Anime Illust Diffusion XL - v0.61
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder


Empfohlene Prompts
Trigger word (by xxx),a girl named frieren from sousou no frieren series,best quality,beautiful color,detailed,aesthetic,impasto style,cowboy shot,fantasy theme,gradient background,sitting on ground,expressionless,white hair,twintails,green eyes,parted lip,white dress,frills,a cat,grass,sunshine
best quality, 1girl, solo, looking at viewer, bangs
Empfohlene Negative Prompts
(worst quality:1.3),low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxlv05_neg
Empfohlene Parameter
samplers
steps
cfg
resolution
vae
Empfohlene Hires (Hochauflösungs-) Parameter
denoising strength
Tipps
Reduzieren Sie das Gewicht für Künstlerstil-Auslösewörter, z.B. (by xxx:0.6).
Die Sortierung der Prompt-Tags hilft dem Modell, die Bedeutung besser zu verstehen; empfohlene Tag-Reihenfolge liegt bei.
Verwenden Sie 'verfeinern' (Bild-zu-Bild oder Ausbesserung), wenn Text-zu-Bild-Ergebnisse unscharf sind.
Für Stilverschmelzung kontrollieren Sie Gewicht und Reihenfolge der Stile und hängen Stilwörter an, anstatt sie voranzustellen.
Charakter-Auslösewörter beinhalten meist keine Kleidung; fügen Sie Kleidungstags separat hinzu.
Verwenden Sie für Versionen 0.61 und darunter modell-spezifische negative Text-Embeddings für beste Ergebnisse.
Stellen Sie sicher, dass die Gesamtpixelzahl ca. 1024x1024 beträgt und die Bilddimensionen vielfach von 32 sind, für optimale Ergebnisse.
Versions-Highlights
Stärkere Stilierung.
Zusätzlich habe ich während des Trainings ein zusätzliches Rauschen hinzugefügt. Einige Sampler erreichen beim letzten Schritt keinen Nullzeitpunkt, was möglicherweise zu einem verrauschten Bild führt. Daher kann Euler A oder Euler Sampler für Sie besser geeignet sein.
风格化更明显。
另外,我在训练中使用了附加噪声。部分采样器的最终时间步不会归零,因此可能导致生成的图像带有噪声。因此,Euler A 或 Euler 采样器可能更适合您使用。
Ersteller-Sponsoren
Wenn Ihnen unsere Arbeit gefällt, unterstützen Sie uns gerne über Ko-fi: https://ko-fi.com/eugeai
Dank an die @NieTa Community (nieta.art) für die Bereitstellung von Rechenleistung sowie Dank an @KirinTea_Aki (Civitai Profil) und @Chenkin (Civitai Profil) für Datenunterstützung.
Modelleinführung (englischer Teil)
Inhalt I
In dieser Einführung erfahren Sie über:
Modelinformationen (siehe Abschnitt II);
Gebrauchsanweisungen (siehe Abschnitt III);
Trainingsparameter (siehe Abschnitt IV);
Liste der Auslösewörter (siehe Anhang Teil A)
II AIDXL
Anime Illustration Diffusion XL, oder AIDXL, ist ein Modell, das speziell für die Generierung stilisierter Anime-Illustrationen entwickelt wurde. Es verfügt über mehr als 800 (mit fortlaufenden Updates) integrierte Illustrationsstile, die durch spezifische Triggerwörter ausgelöst werden (siehe Anhang A).
Vorteile:
Flexible Komposition statt herkömmlicher AI-Posings.
Feine Details statt chaotischem Durcheinander.
Bessere Kenntnis von Anime-Charakteren.
III Benutzerhandbuch
1 Grundlegende Nutzung
1.1 Prompt
Auslösewörter: Fügen Sie die in Anhang A bereitgestellten Auslösewörter hinzu, um das Bild zu stilisieren. Geeignete Auslösewörter verbessern die Qualität deutlich;
Es wird empfohlen, das Gewicht für Künstlerstil-Auslösewörter zu reduzieren, z.B. (by xxx:0.6).
Semantische Sortierung: Die Sortierung Ihrer Prompt-Tags oder Sätze hilft dem Modell, die Bedeutung besser zu verstehen.
