AlbedoBase XL - v2.0
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder












Empfohlene Negative Prompts
strabismus,asymmetrical eyes,pixelated images
amateur quality, vague shapes, vague texture, wrong perspective, ugly, dowdy style
Empfohlene Parameter
samplers
steps
cfg
clip skip
resolution
vae
Tipps
Wenn beim Generieren nichts entsteht, wechseln Sie zu CLIP SKIP 2 oder ändern Sie den Prompt leicht.
Die Verwendung von Satz-Prompts statt einer Liste von Tags verbessert die Bildqualität.
Das Feld für negative Prompts leer zu lassen erzeugt oft die beste Bildqualität.
Überprüfen Sie vor der Verwendung das Spec Grid für empfohlene Einstellungen.
Experimentieren Sie mit einigen negativen Prompts, um Probleme wie asymmetrische Augen oder Pixelierung zu beheben.
Versions-Highlights
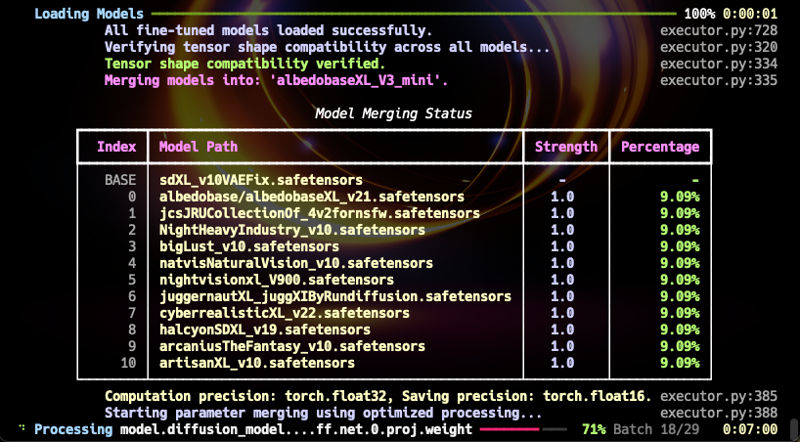
Ich habe ein benutzerdefiniertes Skript geschrieben, um die bestehenden AlbedoBase XL-Modelle zu einem Modell zusammenzuführen. Dabei werden die Reihen- und Spaltengewichte aller U-NET- und CLIP-Blöcke sorgfältig gemäß einer einzigartigen Formel von mir ausgerichtet.
Ersteller-Sponsoren
Wenn Ihnen das Modell gefällt, erwägen Sie bitte, Ihre Unterstützung anzubieten. Ihr Beitrag fließt vollständig in die Weiterentwicklung der SDXL-Community ein.
🙋🏼♂️ treten Sie uns bei (discord) ㅤ|ㅤ 🛒 kaufenㅤ |ㅤ 🌱 spenden
Wenn Ihnen das Modell gefällt, erwägen Sie bitte, Ihre Unterstützung anzubieten. Ihr Beitrag fließt vollständig in die Weiterentwicklung der SDXL-Community ein.
🙋🏼♂️ treten Sie uns bei (discord) ㅤ|ㅤ 🛒 kaufenㅤ |ㅤ 🌱 spenden
AlbedoBase XL (SFW&NSFW)
Der Feinabstimmer ist nicht notwendig, und VAE ist enthalten.
ZIEL
Stable Diffusion XL hat 3,5 Milliarden Parameter (ohne den Refiner), was etwa 3,6-mal mehr als die SD v1.5 Version ist. Ich glaube, dass dies nicht nur eine Zahl ist, sondern eine Zahl, die zu einer erheblichen Leistungssteigerung führen kann.
Es ist schon eine Weile her, dass wir festgestellt haben, dass die gesamte Leistung von SD v1.5 dank der explosiven Beiträge unserer Community die Vorstellungskraft übertroffen hat. Daher arbeite ich daran, dieses AlbedoBase XL Modell fertigzustellen, um die Leistungsverbesserung, die in v1.5 auftrat, auch in dieser XL-Version optimal nachzubilden.
Mein Ziel ist es, die Leistung aller öffentlich auf Civitai hochgeladenen Checkpoints und LoRAs direkt zu testen und nur die Ressourcen zusammenzuführen, die nach mehreren Filtern als optimal beurteilt werden. Dies wird die Leistung bildgenerierender KI von Unternehmen wie Midjourney übertreffen.
Bis jetzt wurde AlbedoBase XL v3.1 Large mit etwa 200 ausgewählten Checkpoints und 251 LoRAs zusammengeführt.
PROTOKOLL
v3.1-Large
• Über 50 ausgewählte neueste Versionen von SDXL-Modellen wurden mit dem rekursiven Skript aus V3 zusammengeführt.
Das Spec Grid (370,7 MB): herunterladen


