AlbedoBase XL - v1.3
Palabras Clave y Etiquetas Relacionadas
Imágenes destacadas





Prompts Negativos Recomendados
strabismus
Parámetros Recomendados
samplers
steps
cfg
resolution
vae
Consejos
Si la generación de imágenes no produce resultado, intenta cambiar a CLIP SKIP 2 o modifica la indicación ligeramente cambiando el orden o las palabras.
Usar indicaciones en forma de oraciones tiende a mejorar la calidad de la imagen más que las listas de etiquetas.
Dejar el campo de indicación negativa vacío a menudo produce mejores resultados en la imagen.
Revisa la cuadrícula de especificaciones para obtener los ajustes óptimos antes de usarlo.
Experimenta con algunas indicaciones negativas específicas como 'estrabismo' para abordar problemas como ojos asimétricos o pixelación.
Aspectos Destacados de la Versión
v1.3
Para ilustrar la calidad asociada a la aleatoriedad del modelo, estandaricé el valor de la semilla en '9' para todas las imágenes de muestra destinadas a muestreo y procedí con su generación inmediata.
Especialmente con esta versión, debido al significativo impacto de las indicaciones negativas, dejar el campo de indicación negativa vacío probablemente produzca la mejor calidad.
La cuadrícula de especificaciones(438.7 MB): descargar
Como puedes ver, al aumentar el número de Steps, se vuelve disponible para todos los samplers, y la calidad también mejora.
Debido al efecto de la LoRA que desarrollé y fusioné, como se describe abajo, usar indicaciones en forma de oraciones en lugar de etiquetas (una lista de palabras) está directamente relacionado con la mejora de calidad.
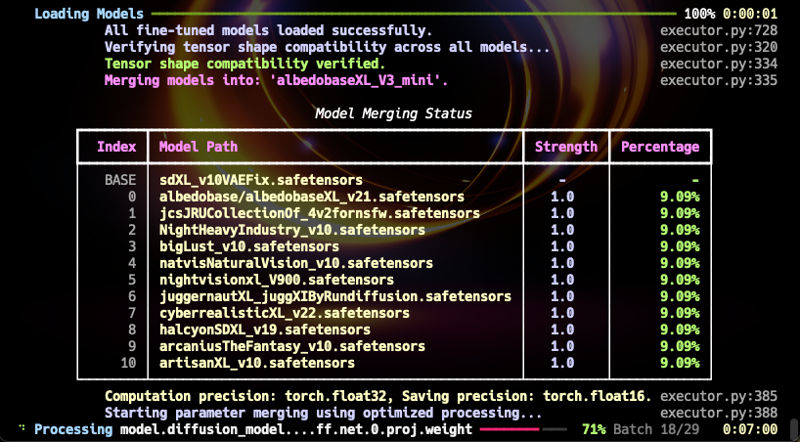
Fusioné 45 checkpoints y 7 LoRAs. Después de eso, fusioné AlbedoBase v0.4 y v0.3 en orden, menos del 0~5%, para reactivar los modelos fusionados diluidos que se habían vuelto obsoletos.
Entre los 7 LoRAs, uno fue creado por mí. Involucra analizar y anotar leyendas para un total de 174 fotos pictóricas de alta calidad usando GPT4-V. Fusionar esta LoRA resultó en imágenes increíblemente claras y una comprensión impresionante de las indicaciones.
Mis LoRAs creadas por mí están exclusivamente disponibles para compra para mis seguidores en Ko-fi con nivel Creative o superior. Planeo lanzar más y más actualizaciones en el futuro. Los precios varían de $10 a $50.
Patrocinadores del Creador
Si has encontrado valor en el modelo, por favor considera ofrecer tu apoyo. Tu contribución se dedicará completamente a avanzar la comunidad SDXL.
Si has encontrado valor en el modelo, por favor considera ofrecer tu apoyo. Tu contribución se dedicará completamente a avanzar la comunidad SDXL.
🙋🏼♂️ únete a nosotros (discord) ㅤ|ㅤ 🛒 comprarㅤ |ㅤ 🌱 donar
AlbedoBase XL (SFW&NSFW)
No es necesario el refinador, y VAE está incluido.
OBJETIVO
Stable Diffusion XL tiene 3.5 mil millones de parámetros (excluyendo el Refinador), lo que es aproximadamente 3.6 veces más que la versión SD v1.5. Creo que esto no es solo un número, sino un número que puede llevar a una mejora significativa en el rendimiento.
Ha pasado un tiempo desde que nos dimos cuenta de que el rendimiento general de SD v1.5 ha mejorado más allá de la imaginación gracias a las contribuciones explosivas de nuestra comunidad. Por lo tanto, estoy trabajando en completar este modelo AlbedoBase XL para reproducir óptimamente la mejora de rendimiento ocurrida en v1.5 también en esta versión XL.
Mi objetivo es probar directamente el rendimiento de todos los Checkpoints y LoRAs que se suben públicamente a Civitai, y fusionar solo los recursos que sean juzgados óptimos después de pasar varios filtros. Esto superará el rendimiento de IA generadora de imágenes de compañías como Midjourney.
Hasta ahora, AlbedoBase XL v3.1 Large ha fusionado cerca de 200 checkpoints seleccionados y 251 LoRAs.
REGISTRO
v3.1-Large
• Fusionadas más de 50 versiones seleccionadas y recientes de modelos SDXL usando el script recursivo empleado en V3.
La cuadrícula de especificaciones(370.7 MB): descargar


