AlbedoBase XL - v1.1
精選圖片



推薦反向提示詞
strabismus
inconsiderate details
推薦參數
samplers
steps
cfg
resolution
vae
推薦高解析度參數
upscaler
upscale
steps
denoising strength
提示
如果圖像生成無結果,請嘗試切換為 CLIP SKIP 2 或稍作調整提示詞的詞序或用詞。
使用句子形式的提示詞往往比標籤列表提示詞更能提升圖像質量。
留空負面提示欄通常可帶來更佳的圖像結果。
使用前請查看規格網格以獲取最佳設置。
嘗試使用幾個特定負面提示詞,如「斜視」,以解決不對稱眼睛或像素化等問題。
版本亮點
創作者贊助
如果您覺得此模型有幫助,請考慮提供支持。您的貢獻將全部用於推動 SDXL 社群發展。
🙋🏼♂️ 加入我們 (discord) ㅤ|ㅤ 🛒 購買 ㅤ|ㅤ 🌱 捐助
如果您覺得此模型有幫助,請考慮提供支持。您的貢獻將全部用於推動 SDXL 社群發展。
🙋🏼♂️ 加入我們 (discord) ㅤ|ㅤ 🛒 購買ㅤ |ㅤ 🌱 捐助
AlbedoBase XL (SFW&NSFW)
無需精煉器,且包含 VAE。
目標
Stable Diffusion XL 擁有 35 億參數(不包含精煉器),約為 SD v1.5 版本的 3.6 倍。我相信這不僅是一個數字,而是一個能帶來顯著性能提升的數字。
由於社群的爆炸性貢獻,SD v1.5 的整體性能已有了超乎想像的提升。因此,我致力於完成 AlbedoBase XL 模型,旨在最佳化地再現 v1.5 版本的性能提升於此 XL 版本中。
我的目標是直接測試所有公開上傳至 Civitai 的檢查點和 LoRA,並通過多道篩選後僅合併被判定為最佳的資源。這將超越 Midjourney 等公司的圖像生成 AI 性能。
目前,AlbedoBase XL v3.1 Large 已融合約 200 個精選檢查點和 251 個 LoRA。
更新日誌
v3.1-Large
• 使用 V3 採用的遞歸腳本,合併了 50 多個精選最新版本的 SDXL 模型。
規格網格(370.7 MB): 下載