Empfohlene Tag-Reihenfolge: Auslösewort (by xxx) -> Charakter (ein Mädchen namens frieren aus der sousou no frieren Serie) -> Rasse (Elf) -> Komposition (Cowboy-Aufnahme) -> Stil (Impasto Stil) -> Thema (Fantasy-Thema) -> Hauptumgebung (im Wald, am Tag) -> Hintergrund (Farbverlauf-Hintergrund) -> Aktion (auf dem Boden sitzen) -> Ausdruck (ausdruckslos) -> Hauptmerkmale (weißes Haar) -> Körpermerkmale (Doppelzöpfe, grüne Augen, gespaltene Lippen) -> Kleidung (trägt ein weißes Kleid) -> Kleidung Zubehör (Rüschen) -> weitere Gegenstände (eine Katze) -> Sekundäre Umgebung (Gras, Sonnenschein) -> Ästhetik (schöne Farbe, detailliert, ästhetisch) -> Qualität ((beste Qualität:1.3))
Negative Prompts: (schlechteste Qualität:1.3), niedrige Qualität, niedrige Auflösung, unordentlich, abstrakt, hässlich, deformiert, schlechte Anatomie, Entwurf, deformierte Hände, verschmolzene Finger, Signatur, Text, Mehrfachansichten
1.2 Erzeugungsparameter
Auflösung: Stellen Sie sicher, dass die Gesamtpixelzahl (=Breite * Höhe) etwa 1024*1024 beträgt und die Breite und Höhe durch 32 teilbar sind. Unter diesen Bedingungen liefert AIDXL das beste Ergebnis. Beispiele: 832x1216 (2:3), 1216x832 (3:2) und 1024x1024 (1:1), usw.
Sampler und Schritte: Verwenden Sie den "Euler Ancester" Sampler, im WebUI als Euler A bezeichnet. Sampling mit ca. ~28 Schritten bei einem CFG-Wert von 7 bis 9.
'Verfeinern': Das aus Text-zu-Bild generierte Bild ist manchmal unscharf, daher ist es notwendig, es mittels Bild-zu-Bild oder Ausbesserung nachzubearbeiten.
Für einfaches Hochskalieren siehe: Upscale to huge sizes and add detail with SD Upscale, it's easy! : r/StableDiffusion (reddit.com)
Weitere Komponenten: Kein zusätzliches Verfeinerungsmodell nötig. Nutzen Sie das VAE des Modells selbst oder das
sdxl-vae.
F: Wie kann man das Modellcover reproduzieren? Warum erhalte ich nicht dasselbe Bild mit den gleichen Generationseinstellungen?
A: Die auf dem Cover gezeigten Parameter sind NICHT die Text-zu-Bild Parameter, sondern die Bild-zu-Bild (für Hochskalierung) Parameter. Das Basisbild wird meist mit dem Euler Ancester Sampler erzeugt und nicht mit dem DPM Sampler.
2 Spezielle Verwendung
2.1 Generalisierte Stile
Ab Version 0.7 fasst AIDXL mehrere ähnliche Stile zusammen und führt generalisierte Stil-Auslösewörter ein. Diese repräsentieren jeweils eine allgemeine Kategorie von Anime-Illustrationsstilen. Bitte beachten Sie, dass diese Auslösewörter nicht zwingend die künstlerische Bedeutung ihrer Wortbedeutung tragen, sondern speziell neu definiert sind.
2.2 Charaktere
Ab Version 0.7 wurde das Training an Charakteren verstärkt. Einige Charakter-Auslösewörter erzielen bereits Lora-ähnliche Effekte und können Konzept und Kleidung des Charakters gut trennen.
Die Trigger-Methode lautet: {charakter} \({copyright}\). Zum Beispiel löst man die Heldin Lucy aus der Serie "Cyberpunk: Edgerunners" mit lucy \(cyberpunk\) aus; für den Charakter Gan Yu im Spiel "Genshin Impact" benutzt man ganyu \(genshin impact\). "lucy" und "ganyu" sind Charakternamen, "\(cyberpunk\)" und "\(genshin impact\)" die Herkunftsserien, die Klammern sind mit "\" maskiert, damit sie nicht als gewichtete Tags interpretiert werden. Für manche Charaktere ist die Angabe der Herkunft optional.
