kegant - v1.0 / PDXL
Mots-clés et tags associés
Images en vedette

Prompts recommandés
score_9, score_8_up, score_7_up, score_6_up, score_5_up, score_4_up, solo
Prompts négatifs recommandés
dark,night,blur,jpeg artifacts,plants,flowers,cyberpunk,1girl
3d
Paramètres recommandés
samplers
steps
cfg
resolution
Paramètres haute résolution recommandés
upscaler
upscale
steps
Conseils
Utilisez « dark » ou « night » dans les prompts négatifs pour éviter les images trop sombres.
Ajoutez « blur » dans le prompt négatif pour réduire les effets de profondeur de champ trop forts.
Les plans en corps entier sont difficiles ; spécifiez « shoes », « boots » ou « feet/toes » pour améliorer les résultats.
Utilisez des détailleurs de visage simples pour de meilleurs visages en plans éloignés ; ils fonctionnent plus vite que les upscalers latents.
Réduisez CFG et steps dans l'upscaler latent pour un rendu plus doux, style 'peint', effet de brouillard ; une CFG élevée donne un rendu plus brillant, 'cuit'.
Évitez de surcharger les prompts ; parfois moins c’est plus avec le tagging style danbooru.
Ajoutez « jpeg artifacts », « plants », « flowers » et « cyberpunk » aux prompts négatifs pour supprimer les artefacts indésirables.
Spécifier « 1girl » dans les prompts négatifs aide pour la génération de sujets masculins.
Points forts de la version
il s'agit d'une fusion simple. aucun entraînement n'a été impliqué avec cette version.
kegant
✨ workflow simple pour comfyui : ✨ https://civitai.com/models/861472?modelVersionId=963859
MISE À JOUR V4 : La V4 utilise majoritairement le dataset de la V3, bien que certaines images aient été retirées. Le principal changement est le passage de pony à noobai-vpred comme modèle de base. Par conséquent, suivez les conventions adaptées à la formation de noobai avec les tags danbooru appropriés. Pour de l'aide, consultez quelques-unes de mes images publiées pour les styles de tagging que je mets généralement au début de mes prompts. Cette version n'est pas parfaite et nécessitera probablement une révision car certains tags comme "flou" et "obscurité" posent encore problème (beaucoup d'images générées seront plutôt sombres). Utilisez des termes comme « dark » ou « night » dans le prompt négatif si les images restent trop sombres, ou « blur » si la profondeur de champ est trop marquée à votre goût, cela corrigera cela. Le passage de pony à NAIXL implique de grands changements, surtout sur des aspects que j'adore comme l'éclairage, le bokeh, le flou et autres effets d'appareil photo, qui sont la base de kegant depuis la v1. Aucune des images montrées n'a été retouchée ni photoshopée après comfy, ni i2i, mais j'utilise un détailleur de visage. Ce checkpoint est plus difficile pour les plans éloignés, comme le "full_body" ou "wide_angle". Utilisez un détailleur de visage simple, c'est facile à configurer, ils fonctionnent plus vite qu'un latent et améliorent considérablement les visages en plans éloignés. Je me base sur ce guide (qui marche très bien) :
https://www.youtube.com/watch?v=gDBeKIa4sHA
MISE À JOUR V3 : La V3 est principalement une mise à jour axée sur les monstres, avec quelques apparitions secondaires, mais surtout un contrôle plus précis des éléments artistiques. J’ai fait des choses obscènes avec cette version, comme retoucher manuellement de nombreuses images sources dans Gimp pour éliminer autant que possible les artefacts jpeg. Les filigranes sont inexistants et ne nécessitent pas de tagging négatif, les problèmes de plantes et de faune ont été corrigés, et les mâles sont désormais plus faciles à générer car j’en ai ajouté beaucoup. La liste complète des tags des images incluses dans cette mise à jour est disponible sous « à propos de la version ». Beaucoup d’images en v3 sont taguées avec des termes puissants comme « grain de film, effet trame, dark fantasy, couleurs atténuées, sépia ». Vous me verrez souvent les utiliser car mes prompts puisent dans des images sources contenant ces éléments. Si vous ne souhaitez pas les voir, ainsi que le style anime standard, indiquez-les dans les négatifs. Le style est tellement fort que l’on peut le retrouver même sans prompt. Quelques armes ont été ajoutées, notamment des épées, la "massive sword" de Guts, et les katanas (de Cis). Générer des images avec armes reste difficile, peu importe votre skill en prompt, à cause des limites de SDXL, mais j’espère que ces ajouts aideront le modèle à mieux poser les armes.
MISE À JOUR V2 : La V2 est la première version que j’ai entraînée et influencée moi-même manuellement. Elle est encore majoritairement basée sur la stack de la V1, mais certains poids ont été réduits et les images ajoutées ont corrigé quelques problèmes de la V1. La V2 se concentre davantage sur un éclairage et des effets style désert, et modifie légèrement le style artistique pour des yeux et des lèvres un peu plus petits. L’éclairage est devenu encore plus prononcé dans cette version, et j’ai l’impression que si j’en faisais trop, tout s’effondrerait. On peut appeler ça la mise à jour dune kegant.
