AlbedoBase XL - v2.0
精選圖片












推薦反向提示詞
strabismus,asymmetrical eyes,pixelated images
amateur quality, vague shapes, vague texture, wrong perspective, ugly, dowdy style
推薦參數
samplers
steps
cfg
clip skip
resolution
vae
提示
若出現無生成結果錯誤,請切換至 CLIP SKIP 2 或稍微修改提示詞。
使用句子形式提示詞而非標籤列表提升圖像質量。
留空負面提示欄位通常產生最佳畫質。
使用前請查看規格表推薦的設定。
嘗試使用數種負面提示詞,以解決如眼睛不對稱或像素化問題。
版本亮點
我撰寫了自訂腳本,將現有 AlbedoBase XL 模型合併為一體。精細對齊所有 U-NET 和 CLIP 模組的行列權重,依據我獨特的公式執行。
創作者贊助
如果您覺得本模型有價值,請考慮支持。您的資助將全數用於促進 SDXL 社群發展。
🙋🏼♂️ 加入我們 (discord) ㅤ|ㅤ 🛒 購買ㅤ |ㅤ 🌱 捐贈
如果您覺得本模型有價值,請考慮支持。您的資助將全數用於促進 SDXL 社群發展。
🙋🏼♂️ 加入我們 (discord) ㅤ|ㅤ 🛒 購買ㅤ |ㅤ 🌱 捐贈
AlbedoBase XL (SFW&NSFW)
無需精煉器,且包含 VAE。
目標
Stable Diffusion XL 擁有 35 億參數(不含精煉器),約為 SD v1.5 的 3.6 倍。我相信這不僅僅是數字,而是能帶來性能大幅提升的關鍵。
自從我們意識到因社群爆炸性貢獻,SD v1.5 的整體性能超越想像後,便投入精力完成 AlbedoBase XL,以期在此 XL 版本中最佳還原 v1.5 的性能提升。
我的目標是直接測試所有公開上傳至 Civitai 的檢查點與 LoRA,經多重過濾後僅合併最佳資源,超越 Midjourney 等影像生成 AI 的性能。
截至目前,AlbedoBase XL v3.1 Large 已合併約 200 個精選檢查點及 251 個 LoRA。
更新日誌
v3.1-Large
• 使用 V3 採用的遞歸腳本合併超過 50 個精選最新 SDXL 模型版本。
規格表(370.7 MB): 下載


v3-mini
非常抱歉讓大家等待這麼久。
我一直在處理一些個人事務,且在開發新版本期間遭遇健康問題。即便寫下這些文字,我仍在與挑戰抗爭。
我覺得只更新簡短訊息不夠,因此請您理解我分享此較詳細說明。
自版本 2.0 釋出後,我便自學深度學習。沒有正式學位,除了程式設計的初步能力外,只有藝術背景。因此,雖投入大量時間精力,卻缺乏數理基礎,難以獲得重大突破。但這段自學與研究的經歷,是我人生中無價的寶藏。
近日我偶然想到一個可能的重大突破。自版本 2.0 以來重構了數百個公式與方法,最終開發出一套相當有趣且成功的算法。模型合併過程基於 SDXL1.0 和 SD1.5 及其他嚴選模型,分成「ANIME」、「REALISM」、「ARTISTIC」、「NSFW」和「BASE」五大類別,作為資料集餵入合併算法。這方法帶來了相當吸引人的成果。
然而,算法開發雖具挑戰,性能測試階段更為艱難。此期間身心大幅受損,直到意識到無法獨自繼續,才決定釋出此版本。
現在,我很高興宣布期待已久的 AlbedoBaseXL V3 Mini 發布。此版本合併規模較小,但不限於特定領域,且在多個領域表現優異,有望成為 SDXL1.0 新基礎模型。(我的合併算法非「線性合併」,可視為新微調模型。)
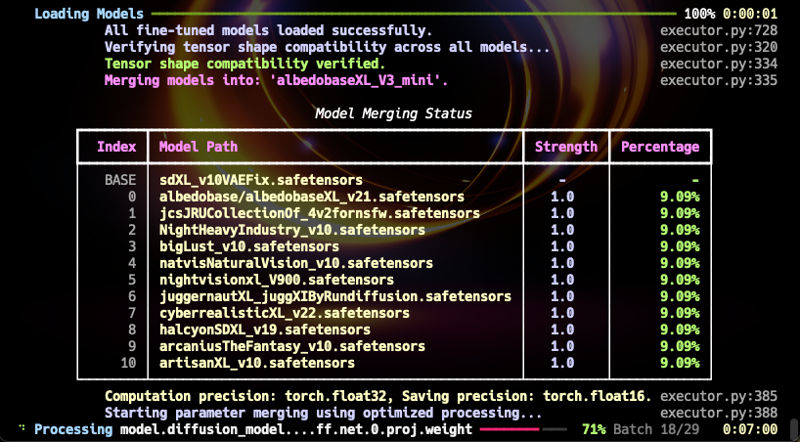
此模型與現有 AlbedoBase 系列多功能且超越之前所有版本。(NSFW 內容較溫和,但比起如 v2.1 等版本具更廣泛表現力。未來將釋出專門 NSFW 合併模型。)
另外,我注意到近期許多分享模型開始採用禁止合併或外部商業化的授權,令人遺憾,無法使用部分優秀模型進行合併。
衷心感謝那些提供免費授權的模型開發者,讓他們耗時心力打造的高品質模型能用於合併。
我會盡快回歸。
期待您在 ANIME、REALISM、ARTISTIC、2.5D、3D 及 NSFW 等多領域的性能測試結果。
作為模型開發者,我們只是種下種子,最終由使用者與藝術家們培育並綻放花果。
感謝一如既往的支持。
若您願意以小額資助支持我的工作,請使用以下連結。目前我無法找到工作,生計前景不明。
規格表(380.5 MB): 下載


