SD XL - v1.0 Correction VAE
Mots-clés et tags associés
Images en vedette












Prompts négatifs recommandés
(deformed iris, deformed pupils), text, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, (extra fingers), (mutated hands), poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, (fused fingers), (too many fingers), long neck, camera
Paramètres recommandés
samplers
steps
cfg
resolution
Conseils
Le modèle est destiné à des fins de recherche, incluant la génération d’œuvres d’art, les outils éducatifs et le déploiement sécurisé.
Il n’est pas destiné à générer des représentations factuelles ou exactes de personnes ou d’événements.
Les limitations incluent un photoréalisme imparfait, l’incapacité à rendre un texte lisible, des défis avec les invites compositionnelles, et une possible génération incorrecte des visages.
Le modèle utilise deux encodeurs textuels pré-entraînés : OpenCLIP-ViT/G et CLIP-ViT/L.
Le pipeline en deux étapes comprend une génération latente de base suivie d’un raffinement haute résolution utilisant SDEdit (img2img).
Sponsors du créateur
Initialement publié sur Hugging Face et partagé ici avec l'autorisation de Stability AI.
Initialement publié sur Hugging Face et partagé ici avec l'autorisation de Stability AI.
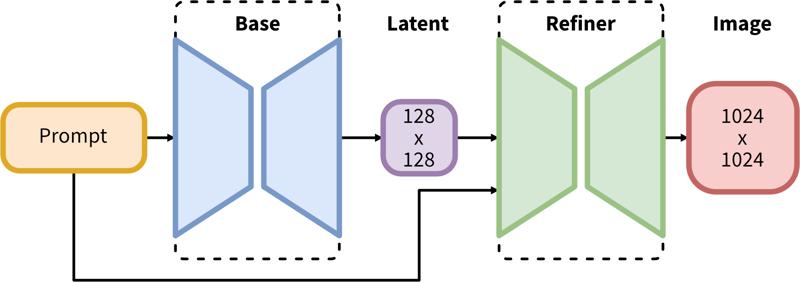
SDXL se compose d’un pipeline en deux étapes pour la diffusion latente : d’abord, nous utilisons un modèle de base pour générer des latents de la taille de sortie désirée. Dans la seconde étape, nous utilisons un modèle spécialisé haute résolution et appliquons une technique appelée SDEdit (https://arxiv.org/abs/2108.01073, également connu sous le nom "img2img") sur les latents générés à la première étape, en utilisant la même invite.
Description du Modèle
Développé par : Stability AI
Type de modèle : Modèle génératif texte-image basé sur la diffusion
Description du modèle : Il s'agit d'un modèle qui peut être utilisé pour générer et modifier des images basées sur des invites textuelles. C’est un Modèle de diffusion latente qui utilise deux encodeurs textuels fixes et pré-entraînés (OpenCLIP-ViT/G et CLIP-ViT/L).
Ressources pour plus d’informations : Dépôt GitHub.
Sources du Modèle
Démo [optionnelle] : https://clipdrop.co/stable-diffusion
Utilisations
Utilisation Directe
Le modèle est destiné uniquement à des fins de recherche. Les domaines et tâches de recherche possibles incluent
La génération d’œuvres d’art et son usage dans le design et d’autres processus artistiques.
Les applications dans des outils éducatifs ou créatifs.
La recherche sur les modèles génératifs.
Le déploiement sûr de modèles pouvant potentiellement générer du contenu nuisible.
Explorer et comprendre les limites et biais des modèles génératifs.
Les usages exclus sont décrits ci-dessous.
Usages Hors Scope
Le modèle n’a pas été entraîné pour produire des représentations factuelles ou exactes de personnes ou d’événements, donc l’utilisation du modèle pour générer ce type de contenu est hors du champ d’application des capacités de ce modèle.
Limitations et Biais
Limitations
Le modèle n’atteint pas un photoréalisme parfait
Le modèle ne peut pas rendre un texte lisible
Le modèle rencontre des difficultés avec des tâches plus complexes impliquant la composition, comme rendre une image correspondant à « Un cube rouge sur une sphère bleue »
Les visages et les personnes en général peuvent ne pas être générés correctement.
La partie d’auto-encodage du modèle est approximative.
Biais
Bien que les capacités des modèles de génération d’images soient impressionnantes, ils peuvent aussi renforcer ou aggraver des biais sociaux.
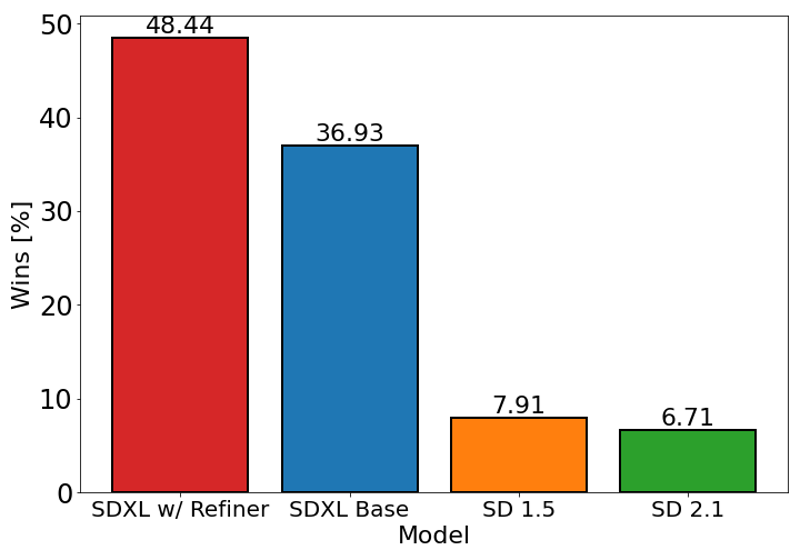
Le graphique ci-dessus évalue la préférence utilisateur pour SDXL (avec et sans raffinement) par rapport à Stable Diffusion 1.5 et 2.1. Le modèle de base SDXL performe significativement mieux que les variantes précédentes, et le modèle combiné au module de raffinement atteint la meilleure performance globale.

Détails du modèle
Type de modèle
Modèle de base
Version du modèle
Hash du modèle
Discussion
Veuillez vous log in pour laisser un commentaire.
Collection de modèles - SD XL


Images par SD XL - v1.0 Correction VAE
Images avec modèle de base

Images avec sdxl



Images avec stability ai