v3-mini
Ich entschuldige mich aufrichtig, dass Sie so lange warten mussten.
Ich hatte einige persönliche Angelegenheiten zu bewältigen, und während ich an der neuen Version arbeitete, hatte ich auch gesundheitliche Probleme. Selbst während ich dies schreibe, kämpfe ich noch mit diesen Herausforderungen.
Ich dachte, eine kurze Aktualisierung wäre nicht genug, deshalb bitte ich um Ihr Verständnis, während ich diese detaillierte Nachricht teile.
Seit der Veröffentlichung von Version 2.0 widme ich mich dem selbstständigen Studium von Deep Learning. Ich habe keinen formalen Abschluss und abgesehen von einer bescheidenen Programmierbegabung ist mein Hintergrund in den Künsten. Daher fehlt mir die mathematische und wissenschaftliche Grundlage, um große Durchbrüche zu erzielen, trotz der investierten Zeit und Mühe. Dennoch war die Erfahrung, mich in dieses selbstgesteuerte Studium und die Forschung zu vertiefen, ein unbezahlbarer Schatz in meinem Leben.
Kürzlich bin ich auf eine Idee gestoßen, die möglicherweise ein bedeutender Durchbruch sein könnte. Nach Überarbeitung von Hunderten von Formeln und Methoden seit Version 2.0 entwickelte ich einen recht interessanten und erfolgreichen Algorithmus. Der Modellzusammenführungsprozess basierte auf SDXL1.0 und SD1.5 sowie anderen sorgfältig ausgewählten Modellen. Diese wurden in fünf Hauptkategorien eingeteilt: „ANIME“, „REALISMUS“, „KÜNSTLERISCH“, „NSFW“ und „BASIS“ und als Datensätze in den Zusammenführungsalgorithmus eingespeist. Dieser Ansatz hat faszinierende Ergebnisse erzielt.
So herausfordernd die Algorithmusentwicklung war, war die Leistungsprüfung die größte Herausforderung. Meine körperliche und geistige Gesundheit verschlechterte sich in dieser Zeit erheblich, sodass ich erkannte, dass ich diese Arbeit nicht allein fortsetzen konnte. Dies führte letztlich dazu, diese Version zu veröffentlichen.
Und jetzt freue ich mich, die lang erwartete AlbedoBaseXL V3 Mini-Version ankündigen zu können. Obwohl dieses Modell eine kleinere Zusammenführung ist, ist es nicht auf einen bestimmten Bereich beschränkt und liefert in verschiedensten Bereichen bemerkenswerte Leistungen. Es hat das Potenzial, als neues Basismodell für SDXL1.0 zu dienen. (Zum Vergleich: Mein Zusammenführungsalgorithmus ist keine „lineare Zusammenführung“ und kann daher im Wesentlichen als neues feinabgestimmtes Modell betrachtet werden.)
Dieses Modell ist zusammen mit den bestehenden AlbedoBase-Modellen vielseitig einsetzbar und übertrifft alle früheren Versionen in jeder Hinsicht. (Der NSFW-Inhalt ist zwar nicht extrem, bietet aber einen breiteren Ausdrucksbereich im Vergleich zu früheren Versionen wie v2.1. Ein spezielles NSFW-Zusammenführungsmodell wird in Zukunft veröffentlicht.)
Außerdem ist mir aufgefallen, dass viele geteilte Modelle kürzlich Lizenzen übernommen haben, die das Zusammenführen oder externe kommerzielle Nutzung verbieten. Das war enttäuschend, da ich einige wirklich ausgezeichnete Modelle nicht für das Zusammenführen verwenden konnte.
Ich möchte den Modellentwicklern herzlich danken, die kostenlose Lizenzen vergeben haben, damit ihre hochwertigen Modelle – Produkte großer Zeit und Mühe – für das Zusammenführen genutzt werden können.
Ich komme bald zurück.
Ich freue mich sehr auf Ihre Leistungstests in den verschiedensten Bereichen, einschließlich ANIME, REALISMUS, KÜNSTLERISCH, 2.5D, 3D und NSFW.
Als Modellentwickler pflanzen wir nur die Samen. Letztlich sind Sie, die Nutzer und Künstler, die diese pflegen und Blumen und Früchte hervorbringen.
Vielen Dank wie immer.
Für diejenigen, die meine Arbeit mit einem kleinen finanziellen Beitrag unterstützen möchten, verwenden Sie bitte die Links unten. Ich kann derzeit keine Anstellung finden und sehe einer unsicheren Zukunft entgegen.
Das Spec Grid (380,5 MB): herunterladen


