SD XL - v1.0 VAE fix
Palavras-chave e Tags Relacionadas
Imagens em destaque












Prompts Negativos Recomendados
(deformed iris, deformed pupils), text, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, (extra fingers), (mutated hands), poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, (fused fingers), (too many fingers), long neck, camera
Parâmetros Recomendados
samplers
steps
cfg
resolution
Dicas
O modelo é destinado a fins de pesquisa, incluindo geração de obras de arte, ferramentas educacionais e implantação segura.
Não é destinado a gerar representações factuais ou verdadeiras de pessoas ou eventos.
As limitações incluem fotorealismo imperfeito, incapacidade de renderizar texto legível, desafios com prompts composicionais e possível geração incorreta de faces.
O modelo utiliza dois codificadores de texto pré-treinados: OpenCLIP-ViT/G e CLIP-ViT/L.
O pipeline em duas etapas inclui geração latente base seguida de refinamento em alta resolução usando SDEdit (img2img).
Patrocinadores do Criador
Originalmente Publicado no Hugging Face e compartilhado aqui com permissão da Stability AI.
Originalmente Publicado no Hugging Face e compartilhado aqui com permissão da Stability AI.
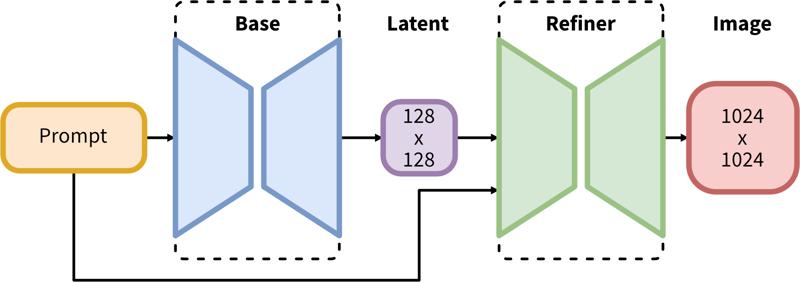
O SDXL consiste em um pipeline de duas etapas para difusão latente: Primeiro, usamos um modelo base para gerar latentes do tamanho desejado da saída. Na segunda etapa, usamos um modelo especializado de alta resolução e aplicamos uma técnica chamada SDEdit (https://arxiv.org/abs/2108.01073, também conhecido como "img2img") nos latentes gerados na primeira etapa, usando o mesmo prompt.
Descrição do Modelo
Desenvolvido por: Stability AI
Tipo de modelo: Modelo generativo texto-imagem baseado em difusão
Descrição do modelo: Este é um modelo que pode ser usado para gerar e modificar imagens com base em prompts de texto. É um Modelo de Difusão Latente que usa dois codificadores de texto pré-treinados fixos (OpenCLIP-ViT/G e CLIP-ViT/L).
Recursos para mais informações: Repositório GitHub.
Fontes do Modelo
Repositório: https://github.com/Stability-AI/generative-models
Demo [opcional]: https://clipdrop.co/stable-diffusion
Usos
Uso Direto
O modelo é destinado apenas para fins de pesquisa. Áreas e tarefas possíveis de pesquisa incluem
Geração de obras de arte e uso em design e outros processos artísticos.
Aplicações em ferramentas educacionais ou criativas.
Pesquisa em modelos generativos.
Implantação segura de modelos com potencial para gerar conteúdo prejudicial.
Investigação e entendimento das limitações e vieses dos modelos generativos.
Usos excluídos são descritos abaixo.
Uso Fora do Escopo
O modelo não foi treinado para ser representações factuais ou verdadeiras de pessoas ou eventos, portanto, usar o modelo para gerar tais conteúdos está fora do escopo das capacidades deste modelo.
Limitações e Viés
Limitações
O modelo não alcança fotorealismo perfeito.
O modelo não consegue renderizar texto legível.
O modelo tem dificuldade com tarefas mais complexas que envolvem composição, como renderizar uma imagem correspondente a “Um cubo vermelho em cima de uma esfera azul”.
Faces e pessoas em geral podem não ser geradas corretamente.
A parte de autoencodificação do modelo é com perda.
Viés
Embora as capacidades dos modelos de geração de imagem sejam impressionantes, eles também podem reforçar ou exacerbar vieses sociais.
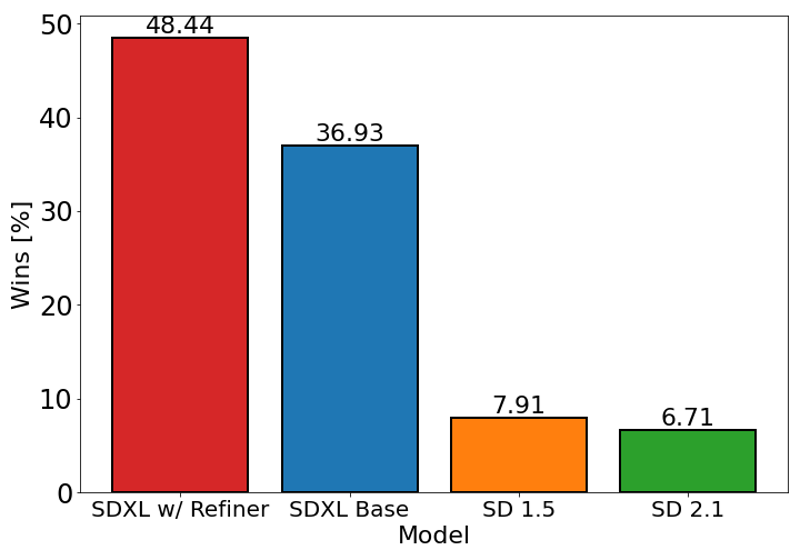
O gráfico acima avalia a preferência dos usuários pelo SDXL (com e sem refinamento) em comparação ao Stable Diffusion 1.5 e 2.1. O modelo base SDXL apresenta desempenho significativamente melhor que as variantes anteriores, e o modelo combinado com o módulo de refinamento alcança o melhor desempenho geral.

Detalhes do Modelo
Tipo de modelo
Modelo base
Versão do modelo
Hash do modelo
Discussão
Por favor, faça log in para deixar um comentário.
Coleção de Modelos - SD XL


Imagens por SD XL - v1.0 VAE fix
Imagens com modelo base

Imagens com sdxl



Imagens com stability ai