Ab Version v0.8 gibt es eine einfachere Trigger-Methode: ein {Mädchen/Junge} namens {Charakter} aus der {Copyright}-Serie.
Für eine Liste der Charakter-Auslösewörter siehe: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). Manche weitere Auslösewörter, die in diesem Dokument nicht erwähnt sind, können ebenfalls enthalten sein.
Einige Charaktere benötigen zusätzliche Trigger-Schritte. Wenn der Charakter mit nur einem Triggerwort nicht vollständig wiederhergestellt werden kann, müssen Hauptmerkmale des Charakters in den Prompt eingefügt werden.
AIDXL unterstützt Charakter-Outfits. Charakter-Auslösewörter umfassen meist nicht die Kleidung des Charakters. Möchte man Charakterkleidung hinzufügen, müssen Kleidungs-Tags separat in den Prompt eingefügt werden. Beispiel: silbernes Abendkleid, tief ausgeschnittener Ausschnitt für das Outfit der Spielfigur St. Louis (Luxurious Wheels) aus dem Spiel Azur Lane. Ebenso können Kleidungs-Tags beliebiger Charaktere anderen Charakteren hinzugefügt werden.
2.3 Qualitätstags
Qualitäts- und Ästhetik-Tags sind offiziell trainiert. Das Anhängen im Prompt beeinflusst die Qualität des generierten Bildes.
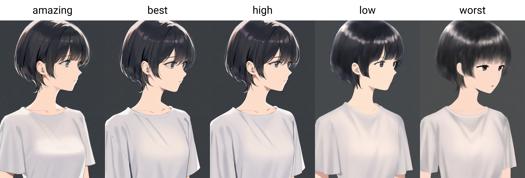
Ab Version 0.7 sind Qualitätstags in sechs Stufen unterteilt, von bester bis schlechtester Qualität: amazing quality, best quality, high quality, normal quality, low quality und worst quality.
Es wird empfohlen, Qualitäts-Tags mit zusätzlichem Gewicht zu verwenden, z.B. (amazing quality:1.5).
2.4 Ästhetik-Tags
Seit Version 0.7 wurden Ästhetik-Tags eingeführt, die besondere ästhetische Eigenschaften von Bildern beschreiben.
2.5 Stilverschmelzung
Sie können mehrere Stile zu einem benutzerdefinierten Stil kombinieren. 'Verschmelzen' bedeutet, mehrere Stil-Auslösewörter gleichzeitig zu verwenden. Beispiel: chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Tipps:
Kontrollieren Sie Gewicht und Reihenfolge der Stile zur Anpassung des Stils.
Fügen Sie Stile ans Ende Ihres Prompts an, nicht an den Anfang.
IV Trainingsstrategie & Parameter
AIDXLv0.1
Basierend auf SDXL1.0 wurde mit ca. 22k gelabelten Bildern etwa 100 Epochen Training mit Kosinus-Scheduler und Lernrate 5e-6 sowie einem Zyklus = 1 durchgeführt, um Modell A zu erhalten. Im Anschluss wurde mit Lernrate 2e-7 und gleichen Parametern Modell B trainiert. Das Modell AIDXLv0.1 wurde durch Verschmelzung von Modell A und B erhalten.
AIDXLv0.51
Trainingsstrategie
Fortführung des Trainings ab AIDXLv0.5 in drei aufeinanderfolgenden Phasen:
Training mit langen Captions: Nutzung des gesamten Datensatzes, teilweise manuell annotierte Bilder. Training von U-Net und Text-Encoder mit AdamW8bit Optimierer, hoher Lernrate (~1.5e-6) und Kosinus-Scheduler. Training wird gestoppt, wenn Lernrate unter eine Schwelle (~5e-7) fällt.
Training mit kurzen Captions: Fortsetzung des Trainings aus Phase 1 mit den gleichen Parametern, aber einem kürzeren Caption-Datensatz.
Verfeinerungsschritt: Vorbereitung eines Subsets aus Phase 1 mit manuell ausgewählten hochwertigen Bildern. Fortsetzung des Trainings aus Phase 2 mit niedriger Lernrate (~7.5e-7) und Kosinus-Scheduler mit 5 bis 10 Neustarts. Training bis ästhetisch gutes Ergebnis erreicht ist.