v3-mini
Ofrezco una sincera disculpa por hacerles esperar tanto tiempo.
He estado lidiando con asuntos personales, y mientras trabajaba en la nueva versión, también enfrenté problemas de salud. Incluso al escribir esto, sigo enfrentando esos desafíos.
Sentí que no bastaba con solo ofrecer una actualización breve, así que pido su comprensión al compartir este mensaje más detallado.
Desde el lanzamiento de la versión 2.0, me he dedicado a estudiar aprendizaje profundo de forma independiente. No tengo un título formal, y aparte de una modesta aptitud para la programación, solo cuento con formación en artes. Por ello, carezco de la base matemática y científica para lograr grandes avances, dado el tiempo y esfuerzo invertidos. A pesar de ello, la experiencia de sumergirme en este estudio e investigación autodirigida ha sido un tesoro invaluable en mi vida.
Recientemente, tuve una idea que podría ser un gran avance. Tras rehacer cientos de fórmulas y métodos desde la versión 2.0, logré desarrollar un algoritmo bastante exitoso e intrigante. El proceso de fusión del modelo se basó en SDXL1.0 y SD1.5, junto con otros modelos cuidadosamente seleccionados. Estos se clasificaron en cinco categorías principales: “ANIME,” “REALISMO,” “ARTÍSTICO,” “NSFW,” y “BASE,” y se introdujeron en el algoritmo de fusión como conjuntos de datos. Este enfoque ha generado resultados fascinantes.
Sin embargo, tan desafiante como fue el desarrollo del algoritmo, nada ha sido tan arduo como la fase de pruebas de rendimiento. Mi salud física y mental se deterioró significativamente durante este periodo, al punto de darme cuenta de que no podía continuar este trabajo solo. Esto finalmente me llevó a decidir lanzar esta versión.
Y ahora, me complace anunciar el lanzamiento de la muy esperada versión AlbedoBaseXL V3 Mini. Aunque este modelo es una fusión a menor escala, no está limitado a ninguna área específica y funciona sobresalientemente en varios dominios. Tiene el potencial de servir como nuevo modelo base para SDXL1.0. (Como referencia, mi algoritmo de fusión no es una “fusión lineal,” por lo que esencialmente puede considerarse un modelo ajustado nuevo.)
Este modelo, junto con los modelos AlbedoBase existentes, es versátil y supera a todas las versiones previas en todos los aspectos. (El contenido NSFW, aunque no es extremo, ofrece un rango más amplio de expresión comparado con versiones anteriores como la v2.1. En el futuro se lanzará un modelo de fusión dedicado a NSFW.)
Por otro lado, he notado que muchos modelos compartidos han comenzado recientemente a adoptar licencias que prohíben la fusión o la comercialización externa. Esto ha sido decepcionante, ya que me ha impedido usar algunos modelos realmente excelentes para fusionar.
Quisiera expresar mi sincero agradecimiento a los desarrolladores de modelos que han brindado licencias gratuitas, permitiendo que sus modelos de alta calidad—producto de considerable tiempo y esfuerzo—se usen para fusión.
Volveré pronto.
Espero con ansias sus pruebas de rendimiento en una amplia gama de áreas, incluyendo ANIME, REALISMO, ARTÍSTICO, 2.5D, 3D y NSFW.
Como desarrolladores de modelos, solo plantamos las semillas. Ustedes, los usuarios y artistas de modelos, son quienes finalmente las cultivan y hacen florecer los frutos.
Gracias, como siempre.
Para quienes quieran apoyar mi trabajo con una pequeña contribución financiera, por favor consideren usar los enlaces abajo. Actualmente no puedo asegurar un empleo y enfrento un futuro incierto respecto a mi sustento.
La cuadrícula de especificaciones(380.5 MB): descargar


v2.1
Re-fusionar y ajustar v0.1 a 2.0 usando nuevo algoritmo y fórmula de fusión.
La cuadrícula de especificaciones(424.5 MB): descargar

v2.0
Quisiera agradecer a todos los que me ayudaron con la versión preliminar AlbedoBase XL. Sin ustedes, probablemente la fecha de lanzamiento habría sido mucho más tardía. ¡Muchas gracias!
He escrito un script personalizado para converger los modelos existentes AlbedoBase XL en uno solo, alineando meticulosamente los pesos de filas y columnas de todos los bloques U-NET y CLIP según una fórmula única mía.
Si encuentras un error en la generación de imágenes (si no se genera nada), ¡por favor cambia a CLIP SKIP 2 o modifica ligeramente la indicación! Puede haber combinaciones de indicaciones que CLIP no reconozca. En ese caso, puedes cambiar el orden de las palabras, usar otras palabras o, más simplemente, cambiar el CLIP SKIP. Gradualmente trabajaré para resolver estos problemas en el futuro, como en v1.3.
La cuadrícula de especificaciones(403.5 MB): descargar
v1.3
Para ilustrar la calidad asociada a la aleatoriedad del modelo, estandaricé el valor de la semilla en '9' para todas las imágenes de muestra destinadas a muestreo y procedí con su generación inmediata.
Especialmente con esta versión, debido al significativo impacto de las indicaciones negativas, dejar el campo de indicación negativa vacío probablemente produzca la mejor calidad.
La cuadrícula de especificaciones(438.7 MB): descargar

