0 制作了新的工作流程,帶有新的 Flux 提示詞生成器。另有第二放大階段。https://civitai.com/articles/7946
Forge:
我也在 Forge 上測試過此模型,效果良好……不過 Comfy UI 與 Forge 的圖像可能有所差異。
版本 1.0_dev_beta:
此為我該系列的第一版本,請多給反饋並上傳圖片,幫助我改進項目。有多個版本可選,質量最佳者為 FP16 版本,但其體積龐大,需強力顯卡與大量記憶體。FP8 版本品質與性能相對平衡。想要 GGUF 版本,請下載 Q8_0。GGUF Q4_0/4.1 是要求產生,體積小但會稍減品質。
基本分為兩種,我的 "一體化" 模型只需下載一個文件,內含 Clip_l、T5xxl fp8 與 VAE(下文示例)。請放入你的檢查點資料夾。
另一種是只含 UNET,需另行單獨加載所有檔案。
無論如何,你都需要下載我的 Clip_L 以正確使用這些版本。
同時必須選擇合適的 T5xxl clip。FP8 是 fp8_e4m3fn,FP16 是 FP16 clip,確保選擇預設權重類型。(下方有 fp8 版本示例圖)
GGUF 版本需使用 GGUF 加載器!
目前對 V1.0 已知事項:
此為首版,可能在某些提示詞或風格(如藝術)表現不佳。下個版本將進一步訓練。請告知模型無法處理的項目。
設置與工作流程:
我測試過約 30 步,Euler 搭配 simple 排程器。指導強度可設 1.5-3(當然也可測試範圍外)。
1.8 對真實圖像效果佳。
歡迎嘗試不同設置,若有好結果請分享。
展覽圖片作為訓練資料。內含 Comfy 工作流程。下載地址:https://civitai.com/articles/7946
一體化模型:
僅 UNET:
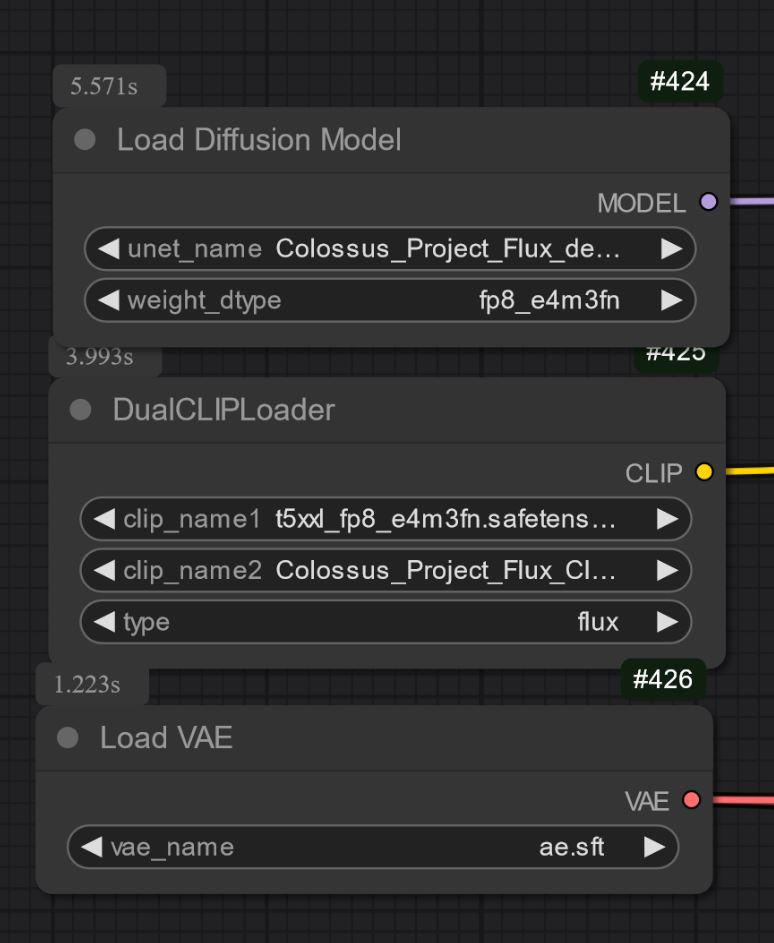 你還需下載
你還需下載 clip_L,約 240MB。
GGUF:我新增了 GGUF 工作流程:https://civitai.com/articles/7946
重要:
此開發版本非商用,商用版本將於其他地方發布 "schnell" 模型,主要供個人或科研用途。
許可證:
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
致謝:
感謝 theunlikely https://huggingface.co/theunlikel
版本 2.1/V4.2/5.0: Flux_dev_de-distill 來自 nyanko7
https://huggingface.co/nyanko7/flux-dev-de-distill
從 V2.0 開始:ByteDance 的 Hyper Lora https://huggingface.co/ByteDance/Hyper-SD
感謝 Black Forrest 的精彩 Flux 模型 https://huggingface.co/black-forest-labs

模型詳情
討論
請log in以發表評論。
模型合集 - Colossus Project Flux

Colossus Project Flux - v12_int4_SVDQ_nunchaku

Colossus Project Flux - V12 "Hephaistos" FP8_UNET

Colossus Project Flux - v10_AIO_FP8

Colossus Project Flux - v10_int4_SVDQ
















