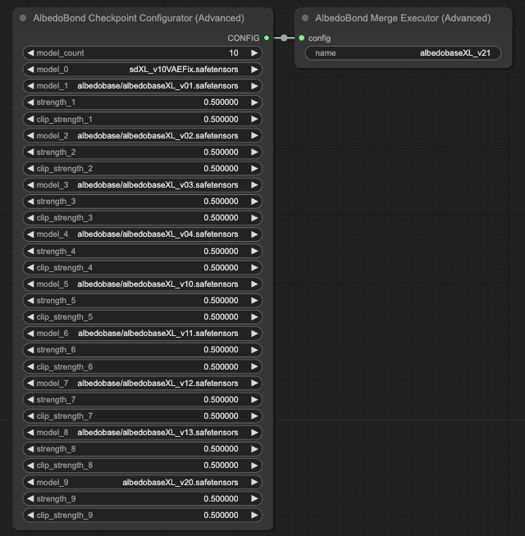
v2.1
Zusammenführung und Anpassung von v0.1 bis 2.0 mit neuem Zusammenführungsalgorithmus und Formel.
Das Spec Grid (424,5 MB): herunterladen

v2.0
Ich möchte allen danken, die mich auf der AlbedoBase XL Pre-Seite unterstützt haben. Ohne euch wäre das Veröffentlichungsdatum wahrscheinlich viel später gewesen. Vielen Dank!
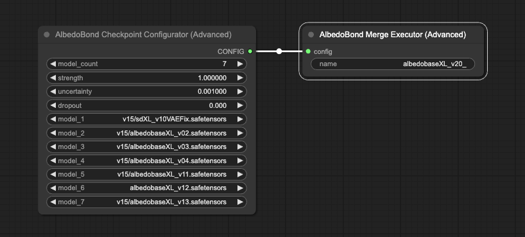
Ich habe ein benutzerdefiniertes Skript geschrieben, um die bestehenden AlbedoBase XL-Modelle zu einem Modell zusammenzuführen. Dabei werden die Reihen- und Spaltengewichte aller U-NET- und CLIP-Blöcke sorgfältig gemäß einer einzigartigen Formel von mir ausgerichtet.
Falls ein Fehler bei der Bildgenerierung auftritt (wenn nichts generiert wird), wechseln Sie bitte zu CLIP SKIP 2 oder ändern Sie den Prompt leicht! Es kann Kombinationen von Prompts geben, die von CLIP nicht erkannt werden. In diesem Fall können Sie die Wortreihenfolge ändern, unterschiedliche Wörter verwenden oder ganz einfach den CLIP SKIP ändern. Ich werde diese Probleme wie bei v1.3 nach und nach beheben.
Das Spec Grid (403,5 MB): herunterladen
v1.3
Um die Qualität im Zusammenhang mit der Zufälligkeit des Modells zu veranschaulichen, habe ich den Seed-Wert bei '9' für alle Showcase-Bilder festgelegt und diese sofort generiert.
Besonders mit dieser Version ist aufgrund der erheblichen Auswirkung negativer Prompts das leere Feld für negative Prompts wahrscheinlich für gute Qualität verantwortlich.
Das Spec Grid (438,7 MB): herunterladen