v3-mini
非常抱歉讓各位久等了。
我一直在處理一些個人事務,在開發新版本的同時,也面臨健康問題。即使寫這段文字時,我仍在與這些挑戰奮鬥。
我感覺僅提供簡短的更新不足以說明情況,因此請您理解我這次分享較為詳盡的訊息。
自從 2.0 版本發布後,我一直自主學習深度學習。我並無正式學位,除了對程式設計有些許天賦外,本科背景為藝術,因此在時間與努力投入下仍缺乏數學和科學基礎來取得重大突破。但這段自學與研究的經歷,是我生命中無價的寶藏。
最近,我偶然想到了一個可能是重大突破的點子。自 2.0 版本以來經歷數百次公式與方法的重新調整,成功開發出相當有趣且有效的算法。合併模型基於 SDXL1.0 和 SD1.5 以及其他精選模型。這些模型被分為 “ANIME”、“REALISM”、“ARTISTIC”、“NSFW” 及 “BASE” 五大類,並作為數據集餵入合併算法,成果頗具吸引力。
然而,算法開發的挑戰並非最大的困難,最艱難的是性能測試階段。我經歷了身心健康的嚴重惡化,甚至認識到無法獨自完成這項工作,這最終促使我決定釋出此版本。
現在,我很高興宣布期待已久的 AlbedoBaseXL V3 Mini 版本發布。該模型雖屬小規模合併,卻無特定領域限制,在多個領域表現優異,有潛力成為 SDXL1.0 的新基礎模型。(參考:我的合併算法非線性合併,實質可視為新精調模型。)
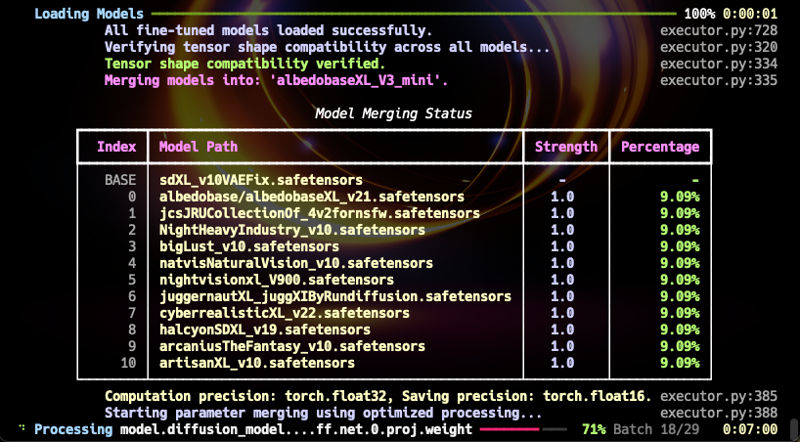
此模型與現存 AlbedoBase 模型皆多才多藝,且在各方面均超越前作。(NSFW 內容雖不極端,表現範圍卻較 v2.1 等前版本更廣。未來將釋出專門的 NSFW 合併模型。)
此外,我發現許多共享模型近期開始採用禁止合併或外部商業化的授權,令人失望,因為這阻止我使用一些優秀模型進行合併。
我要衷心感謝那些提供免費授權的模型開發者,讓這些經過時間與心血打磨的高品質模型得以用於合併。
我會很快回來。
期待您在 ANIME、REALISM、ARTISTIC、2.5D、3D 及 NSFW 等多領域的性能測試結果。
作為模型開發者,我們僅播下種子。最終由使用者和藝術家們培育,使其開花結果。
感謝一如既往的支持。
如果您願意提供少量經濟支持,請考慮使用以下連結。本人目前無法穩定就業,生活前景不明。
規格網格(380.5 MB): 下載


v2.1
使用新合併算法與公式重新合併並調整 v0.1 至 2.0 版本。
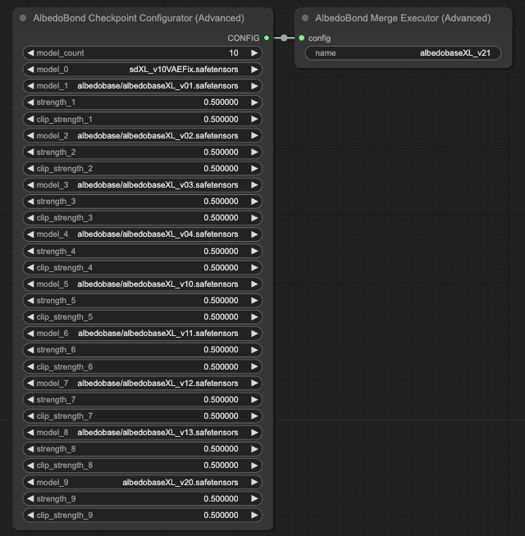
規格網格(424.5 MB): 下載