Como puedes ver, al aumentar el número de Steps, se vuelve disponible para todos los samplers, y la calidad también mejora.
Debido al efecto de la LoRA que desarrollé y fusioné, como se describe abajo, usar indicaciones en forma de oraciones en lugar de etiquetas (una lista de palabras) está directamente relacionado con la mejora de calidad.
Fusioné 45 checkpoints y 7 LoRAs. Después de eso, fusioné AlbedoBase v0.4 y v0.3 en orden, menos del 0~5%, para reactivar los modelos fusionados diluidos que se habían vuelto obsoletos.
Entre los 7 LoRAs, uno fue creado por mí. Involucra analizar y anotar leyendas para un total de 174 fotos pictóricas de alta calidad usando GPT4-V. Fusionar esta LoRA resultó en imágenes increíblemente claras y una comprensión impresionante de las indicaciones.
Mis LoRAs creadas por mí están exclusivamente disponibles para compra para mis seguidores en Ko-fi con nivel Creative o superior.
v1.2
Fusionados los 22 checkpoints más recientes.
La cuadrícula de especificaciones(565.6 MB): descargar
v1.1
Estabilizado.
Más detallado.
Si crees que eres un usuario avanzado, recomiendo la versión 1.0. Si la versión 1.0 encuentra los ajustes correctos, puede producir obras mucho más vívidas.
La cuadrícula de especificaciones(349.7 MB): descargar
v1.0
Fusioné 106 LoRAs.
Fusioné 19 Checkpoints.
El modelo puede producir resultados diferentes dependiendo de los ajustes que elijas, por lo que es importante revisar la cuadrícula de especificaciones antes de usarlo.
He encontrado que usar algunas indicaciones negativas específicas puede ayudar a resolver el problema de ojos asimétricos o imágenes pixeladas. La cuadrícula de especificaciones puede variar dependiendo de tu dispositivo CPU o GPU, así que úsala solo como referencia general. Experimenta con algunas indicaciones negativas para mejorar la calidad (ej; estrabismo). He notado que es difícil satisfacer todos los ajustes por igual conforme aumenta el número de LoRAs combinadas. Sin embargo, quiero que te enfoques en esta ventaja en la versión 1.0, ya que puede producir obras de calidad asombrosa en varios aspectos con los ajustes correctos. Volveré con una versión más estable en el futuro.
Puedes encontrar valores útiles de ajustes en la demostración o buscando los de otros.
Como siempre, es mejor dejar el campo de indicación negativa vacío para mejores resultados.
Este v1.0 requirió mucho trabajo, así que tomaré un descanso por un tiempo. Espero que disfrutes usar el modelo, y si haces una fusión, por favor compártela en Civitai de forma gratuita. Así todos podremos seguir mejorándolo.
La cuadrícula de especificaciones(479.4 MB): descargar
v0.4
Fusioné 132 LoRAs.
Fusioné 4 Checkpoints.
La cuadrícula de especificaciones: descargar
v0.3
Mejorado en todos los samplers.
Logró realismo vivido.
Estabilizado.
La cuadrícula de especificaciones: descargar
v0.2
Mejoras significativas en claridad y detalle.
Mejorada la implementación de manos y pies.
Mejoras estéticas mayores; composición, abstracción, flujo, luz y color, etc.
v0.1
Tras un ajuste fino apropiado del modelo SDXL1.0, fusioné meticulosamente y con propósito más de 40 modelos de alta calidad
disponibles públicamente en Civitai.
Las pruebas se han centrado principalmente en asegurar la máxima calidad con el mínimo número de tokens en la indicación, y no se ha confirmado cuánto puede mejorar la calidad usando un gran número de tokens. (Por favor realicen sus propias pruebas y compartan los resultados)
Normalmente, los resultados más bellos se logran en el punto medio entre realidad y animación.
No obstante, al usar una indicación adecuada, generalmente no hay nada que no pueda expresar. (Afirmo que posee un valor abundante como modelo base que supera a otros en fusión. Sin embargo, tengan en cuenta que esta es actualmente la v0.1)

Detalles del Modelo
Tipo de modelo
Modelo base
Versión del modelo
Hash del modelo
Palabras entrenadas
Creador
Discusión
Por favor log in para dejar un comentario.
Colección de Modelos - AlbedoBase XL




Imágenes por AlbedoBase XL - v1.3
Imágenes con 3d










Imágenes con todo en uno



Imágenes con anime










Imágenes con modelo base

Imágenes con fotorrealista