Fixe Trainingsparameter
Keine zusätzlichen Geräusche wie Noise Offset.
Min snr gamma = 5: beschleunigt Training.
Volle bf16 Präzision.
AdamW8bit Optimierer: gutes Verhältnis zwischen Effizienz und Leistung.
Datensatz
Auflösung: 1024x1024 Gesamtauflösung (= Höhe × Breite) mit modifizierter offizieller SDXL-Bucket-Strategie.
Beschriftung: Beschriftet mit WD14-Swinv2 Modell bei 0.35 Schwellenwert.
Close-up Cropping: Bilder werden in Ausschnitte unterteilt, nützlich bei großen oder seltenen Trainingsbildern.
Auslösewörter: Das erste Tag der Bilder wird als Auslösewort verwendet.
AIDXLv0.6
Trainingsstrategie
Fortführung des Trainings von AIDXLv0.52 mit adaptiver Wiederholungsstrategie – Für jedes annotate Bild wird die Anzahl der Wiederholungen im Training entsprechend folgender Regeln erhöht:
Regel 1: Je höher die Qualität des Bildes, desto mehr Wiederholungen;
Regel 2: Gehört das Bild zu einer Stilklasse:
Ist die Klasse noch nicht ausreichend trainiert (underfitted), wird die Wiederholungsanzahl manuell oder automatisch erhöht, bis ca. 100 Wiederholungen erreicht sind.
Ist die Klasse bereits ausreichend trainiert (overfitted), wird die Wiederholungsanzahl manuell auf 1 gesetzt und bei niedriger Qualität reduziert.
Regel 3: Die maximale Anzahl der Wiederholungen ist auf ungefähr 10 begrenzt.
Diese Strategie bietet folgende Vorteile:
Schützt das ursprüngliche Modellwissen vor Überschreiben durch neues Training;
Ermöglicht kontrollierbaren Einfluss der Trainingsdaten;
Balanciert Training zwischen verschiedenen Klassen, fördert unterrepräsentierte Klassen und verhindert Overfitting bei überrepräsentierten;
Spart erheblich Rechenressourcen und erleichtert Hinzufügen neuer Stile.
Fixe Trainingsparameter
Wie bei AIDXLv0.51.
Datensatz
Datensatz basiert auf AIDXLv0.51, zusätzlich angewandte Optimierungen:
Semantische Sortierung der Captions: Sortierung der Tags z.B. von "gun, 1boy, holding, short hair" zu "1boy, short hair, holding, gun".
Duplikat-Entfernung bei Captions: Entfernen doppelter Tags mit ähnlicher Bedeutung, z.B. "long hair" und "very long hair", wobei der informativste Tag behalten wird.
Zusätzliche Tags: Manuelle Ergänzung von Tags wie "high quality", "impasto" für alle Bilder, einfach mit Tools durchzuführen.
V Besonderer Dank
Rechenleistungssponsoring: Dank an die @NieTa Community (捏Ta (nieta.art)) für die Bereitstellung von Rechenleistung;
Datenunterstützung: Dank an @KirinTea_Aki (KirinTea_Aki Creator Profile | Civitai) und @Chenkin (Civitai | Teile deine Modelle) für umfangreiche Datenunterstützung;
Ohne sie gäbe es keine Version 0.7.
VI AIDXL vs AID
2023/08/08. AIDXL wurde auf dem gleichen Trainingsdatensatz wie AIDv2.10 trainiert, übertrifft aber AIDv2.10. AIDXL ist intelligenter und kann vieles, was SD1.5-basierte Modelle nicht können. Es unterscheidet Konzepte klarer, lernt Bilddetails besser und bewältigt Kompositionen, die für SD1.5 und AID schwierig oder unmöglich sind. Insgesamt ist es sehr vielversprechend. Ich werde AIDXL weiterhin aktualisieren.