Wie Sie sehen können, wird die Verwendung von mehr Schritten für alle Sampler möglich, und die Qualität verbessert sich ebenfalls.
Aufgrund der Wirkung der von mir entwickelten und zusammengeführten LoRA, wie unten beschrieben, ist die Verwendung von Satzform-Prompts gegenüber Tag-Listen-Prompts direkt mit der Qualitätsverbesserung verbunden.
Ich habe 45 Checkpoints und 7 LoRAs zusammengeführt. Danach habe ich AlbedoBase v0.4 und v0.3 in der Reihenfolge um weniger als 0~5% zusammengeführt, um die verwässerten, veralteten zusammengeführten Modelle wiederzubeleben.
Einer der 7 LoRAs wurde von mir erstellt. Er analysiert und annotiert Beschreibungen für insgesamt 174 hochwertige Bildfotos mithilfe von GPT4-V. Durch die Zusammenführung dieses LoRA wurden erstaunlich klare Bilder und eine beeindruckend gute Auffassung der Prompts erreicht.
Meine selbst erstellten LoRAs sind ausschließlich für meine Ko-fi-Unterstützer auf dem Kreativ-Level oder höher verfügbar.
v1.2
22 neueste Checkpoints zusammengeführt.
Das Spec Grid (565,6 MB): herunterladen
v1.1
Stabilisiert.
Detaillierter.
Wenn Sie ein erfahrener Nutzer sind, empfehle ich Version 1.0. Wenn Version 1.0 die richtigen Einstellungen findet, kann sie viel lebendigere Werke ausgeben.
Das Spec Grid (349,7 MB): herunterladen
v1.0
106 LoRAs zusammengeführt.
19 Checkpoints zusammengeführt.
Das Modell kann je nach gewählten Einstellungen unterschiedliche Ergebnisse liefern, daher ist es wichtig, das Spec Grid vor der Nutzung zu prüfen.
Ich habe festgestellt, dass die Verwendung einiger spezifischer negativer Prompts helfen kann, Probleme mit asymmetrischen Augen oder verpixelten Bildern zu lösen. Das Spec Grid kann je nach CPU- oder GPU-Gerät variieren, daher verwenden Sie es bitte als allgemeinen Referenzwert. Experimentieren Sie mit einigen negativen Prompts, um die Qualität zu verbessern (z.B. Schielen). Ich stellte fest, dass es schwierig ist, alle Einstellungen gleichmäßig zufriedenzustellen, je mehr LoRAs zusammengeführt werden. Dennoch möchte ich, dass Sie sich auf diesen Vorteil in Version 1.0 konzentrieren, da mit den richtigen Einstellungen Werke von erstaunlicher Qualität in verschiedenen Aspekten entstehen können. Ich werde mit einer stabileren Version zurückkommen.
Nützliche Einstellwerte finden Sie in der Showcase oder durch die Suche bei anderen Nutzern.
Wie immer ist es am besten, das Feld für negative Prompts leer zu lassen für die besten Ergebnisse.
Diese Version 1.0 erforderte viel Arbeit, daher mache ich eine Pause. Ich hoffe, Sie genießen die Nutzung des Modells, und wenn Sie es zusammenführen, teilen Sie es bitte kostenlos auf Civitai. So können wir es alle weiter verbessern.
Das Spec Grid (479,4 MB): herunterladen
v0.4
132 LoRAs zusammengeführt.
4 Checkpoints zusammengeführt.
Das Spec Grid: herunterladen
v0.3
Verbessert in allen Samplern.
Lebensechter Realismus erreicht.
Stabilisiert.
Das Spec Grid: herunterladen
v0.2
Deutliche Verbesserungen in Klarheit und Detailgenauigkeit.
Verbesserte Umsetzung von Händen und Füßen.
Bedeutende ästhetische Verbesserungen; Komposition, Abstraktion, Fluss, Licht und Farbe usw.
v0.1
Nach passender Feinabstimmung am SDXL1.0-Modell sorgfältige und gezielte Zusammenführung von über 40 hochwertigen öffentlich auf Civitai verfügbaren Modellen.
Die Tests konzentrierten sich hauptsächlich darauf, maximale Qualität mit minimaler Anzahl von Prompt-Token sicherzustellen; es wurde nicht geprüft, wie sehr sich die Qualität bei Verwendung großer Token-Anzahlen verbessern kann. (Bitte führen Sie eigene Tests durch und teilen Sie die Ergebnisse)
Im Allgemeinen werden die schönsten Ergebnisse an der Schnittstelle zwischen Realität und Animation erzielt.
Dennoch gibt es bei Verwendung eines passenden Prompts grundsätzlich nichts, was das Modell nicht ausdrücken kann. (Ich behaupte, dass es als grundlegendes Modell, das andere in der Zusammenführung übertrifft, einen großen Wert besitzt. Allerdings beachten Sie bitte, dass dies aktuell v0.1 ist)

Modell-Details
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.
Modellsammlung - AlbedoBase XL

AlbedoBase XL - v2.1

AlbedoBase XL - v1.3

AlbedoBase XL - v3.1-Groß

AlbedoBase XL - v1.1

AlbedoBase XL - v2.0
Bilder von AlbedoBase XL - v2.0
Bilder mit 3D










Bilder mit all in one



Bilder mit Anime










Bilder mit Basismodell