v2.0
感謝所有協助我開發 AlbedoBase XL Pre 的朋友們。沒有你們,發布日會更晚。非常感謝!
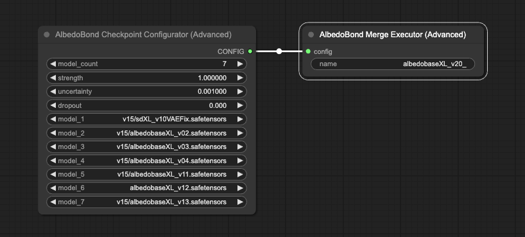
我撰寫了自訂腳本,將現有 AlbedoBase XL 模型收斂為一體。根據我獨特公式,細緻對齊所有 U-NET 和 CLIP 區塊的行列權重。
若生成圖像出現錯誤(無圖像產出),請嘗試切換 CLIP SKIP 2 或稍作調整提示詞,如改變詞序或詞彙!有些詞組 CLIP 可能無法識別。在此情況下,可調整詞序、使用不同詞彙,或最簡單地改變 CLIP SKIP。未來我會像 v1.3 一樣逐步解決這些問題。
規格網格(403.5 MB): 下載
v1.3
為展示模型隨機性相關質量,我將用於採樣的所有示範圖片統一採用 "9" 作為種子值,並即時生成。
特別是本版本,負面提示詞的影響顯著,留空負面提示欄往往能產生更佳品質結果。
規格網格(438.7 MB): 下載

如您所見,隨著步數增加,幾乎所有採樣器皆可用,且品質提升。
由於我開發並融合的 LoRA 影響,如下所述,使用句子形式提示詞相比標籤(詞列表)提示詞更能直接提升品質。
我融合了 45 個檢查點與 7 個 LoRA。隨後,依序融合了 AlbedoBase v0.4 與 v0.3,比例不到 0~5%,旨在喚醒已過時的稀釋合併模型。
7 個 LoRA 中一個是由我創建。它通過 GPT4-V 分析並標註了共 174 張高品質繪圖照片的標題。融合此 LoRA 使圖像極為清晰,對提示詞理解也相當出色。
我自創的LoRA僅供Ko-fi Creative 級別及以上支持者購買。
v1.2
融合最新的 22 個檢查點。
規格網格(565.6 MB): 下載
v1.1
穩定化。
更細緻。
如果您是高級用戶,建議使用 1.0 版本。若 1.0 版本找到合適設置,可產出更加生動的作品。
規格網格(349.7 MB): 下載
v1.0
融合了 106 個 LoRA。
融合了 19 個檢查點。
模型效果會依您的設置不同而異,使用前請務必查看規格網格。
我發現使用某些特定負面提示詞能有效解決兩眼不對稱或像素化問題。規格網格可能依 CPU 或 GPU 不同而變異,僅供參考。可嘗試幾個負面提示詞提升質量(如斜視)。隨著融合 LoRA 數量增加,滿足所有設定會更難,但我希望您注意 1.0 版本利用合適設置能產出各方面驚人品質的作品。我將在未來帶來更穩定版本方案。
您可在示範中或透過搜尋獲得實用參數設置。
一如既往,最佳結果通常在留空負面提示時出現。
1.0 版本開發工作繁重,我將稍作休息。希望您喜歡使用此模型,若您有合併版本,請在 Civitai 免費分享,讓我們共同進步。
規格網格(479.4 MB): 下載
v0.4
融合了 132 個 LoRA。
融合了 4 個檢查點。
規格網格: 下載
v0.3
所有採樣器均有所改進。
達到擬真逼真度。
穩定性提升。
規格網格: 下載
v0.2
清晰度與細節明顯提升。
手部與足部表現改進。
整體美學大幅提升;包括構圖、抽象化、流程、光影與色彩等。
v0.1
在 SDXL1.0 模型適當微調後,精心且有目的地合併超過 40 個 Civitai 公開的高品質模型。
測試主要聚焦以最低提示詞數量達成最高質量,尚未確定大量提示詞使用時質量提升幅度。(請自行測試並分享結果)
通常在現實與動畫風格中點取得最美結果。
儘管如此,使用適當提示詞一般無所不能表達。(我認為此模型作為融合基礎模型有豐富價值,但請注意目前仍為 v0.1 版本)

模型詳情
模型類型
基礎模型
模型版本
模型雜湊值
訓練詞彙
創作者
討論
請log in以發表評論。
模型合集 - AlbedoBase XL





AlbedoBase XL - v1.1 的圖片
3d 圖片










多合一 圖片



動畫 圖片










基礎模型 圖片

攝影寫實 圖片