VII Sponsoring
Wenn Ihnen unsere Arbeit gefällt, können Sie uns über Ko-fi (https://ko-fi.com/eugeai) unterstützen, um unsere Forschung und Entwicklung zu fördern. Vielen Dank für Ihre Unterstützung~
Modellbeschreibung (chinesischer Teil)
I Inhaltsverzeichnis
In dieser Beschreibung erfahren Sie:
Modellbeschreibung (siehe Abschnitt II);
Anleitung zur Nutzung (siehe Abschnitt III);
Trainingsparameter (siehe Abschnitt IV);
Liste der Auslösewörter (siehe Anhang A)
II Modellbeschreibung
Anime Illust Diffusion XL, auch bekannt als AIDXL, ist ein auf die Erzeugung von Anime-Illustrationen spezialisiertes Modell. Es enthält mehr als 800 voreingestellte Illustrationsstile (mit kontinuierlichen Updates), die durch spezifische Auslösewörter aktiviert werden (siehe Anhang A).
Vorteile: Mutige Komposition, kein künstliches Posing, klarer Fokus auf das Hauptmotiv, keine überflüssigen Details, gute Kenntnis zahlreicher Anime-Charaktere (aktiviert über den japanischen Namen der Charaktere in Romaji, z.B. „ayanami rei“ für die Figur „Rei Ayanami“, „kamado nezuko“ für „Nezuko Kamado“).
III Benutzerhandbuch (wird laufend aktualisiert)
1 Grundlegende Verwendung
1.1 Prompt-Schreibung
Benutzung von Auslösewörtern: Verwenden Sie die in Anhang A aufgeführten Auslösewörter zur Stilierung des Bildes. Passende Auslösewörter verbessern die Bildqualität deutlich;
Prompt-Tagging: Beschreiben Sie das gewünschte Ergebnis mit getaggten Stichwörtern;
Prompt-Sortierung: Die Sortierung der Stichwörter hilft dem Modell, die Bedeutung besser zu verstehen. Empfohlene Reihenfolge:
Auslösewort (by xxx) -> Hauptfigur (1girl) -> Charakter (frieren) -> Rasse (elf) -> Komposition (cowboy shot) -> Stil (impasto) -> Thema (fantasy) -> Hauptumgebung (forest, day) -> Hintergrund (gradient background) -> Aktion (sitting) -> Ausdruck (expressionless) -> Hauptmerkmale des Charakters (white hair) -> Körpermerkmale (twintails, green eyes, parted lip) -> Kleidung (white dress) -> Kleidung Zubehör (frills) -> andere Gegenstände (magischer Zauberstab) -> sekundäre Umgebung (gras, sonnenschein) -> Ästhetik (beautiful color, detailed, aesthetic) -> Qualität (best quality)
Negative Prompts: worst quality, low quality, lowres, messy, abstract, ugly, disfigured, bad anatomy, deformed hands, fused fingers, signature, text, multi views
1.2 Erzeugungsparameter
Auflösung: Stellen Sie sicher, dass die Gesamtauflösung (Höhe x Breite) ca. 1024*1024 beträgt und Breite und Höhe Vielfache von 32 sind. Beispiel: 832x1216 (3:2), 1216x832 (3:2), 1024x1024 (1:1).
Kein „Clip Skip“-Verfahren; Clip Skip = 1.
Sampler und Schritte: Verwenden Sie den Sampler „euler_ancester“ (im WebUI als Euler A bezeichnet), mit 28 Schritten bei CFG Scale 7.
Es wird kein Verfeinerungsmodell benötigt (Refiner).
Nutzen Sie das Basismodell-VAE oder sdxl-vae.
2 Spezielle Verwendung
2.1 Verallgemeinerte Stile
Version 0.7 fasst mehrere ähnliche Illustrationsstile zusammen und führt verallgemeinerte Stil-Auslösewörter ein, die bestimmten gängigen Anime-Illustrations-Stilkategorien entsprechen.
Beachten Sie, dass diese Auslösewörter nicht unbedingt der künstlerischen Bedeutung ihrer Wortbedeutung entsprechen, sondern neu definierte spezielle Trigger sind.
2.2 Charaktere
Version 0.7 verstärkt die Charakter-Trainings. Einige Charakter-Auslösewörter erreichen bereits Lora-ähnliche Effekte und trennen gut Charakterkonzept von Kleidung.
Auslöseformat: Charaktername \(Werk\). Beispiel für die Animationsserie "Cyberpunk: Edgerunners" die Heldin Lucy: lucy \(cyberpunk\). Für das Spiel "Genshin Impact" den Charakter Gan Yu: ganyu \(genshin impact\). Dabei sind die Klammern mit "\" maskiert, um Fehlinterpretationen zu vermeiden.
