SD XL - v1.0
Palavras-chave e Tags Relacionadas
Imagens em destaque












Parâmetros Recomendados
resolution
Dicas
O modelo destina-se a fins de pesquisa, incluindo geração de obras de arte, ferramentas educacionais e implantação segura.
Não se destina a gerar representações factuais ou verdadeiras de pessoas ou eventos.
As limitações incluem fotorealismo imperfeito, incapacidade de renderizar texto legível, desafios com prompts composicionais e possível geração incorreta de rostos.
O modelo usa dois encoders de texto pré-treinados: OpenCLIP-ViT/G e CLIP-ViT/L.
O pipeline de duas etapas inclui geração de latentes base seguida por refinamento em alta resolução usando SDEdit (img2img).
Patrocinadores do Criador
Originalmente Publicado no Hugging Face e compartilhado aqui com permissão da Stability AI.
Originalmente Publicado no Hugging Face e compartilhado aqui com permissão da Stability AI.
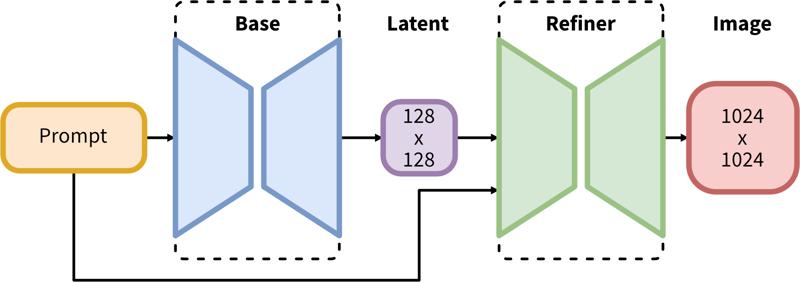
O SDXL consiste em um pipeline de duas etapas para difusão latente: Primeiro, usamos um modelo base para gerar latentes no tamanho desejado da saída. Na segunda etapa, usamos um modelo especializado de alta resolução e aplicamos uma técnica chamada SDEdit (https://arxiv.org/abs/2108.01073, também conhecida como "img2img") aos latentes gerados na primeira etapa, usando o mesmo prompt.
Descrição do Modelo
Desenvolvido por: Stability AI
Tipo de modelo: Modelo generativo de texto para imagem baseado em difusão
Descrição do Modelo: Este é um modelo que pode ser usado para gerar e modificar imagens a partir de prompts de texto. É um Modelo de Difusão Latente que utiliza dois encoders de texto fixos e pré-treinados (OpenCLIP-ViT/G e CLIP-ViT/L).
Recursos para mais informações: Repositório GitHub.
Fontes do Modelo
Repositório: https://github.com/Stability-AI/generative-models
Demo [opcional]: https://clipdrop.co/stable-diffusion
Usos
Uso Direto
O modelo se destina apenas a fins de pesquisa. Possíveis áreas e tarefas de pesquisa incluem
Geração de obras de arte e uso em design e outros processos artísticos.
Aplicações em ferramentas educacionais ou criativas.
Pesquisa em modelos generativos.
Implantação segura de modelos que têm potencial para gerar conteúdo prejudicial.
Sondagem e compreensão das limitações e vieses dos modelos generativos.
Os usos excluídos são descritos abaixo.
Uso Fora do Escopo
O modelo não foi treinado para representar pessoas ou eventos de forma factual ou verdadeira, portanto usar o modelo para gerar tal conteúdo está fora do escopo das capacidades deste modelo.
Limitações e Vieses
Limitações
O modelo não alcança fotorealismo perfeito
O modelo não consegue renderizar texto legível
O modelo tem dificuldades com tarefas mais complexas que envolvem composição, como renderizar uma imagem correspondente a “um cubo vermelho em cima de uma esfera azul”
Rostos e pessoas em geral podem não ser gerados corretamente.
A parte de autoencodificação do modelo é com perda.
Viés
Embora as capacidades dos modelos de geração de imagem sejam impressionantes, eles também podem reforçar ou agravar vieses sociais.
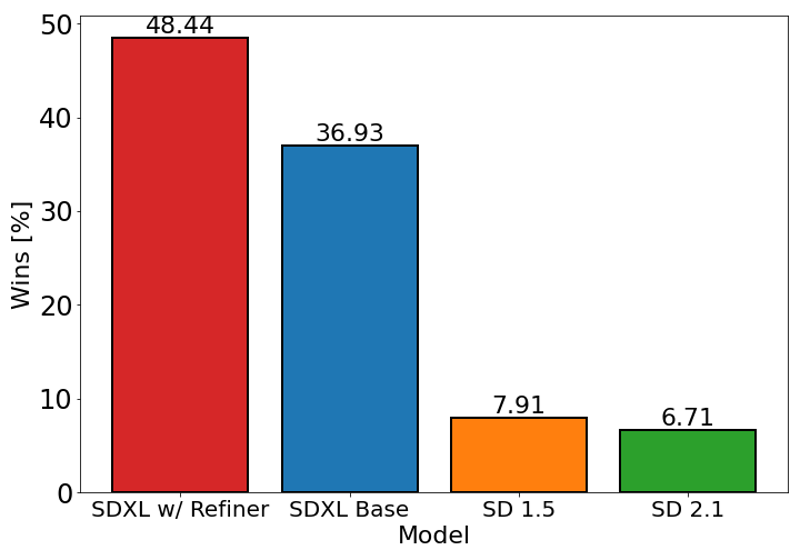
O gráfico acima avalia a preferência dos usuários pelo SDXL (com e sem refinamento) em comparação com Stable Diffusion 1.5 e 2.1. O modelo base SDXL apresenta desempenho significativamente melhor que as variantes anteriores, e o modelo combinado com o módulo de refinamento alcança o melhor desempenho geral.

Detalhes do Modelo
Tipo de modelo
Modelo base
Versão do modelo
Hash do modelo
Discussão
Por favor, faça log in para deixar um comentário.
Coleção de Modelos - SD XL

Imagens por SD XL - v1.0
Imagens com modelo base

Imagens com sdxl



Imagens com stability ai