v2.1
重新合併與調整 v0.1 至 2.0,採用全新合併算法與公式。
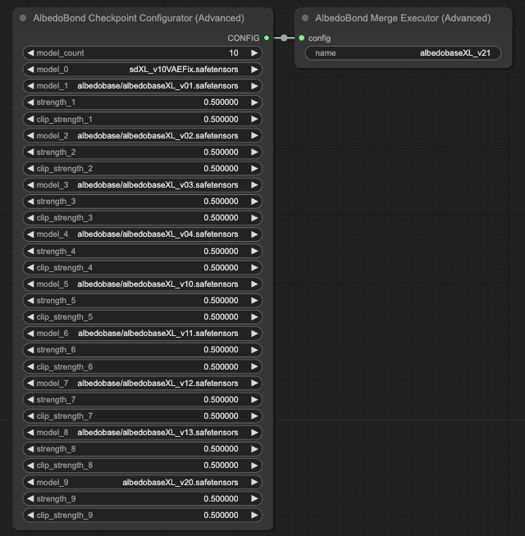
規格表(424.5 MB): 下載

v2.0
感謝所有在 AlbedoBase XL Pre 項目中協助我的朋友。沒有你們,發佈日期恐怕會晚得多。非常感謝!
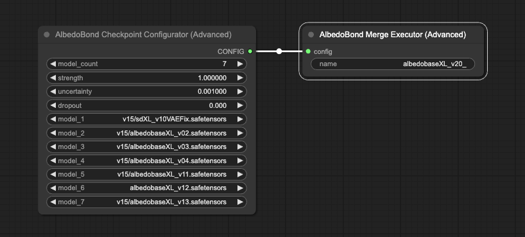
我撰寫了自訂腳本,將現有 AlbedoBase XL 模型合併為一體。精細對齊所有 U-NET 和 CLIP 模組的行列權重,依據我獨特的公式執行。
若生成圖片出現錯誤(如無生成結果),請切換至 CLIP SKIP 2 或稍作修改提示詞!可能有提示詞組合 CLIP 無法識別。在此情況下,可調整詞序、使用不同詞彙,或簡單更換 CLIP SKIP。我將持續逐步解決此類問題,類似 v1.3。
規格表(403.5 MB): 下載
v1.3
為展示模型的隨機性品質,我將取樣展示圖像的隨機種子統一為 '9',並立即生成。
特別是此版本,因負面提示詞效果明顯,留空負面提示欄位 反而通常產生 優良品質。
規格表(438.7 MB): 下載

如所見,隨著 步數增加,適用於 所有採樣器,且畫質提升。
受我開發合併的 LoRA 影響,如下所述,使用句子形式提示詞 比起標籤(詞彙列表)提示品質更佳。
我 合併了 45 個檢查點和 7 個 LoRA。之後依序合併了 AlbedoBase v0.4 和 v0.3,比例不超過 0~5%,以恢復已稀釋的過時合併模型。
7 個 LoRA 中有一個由我創作,透過 GPT4-V 分析並註解了共計 174 張高品質圖片的標題。合併後帶來驚人清晰度與對提示的卓越理解。
我 自創的 LoRA 僅提供 給 Ko-fi Creative 等級以上 supporter 購買。
v1.2
合併了最新 22 個檢查點。
規格表(565.6 MB): 下載
v1.1
穩定性提升。
細節更豐富。
若您是進階使用者,推薦使用版本 1.0。若設定得當,能輸出更鮮明作品。
規格表(349.7 MB): 下載
v1.0
合併 106 個 LoRA。
合併 19 個檢查點。
模型表現取決於您的設定,使用前請務必 查看規格表。
我發現使用特定負面提示詞能解決眼睛不對稱或像素化問題。但規格表會依 CPU 或 GPU 硬體不同而異,請僅做參考。您可以嘗試多種負面提示詞以提升品質(例如:斜視)。合併越多 LoRA,越難同時滿足所有設定。但我希望您在版本 1.0 注重它的優勢,只要設定得當即可產出驚人品質作品。未來會帶來更穩定版本。
您可在展示頁或其他使用者經驗中尋找有用設定值。
一如既往,最佳效果是留空 負面提示欄位。
此版本工作量巨大,我將稍作休息。希望您喜歡本模型,若您有合併,請在 Civitai 免費分享,共同進步。
規格表(479.4 MB): 下載
v0.4
合併 132 個 LoRA。
合併 4 個檢查點。
規格表: 下載
v0.3
所有採樣器均有改善。
達到逼真寫實。
穩定性提升。
規格表: 下載
v0.2
清晰度和細節有顯著提升。
手腳實現改進。
美學大幅改善;構圖、抽象、流動感、光影與色彩等。
v0.1
在適度微調 SDXL1.0 模型後,有目的地合併超過 40 個在 Civitai 公開的高品質模型。
測試主要集中在用最少提示詞令品質最大化,尚未確認使用大量提示詞品質能提升多少。(請自行測試並分享結果)
通常,在現實與動畫之間的中點產出最美麗結果。
不過,若使用適當提示,基本無表現不了的內容。(我斷言它具備作為基礎模型超越其他合併模型的豐富價值,但目前僅為 v0.1。)

模型合集 - AlbedoBase XL





AlbedoBase XL - v2.0 的圖片
3d 圖片










多合一 圖片



動畫 圖片










基礎模型 圖片