kegant PDXL est un modèle basé sur pony visant à transformer pony en une apparence plus rétro et granuleuse tout en mettant fortement l’accent sur les effets d’éclairage.
Il se concentre principalement sur la version fusionnée de 5 loras distincts et 1 embedding dans le modèle ponyv6. Ces modèles sont :
https://civitai.com/models/366990/pony-custom-styles?modelVersionId=454703
https://civitai.com/models/341353/expressiveh-hentai-lora-style?modelVersionId=382152
https://civitai.com/models/550871/bss-styles-for-pony?modelVersionId=669776
https://civitai.com/models/122359/detail-tweaker-xl?modelVersionId=135867
https://civitai.com/models/118418/negativexl?modelVersionId=134583
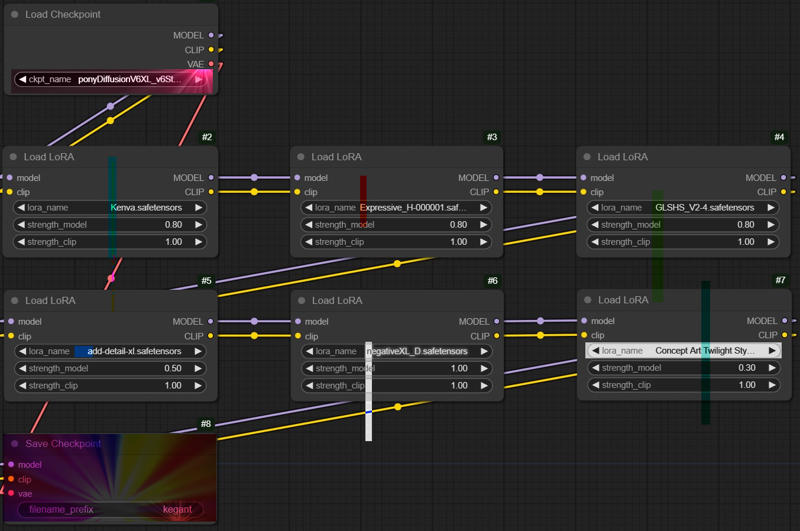 Si vous ne voyez pas l’image, les réglages suivants ont été utilisés durant la fusion :
Si vous ne voyez pas l’image, les réglages suivants ont été utilisés durant la fusion :
Kenva : .8
ExpressiveH : .8
GLSHS : .8
add_detail : .5
negativeXL_D : 1
Concept Art Twilight : .3
Notez que ce modèle a des biais pour générer des femmes et préfère que les sujets ne soient pas trop éloignés ni trop proches. Produire un corps entier peut être un peu difficile, mais si vous spécifiez des éléments comme « shoes », « boots » ou « feet/toes », le modèle aura plus tendance à vous donner les exemples complets que vous souhaitez. Rappelez-vous -- c’est un checkpoint basé sur pony. Il préfère largement le tagging de style danbooru au simple anglais. Parfois, moins c’est plus. Surcharger un prompt avec trop de tags complique la compréhension. Si le full body est important pour vous, mentionnez-le au début du prompt car plus un élément est placé haut dans le prompt, plus il est priorisé. Vous pouvez aussi le pondérer manuellement, ce qui aide encore. Je laisse tous mes prompts ouverts sur ce checkpoint si vous cherchez des conseils pour l’utiliser.
Cependant, ce checkpoint n’est pas aussi flexible que le goat (alias v6), mais en contrepartie vous gagnez en éclairage, style artistique, et vitesse de génération. Générer la même stack d’images avec tous les loras intégrés est environ 3 fois plus rapide que de le faire avec v6 et la stack complète, ce qui était l’objectif principal de ce checkpoint.
✨ Merci de partager vos belles créations ci-dessous ! ✨
Merci beaucoup d’avoir essayé mon premier checkpoint.
Veuillez vous référer à la page du modèle Pony V6 pour des directives de prompt plus détaillées.
☄️ Recommandations pour la génération
* Toutes les images d’aperçu ont été générées sans LORA sauf les deux dernières avec Haruko Haruhara et Lain, car pony ne comprend pas ces personnages très stylisés, difficiles à décrire seul. Aucun autre outil n’a été utilisé, juste du texte vers image avec un second passage d’upscaling latent uniquement (pas de pixel upscaling).
La plupart des images d’exemple ont été générées avec des samplers ancestraux du type suivant pour le premier passage :
Sampler : Euler A / DPM++A
Type de schedule : Karras
Steps : 20 - 30
CFG : 2 - 6
Clip Skip : 2
Denoise : 1
L’upscaler latent utilisé est très similaire, préférant souvent une variante Euler, généralement plus rapide pour produire les images.
Sampler : Euler A / DPM++A
Type de schedule : Karras
Steps : 15
CFG : 2 - 6
Denoise - 0.5
Upscale par : 1.5 - 2.0
Quelques conseils pour la génération : plus votre CFG sur l’upscaler latent (et les steps) est bas, plus l’image aura un aspect « peint », avec des traits plus doux et moins définis, créant un effet de « brouillard » sur certaines images. Inversement, plus la CFG est haute, plus l’image est « cuite » et brillante. Le réglage 3.0 cfg est sans doute le meilleur compromis pour mettre en valeur toutes les loras. Pour l’image de Harley Quinn jointe, j’ai poussé jusqu’à 10cfg pour montrer ce rendu, très abstrait cependant.
VEUILLEZ consulter mon workflow joint qui détaille comment manipuler pleinement kegant, que vous préfériez un design élégant et brillant ou des ambiances rétro plus douces avec effets de grain de film.
Dernière remarque : ce checkpoint a tendance à ajouter des "artefacts jpeg" et divers éléments de faune comme "plants" et "flowers". Il ajoute aussi des éléments "cyberpunk". Ajoutez ces tags dans les négatifs si vous ne les voulez pas, il les supprimera assez bien. Pour générer des sujets masculins, préciser "1girl" en négatif aide beaucoup, bien que ce checkpoint préfère largement les femmes.

Détails du modèle
Type de modèle
Modèle de base
Version du modèle
Hash du modèle
Créateur
Discussion
Veuillez vous log in pour laisser un commentaire.
Collection de modèles - kegant

Images par kegant - v1.0 / PDXL
Images avec anime










Images avec âpre










Images avec lighting










Images avec rétro










Images avec style