Eine Liste der Charakter-Auslösewörter findet sich unter selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co).
Falls ein Charakter nicht vollständig mit nur einem Triggerwort generiert wird, ergänzen Sie die Hauptmerkmale im Prompt.
Charakter-Auslösewörter enthalten gewöhnlich keine Kleidung. Möchten Sie Kleidung hinzufügen, fügen Sie Kleidungstags im Prompt hinzu, z.B. silbernes Abendkleid, tiefer Ausschnitt für die Spielfigur St. Louis (Luxurious Wheels) aus Azur Lane. Das ist auch mit Kleidungs-Tags anderer Charaktere möglich.
2.3 Qualitäts-Tags
Qualitäts- und Ästhetik-Tags sind ab Version 0.7 offiziell trainiert und beeinflussen beim Verwenden die Qualität des generierten Bildes.
Qualitäts-Tags gliedern sich in sechs Stufen von höchster bis geringster Qualität: amazing quality, best quality, high quality, normal quality, low quality und worst quality.
Empfohlen wird die Verwendung mit erhöhtem Gewicht, z.B. (amazing quality:1.5).
2.4 Ästhetik-Tags
Seit Version 0.7 beschreiben Ästhetik-Tags besondere ästhetische Bildmerkmale.
2.5 Stilfusion
Stile können kombiniert werden, indem mehrere Stil-Auslösewörter gleichzeitig verwendet werden. Beispiel: chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Tipps:
Gewicht und Reihenfolge der Stile kontrollieren zur Feinabstimmung.
Stilwörter an das Ende des Prompts anhängen, nicht davor.
3 Wichtige Hinweise
Verwenden Sie für SDXL unterstützte VAE-Modelle, Text-Embeddings und Lora-Modelle. Hinweis: sd-vae-ft-mse-original ist kein kompatibles SDXL-VAE; EasyNegative, badhandv4 und ähnliche negative Text-Embeddings sind ebenfalls nicht für SDXL geeignet;
Für Version 0.61 und frühere Versionen wird dringend die Nutzung modell-spezifischer negativer Text-Embeddings empfohlen (Download im Abschnitt Suggested Resources), da diese speziell für das Modell optimiert sind und fast ausschließlich positive Effekte haben;
Neue Auslösewörter für jede Version sind anfangs möglicherweise weniger wirksam oder instabil.
IV Trainingsparameter
Basierend auf SDXL1.0 wurden ca. 20.000 selbst annotierte Bilder verwendet und unter Lernrate 5e-6 sowie Zyklus=1 mit Kosinus-Scheduler ca. 100 Epochen trainiert, um Modell A zu erhalten. Anschließend wurde Modell B bei Lernrate 2e-7 und sonst gleichen Parametern trainiert. Nach Verschmelzen von Modell A und B entstand das AIDXLv0.1 Modell.
Weitere Trainingsparameter entnehmen Sie bitte der englischen Version.
V Besonderer Dank
Rechenleistungssponsoring: Danke an die @捏Ta Community (捏Ta (nieta.art)) für die Bereitstellung der Rechenleistung;
Datenunterstützung: Danke an @秋麒麟热茶 (KirinTea_Aki Creator Profile | Civitai) und @风吟 (Chenkin Creator Profile | Civitai) für umfangreiche Datenunterstützung;
Ohne sie gäbe es keine Version 0.7.
VI Änderungsprotokoll
2023/08/08: AIDXL wurde auf demselben Trainingsdatensatz wie AIDv2.10 trainiert, übertrifft jedoch AIDv2.10. AIDXL ist intelligenter, kann vieles, was mit SD1.5 nicht möglich ist, lernt Bilddetails besser, verarbeitet schwierige Kompositionen und Perfektioniert Stile, die ältere AID-Versionen nicht erreichen konnten. Es besitzt insgesamt ein höheres Potenzial. Updates werden fortgesetzt.
2024/01/27: Version 0.7 enthält umfangreiche Neuerungen mit mehr als doppelt so großem Datensatz im Vergleich zur Vorversion.
