SD XL - v1.0
精選圖片












推薦參數
resolution
提示
此模型用於包括藝術作品生成、教育工具及安全部署在內的研究用途。
不適用於生成真實或準確的人物或事件描繪。
限制包括攝影真實感不完美、無法渲染可讀文字、組合提示挑戰及人物生成可能不當。
模型使用兩個預訓練文本編碼器:OpenCLIP-ViT/G 與 CLIP-ViT/L。
兩步驟流程包含基本潛在向量生成,接著使用 SDEdit(img2img)進行高解析度精煉。
創作者贊助
原始發布於 Hugging Face,並經 Stability AI 許可於此分享。
原始發布於 Hugging Face,並經 Stability AI 許可於此分享。
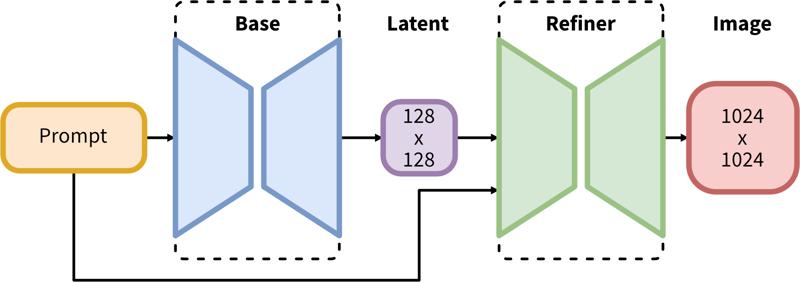
SDXL 包含兩步驟的潛在擴散流程:首先,我們使用基本模型生成所需輸出尺寸的潛在向量。第二步,我們使用專門的高解析度模型並在第一步生成的潛在向量上應用名為 SDEdit (https://arxiv.org/abs/2108.01073,也稱為「img2img」) 的技術,使用相同的提示語。
模型說明
開發者:Stability AI
模型類型:基於擴散的文本生成圖像模型
模型描述:此模型可根據文字提示生成及修改圖像。它是一個潛在擴散模型,使用兩個固定預訓練的文本編碼器(OpenCLIP-ViT/G和CLIP-ViT/L)。
更多資訊資源: GitHub 倉庫。
模型來源
用途
直接使用
本模型僅用於研究目的。可能的研究領域和任務包括
藝術品生成及在設計和其他藝術流程中的應用。
教育或創作工具中的應用。
生成模型的研究。
安全部署有可能生成有害內容的模型。
探查和理解生成模型的限制和偏見。
以下描述不適用的使用方式。
超出範疇的使用
此模型未經訓練用於真實、準確地描繪人物或事件,因此用於生成此類內容超出本模型能力範圍。
限制與偏見
限制
模型未達到完美的真實攝影效果
模型無法渲染可辨認的文字
模型在組合性較高的任務上表現較差,例如呈現「紅色立方體置於藍色球體上」的圖像
人臉和人物通常無法妥善生成。
模型的自動編碼部分存在資訊損失。
偏見
儘管圖像生成模型的能力令人印象深刻,但亦可能強化或加劇社會偏見。
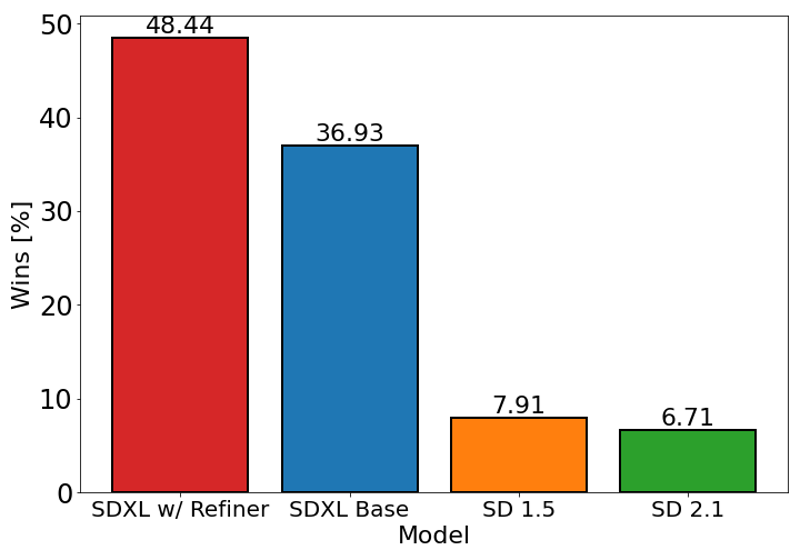
上圖評估使用者對 SDXL(含與不含精煉)相較於 Stable Diffusion 1.5 及 2.1 的偏好。SDXL 基礎模型表現顯著優於先前版本,且搭配精煉模組達成最佳整體效果。


SD XL - v1.0 的圖片
基礎模型 圖片

sdxl 圖片



stability ai 圖片