Für zufriedenstellende Annotationen wurden neue Label-Verarbeitungsalgorithmen angewandt, z.B. Tag-Sortierung, tag-Hierarchisierung, Trennung von Charaktermerkmalen usw. Projekt: Eugeoter/sd-dataset-manager (github.com);
Für besser steuerbares Training wurde ein spezielles Trainingsskript auf Kohya-ss Basis erstellt;
Für die Verschmelzung verschiedener Modelle wurden heuristische Algorithmen entwickelt; zur Sicherung von Stilcharakter wurde auf eine Fusion von Textencoder und UNET-OUT-Schichten verzichtet, da diese die Stabilität und Ästhetik schwächen könnte.
Zur Datenfilterung wurden Modelle zur Wasserzeichen-Erkennung, Bildklassifizierung und Ästhetikbewertung trainiert.
VII Unterstützen Sie uns
Wenn Ihnen unsere Arbeit gefällt, können Sie uns über Ko-fi (https://ko-fi.com/eugeai) unterstützen, um unsere Forschung und Entwicklung zu fördern. Vielen Dank für Ihre Unterstützung!
Anhang / Appendix
A. Liste spezieller Auslösewörter / 特殊触发词列表
Künstlerstil-Auslösewörter: Hier klicken
Malstil-Auslösewörter: flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: Flächige Farben, Licht und Schatten mit Linien dargestellt
平涂:Flächige Farbflächen mit Linien zur Darstellung von Licht und Schatten
clean color: Stil zwischen flat color und flat-pasto. Einfache, klare Färbung.
Saubere Farben: Stil zwischen flat color und flat-pasto, klar und ordentlich
celluloid: Anime-Färbung
Zelluloidfarbe: Anime Coloring
flat-pasto: Fast flächige Farbe, Verwendung von Farbverläufen zur Darstellung von Licht und Schatten
Fast flächige Farbflächen mit Farbverlauf, zur Darstellung von Licht und Schatten
thin-pasto: Dünne Konturlinien, Einsatz von Farbverläufen und Farbauftrag zur Darstellung von Licht, Schatten und Textur
Dünne Konturoberflächen mit Farbverläufen und Farbeinsatz zur Darstellung von Licht und Schatten
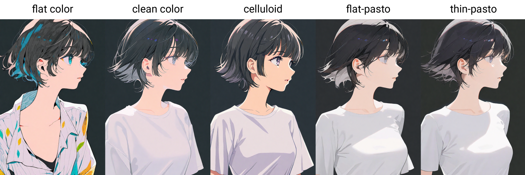
pseudo-impasto: Verwendung von Farbverläufen und Farbauftrag zur Beschreibung von Licht, Schatten und Textur
Pseudo-Impasto / Halb-Impasto: Verwendung von Farbverläufen und Farbeinsatz zur Darstellung von Licht und Schatten
impasto: Einsatz von Farbauftrag zur Beschreibung von Licht, Schatten und Farbverläufen
Impasto: Verwendung von Farbeinsatz zur Darstellung von Licht, Schatten, Farbverläufen
realistic
realistisch
photorealistic: Neu definiert als ein Stil, der der realen Welt näherkommt
Foto-realistisch: Neu definiert als Stil, der die reale Welt nachahmt
cel shading: Anime 3D-Modellierungsstil
Cel-Schattierung: Anime-3D-Modellierungsstil
3d

Ästhetik-Auslösewörter:
beautiful
schön
aesthetic: leicht abstrakter künstlerischer Eindruck
ästhetisch: leicht abstrakter künstlerischer Eindruck
detailed
detailliert
beautiful color: subtiler Farbeinsatz
schöne Farbe: dezente und harmonische Farbgebung
lowres
messy: unordentliche Komposition oder Details
unordentlich: chaotische Komposition oder Details
Qualitäts-Auslösewörter: amazing quality, best quality, high quality, low quality, worst quality




Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Trainierte Wörter
Ersteller
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.
Modellsammlung - Anime Illust Diffusion XL


Bilder von Anime Illust Diffusion XL - v0.61
Bilder mit Anime










Bilder mit Basismodell

Bilder mit Einfarbig










Bilder mit Illustration








